本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
基本推理代理
基本推理代理是最简单的代理人工智能形式,它根据查询执行逻辑推理或决策。它接受用户或系统的输入,处理查询,并使用结构化提示生成响应。
这种模式对于需要根据给定上下文进行单步推理、分类或总结的任务很有用。它不使用内存、工具或状态管理,这使得它在大型工作流程中具有无状态、轻量级且高度可组合。
架构
基本推理代理的流程如下图所示:
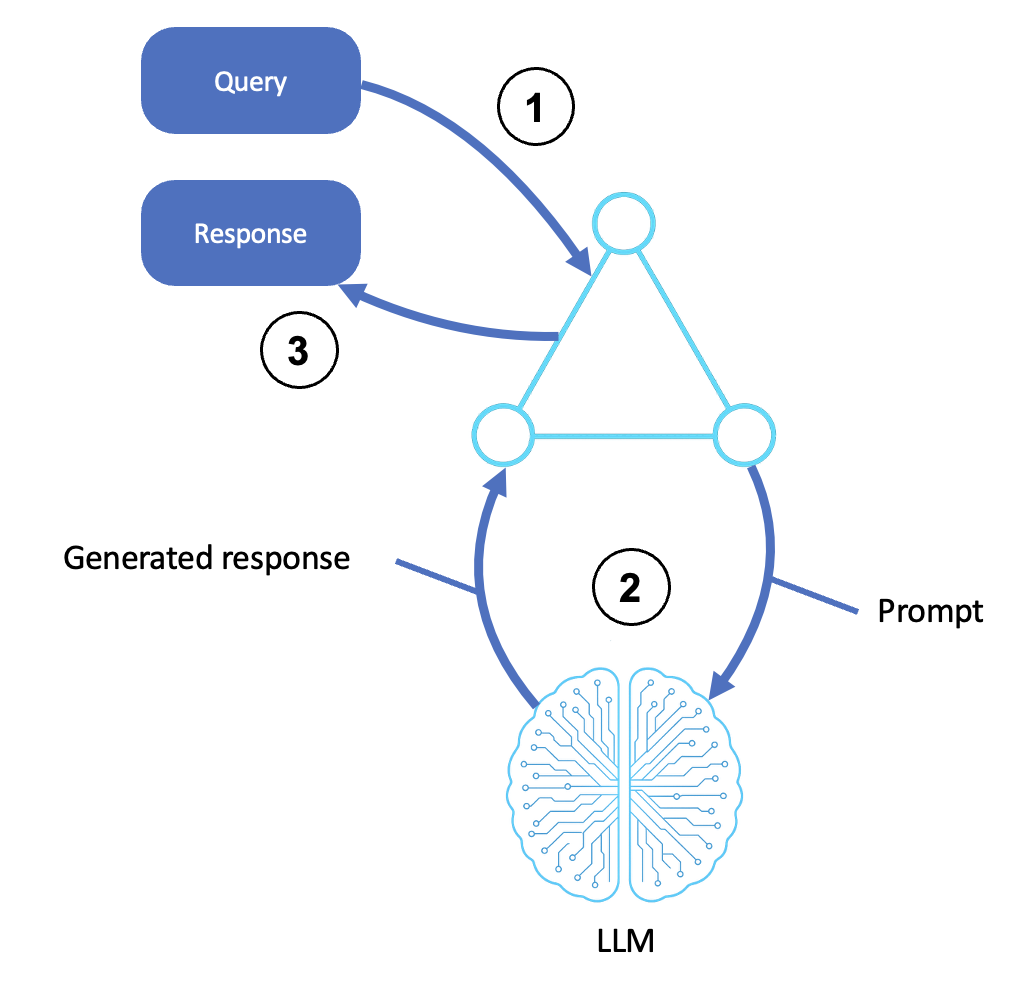
说明
-
接收输入
-
用户、系统或上游代理提交查询或指令。
-
输入将移交给代理 shell 或编排层。
-
此步骤包括任何预处理、提示模板和目标识别。
-
-
调用 LLM
-
代理将查询转换为结构化提示并将其发送给 LLM(例如,通过 Amazon Bedrock)。
-
LLM 使用预先训练的知识和上下文根据提示生成响应。
-
生成的输出可能包括推理步骤(思维链)、最终答案或排名选项。
-
-
返回响应
-
生成的输出将中继到代理的接口。
-
这可能包括格式化、后处理或 API 响应。
-
功能
-
支持自然语言或结构化输入
-
使用提示工程来指导行为
-
无状态且可扩展
-
可以嵌入到用户界面、CLI、API 和管道中
限制
-
没有记忆力或历史意识
-
不与外部工具或数据源交互
-
仅限于法学硕士在推理时所知道的情况
常见使用案例
-
对话问题和答案
-
政策解释和摘要
-
决策指南
-
轻量级且自动化的聊天机器人流程
-
分类、标签和评分
实施指导
您可以使用以下工具和服务来创建基本的推理代理:
-
用于调用 LLM 的 Amazon Bedrock(Anthropic、AI21、Meta)
-
Amazon API Gateway 或者 AWS Lambda 将其作为无状态微服务公开
-
提示模板存储在参数存储库中 AWS Secrets Manager,或存储为代码
Summary
由于其结构简单,基本的推理代理是基础性的。它具有核心功能,可以将目标转化为推理路径,从而实现智能输出。这种模式通常是高级模式的起点,例如基于工具的代理和使用检索增强生成 (RAG) 的代理。它也是大型工作流程的可靠模块化组件。
RAG 探员
Retrieval-augmented 生成 (RAG) 是一种将信息检索与文本生成相结合的技术,可创建准确的上下文相关响应。RAG使代理能够在聘请法学硕士之前检索相关的外部信息。它通过将最新、事实或特定领域的信息作为决策的基础,从而扩展代理的有效记忆力和推理准确性。与仅依赖预训练权重的无状态 LLM 形成鲜明对比的是,RAG 有一个外部知识搜索层,可以根据上下文动态增强提示。
架构
RAG 模式的逻辑如下图所示:
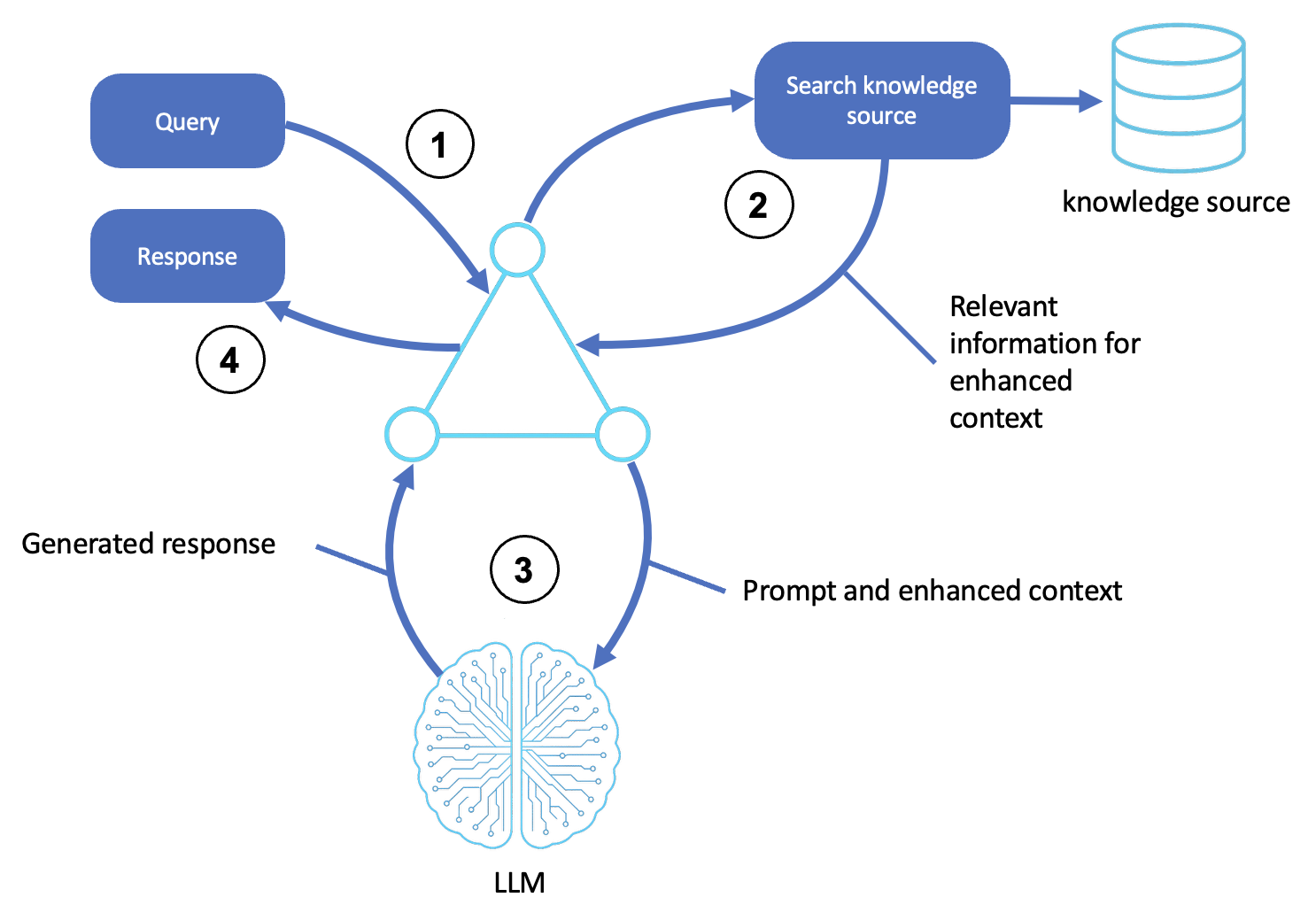
说明
-
收到查询
-
用户或上游系统向代理提交查询或目标。
-
代理 shell 接受请求并将其格式化为推理提示。
-
-
搜索外部来源
-
代理从查询中识别概念和意图。
-
它使用语义搜索或关键字匹配来查询知识源,例如矢量存储、数据库或文档索引。
-
检索最相关的段落、文档或实体,以便在下一步中使用。
-
-
生成上下文响应
-
代理使用检索到的信息对提示进行扩充,从而为 LLM 形成上下文增强输入。
-
法学硕士使用生成推理(例如思维链或反思)处理任何输入,以产生准确的响应。
-
-
返回最终输出
-
代理通过将输出封装在任何通信标头或所需格式中来准备输出,然后将其返回给用户或呼叫系统。
-
(可选)检索到的文档和 LLM 输出可能会被记录、评分并存储在内存中以备将来查询。
-
功能
-
Fact-grounded 即使在长尾域或企业特定域中也能输出
-
无需微调模型即可扩展内存
-
基于每个查询和用户状态的动态上下文
-
与矢量数据库、语义索引和元数据筛选完全兼容
常见使用案例
-
企业知识助手
-
监管合规机器人
-
客户支持副驾驶
-
Search-enhanced 聊天机器人
-
开发者文档代理
实施指导
使用以下工具和服务创建使用 RAG 的代理:
-
用于调用 LLM 的 Amazon Bedrock
-
用于文档或结构化数据搜索的 Amazon Kendra 或 Amazon Aurora OpenSearch
-
用于存储文档的亚马逊简单存储服务 (Amazon S3) Service
-
AWS Lambda 编排搜索、提示和 LLM 推理
-
Knowledge-based 与代理集成(通过使用内存插件、语义检索器或 Amazon Bedrock)
Summary
Agent RAG 将静态模型推理与动态的现实世界智能联系起来。它使代理能够查找他们不知道的内容,从检索到的知识中综合答案,并生成高度可信、可审计的响应。
RAG 模式是构建无需再培训即可扩展知识访问权限的智能代理的基础。它通常是更复杂的编排模式的前身,涉及工具使用、计划和长期记忆。
