本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
并行化和分散-聚集模式
许多高级推理和生成任务(例如总结大型文档、评估多个解决方案路径或比较不同的视角)都受益于提示的并行执行。当需要可扩展性、响应能力和容错能力时,传统的顺序工作流程是不够的。为了克服这个问题,可以使用事件驱动的分散聚集模式重新构想基于 LLM 的并行化,在这种模式下,任务被动态分散给自主代理,然后智能地合成结果。
下图是 LLM 并行化工作流程的示例:
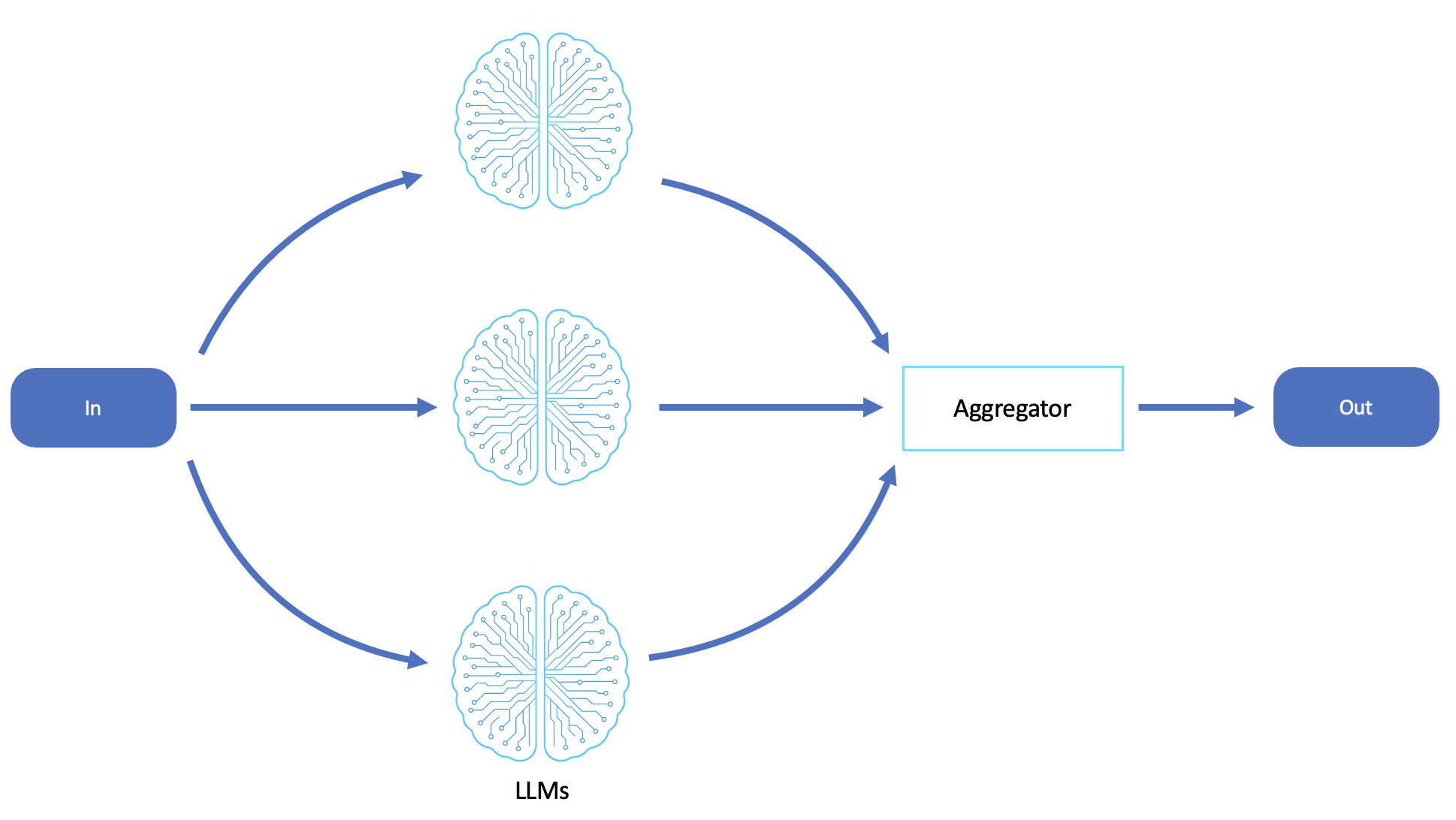
分散-收集
在分布式系统中,分散聚集模式将任务并行发送到多个服务或处理单元,等待它们的响应,然后将结果聚合到合并的输出中。与扇出不同,scatter-gather 是协调的,因为它期望得到响应,并且通常会应用逻辑来合并、比较和选择结果。
并行化和分散收集的常见实现包括以下几种:
-
AWS Step Functions 映射并行任务执行的状态
-
AWS Lambda 通过并发,协调来自多个调用函数的结果
-
Amazon EventBridge 提供关联 IDs 和聚合工作流程
-
使用亚马逊简单存储服务 (Amazon S3)、亚马逊 DynamoDB 或队列管理扇出和收集结果的自定义控制器模式
下图是分散聚集的示例:
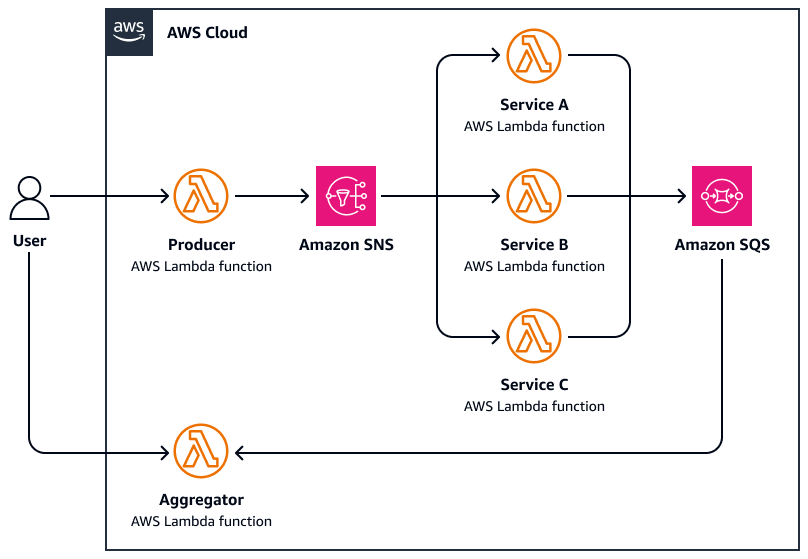
-
用户向中央协调器功能发送请求,该功能通过向亚马逊简单通知服务 (Amazon SNS) Simple Notification Service 主题发布并行消息来分散任务。
-
每条消息都包含任务元数据,并发送给专业工作人员 AWS Lambda。
-
每个工作人员都 AWS Lambda 独立处理其分配的子任务(例如,查询外部 API、处理文档和分析数据)。
-
结果会写入公共存储层,例如亚马逊简单队列服务 (Amazon SQS) Simple Queue Service。
-
聚合器函数等待所有响应完成,然后执行以下操作:
-
收集和汇总结果(例如,合并摘要、选择最佳匹配项)
-
发送最终响应或触发下游工作流程
-
分散聚集模式的常见用例包括:
-
联合搜索
-
价格比较引擎
-
汇总数据分析
-
多模型推理
基于 LLM 的并行化(分散-聚集认知)
在代理系统中,并行化通过在多个 LLM 调用或代理之间分配子任务来密切反映分散聚集,每个调用或代理独立推理问题的一部分。返回的结果由聚合过程收集和合成,聚合过程通常是另一个 LLM 或控制器代理。
代理并行化
-
代理提交了 “汇总这 10 份报告的见解” 请求。
-
它将报告分散到 10 个并行的 LLM 摘要任务中。
-
当它返回所有摘要时,代理会执行以下操作:
-
将摘要汇总成统一的简报
-
识别主题或矛盾
-
将合成后的输出发送给用户
-
这种代理工作流程支持可扩展、模块化和自适应的并行推理。这非常适合需要高认知吞吐量的用例。
下图是代理并行化的示例:
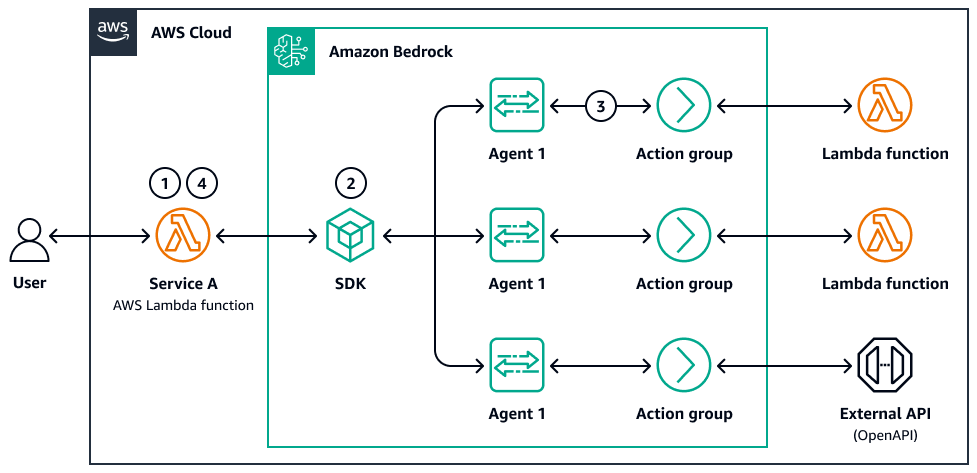
-
用户提交分段查询或文档集。
-
控制器 AWS Lambda 或步进函数分配子任务。每个任务都会使用自己的提示调用 Amazon Bedrock LLM 调用或子代理。
-
调用和子任务完成后,结果将被存储(例如,在 Amazon S3 或内存存储中),然后聚合步骤会合并、比较或筛选输出。
-
系统将最终响应返回给用户或下游代理。
该系统具有分布式推理循环,具有可追溯性、容错能力以及可选的结果加权或选择逻辑。
外卖
代理并行化使用分散聚集模式来分发 LLM 任务,从而实现并行处理和智能结果合成。
