本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
软件代理的核心构建块
下图显示了大多数智能代理中的关键功能模块。每个组件都有助于代理在复杂环境中自主运行。
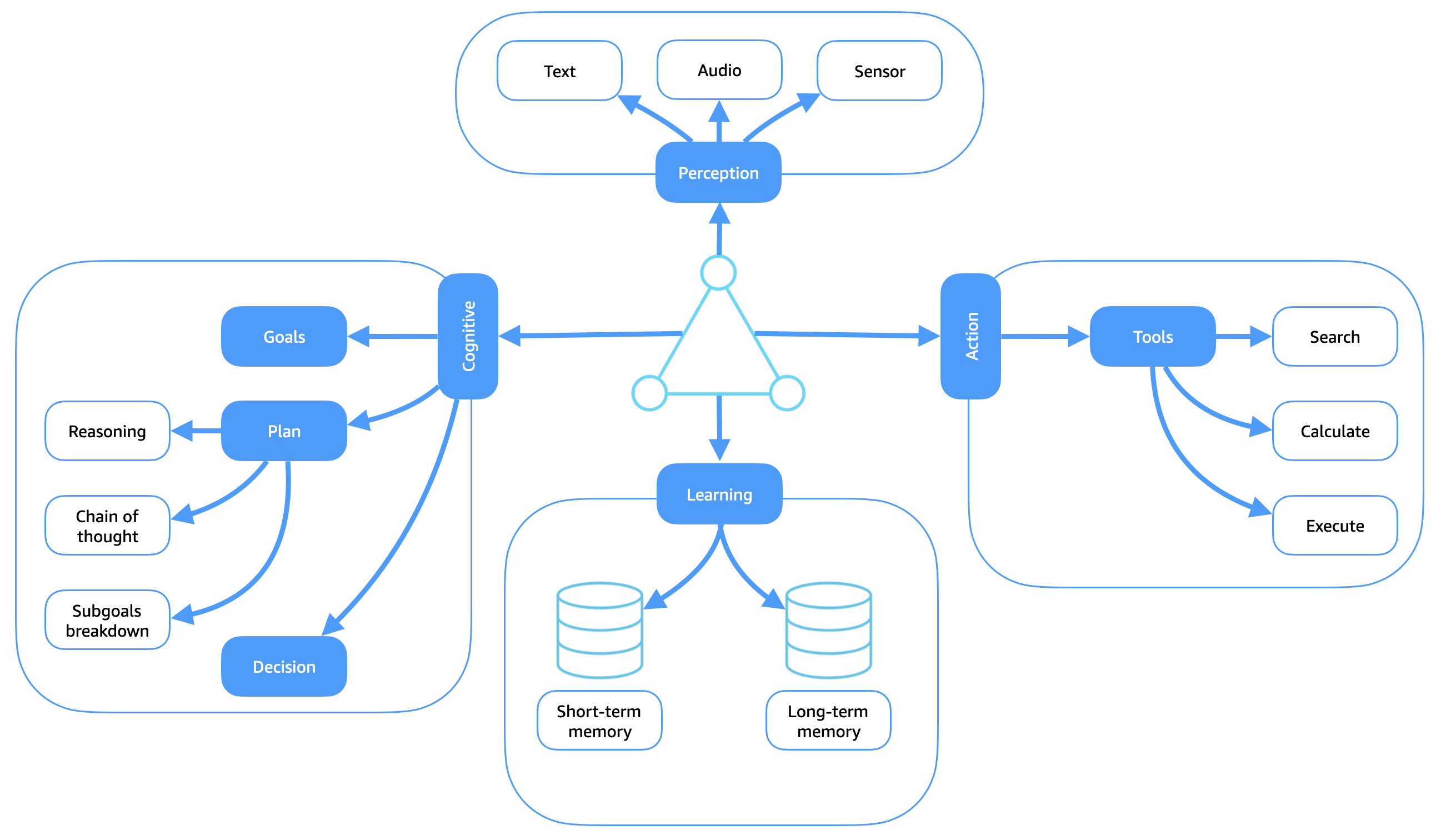
在感知、理性、行为循环的背景下,代理人的推理能力分布在其认知和学习模块中。通过记忆和学习的整合,代理可以根据过去的经验开发出适应性推理。当代理在其环境中行动时,它会形成一个紧急的反馈循环:每个动作都会影响未来的感知,由此产生的体验通过学习模块整合到记忆和内部模型中。这种持续的感知、推理和行动循环使代理人能够随着时间的推移而改善,并完成完整的感知、理性和行为周期。
感知模块
感知模块使代理能够通过文本、音频和传感器等多种输入模式与其环境进行交互。这些输入构成了所有推理和行动所依据的原始数据。文本输入可能包括自然语言提示、结构化命令或文档。音频输入包括语音指令或环境声音。传感器输入包括物理数据,例如视觉馈送、运动信号或 GPS 坐标。感知的核心功能是从这些原始数据中提取有意义的特征和表现形式。这使代理能够对其当前背景形成准确且可操作的理解。该过程可能涉及特征提取、物体或事件识别以及语义解释,是感知、理性、行为循环中关键的第一步。有效的感知可确保下游推理和决策建立在相关的、最新的态势感知基础上。
认知模块
认知模块是软件代理的深思熟虑的核心。它负责解释感知,形成意图,并通过以目标为导向的计划和决策来指导有目的的行为。该模块将输入转换为结构化推理过程,从而使代理能够有意而不是被动地操作。这些流程通过三个关键子模块进行管理:目标、计划和决策。
目标子模块
目标子模块定义了代理的意图和方向。目标可以是明确的(例如,“导航到某个地点” 或 “提交报告”),也可以是隐含的(例如,“最大限度地提高用户参与度” 或 “最大限度地减少延迟”)。它们是代理人推理周期的核心,为其计划和决策提供了目标状态。
代理人不断评估实现目标的进展情况,并可能根据新的认知或学习重新确定目标的优先顺序或重新制定目标。这种目标感知使代理能够适应动态环境。
规划子模块
规划子模块构造实现代理当前目标的策略。它生成操作序列,按层次分解任务,并从预定义或动态生成的计划中进行选择。
为了在不确定性或不断变化的环境中有效运作,规划不是一成不变的。现代代理可以生成思维链序列,引入子目标作为中间步骤,并在条件变化时实时修改计划。
该子模块与记忆和学习紧密相连,允许代理根据过去的结果随着时间的推移完善其计划。
Decision-making 子模块
决策子模块评估可用的计划和行动,以选择最合适的下一步行动。它整合了来自感知、当前计划、代理目标和环境背景的输入。
Decision-making 占用:
-
Trade-offs 在相互矛盾的目标之间
-
置信阈值(例如,感知的不确定性)
-
行动的后果
-
代理人学到的经验
根据架构的不同,代理可能会依靠符号推理、启发式方法、强化学习或语言模型 (LLM) 来做出明智的决策。此过程使代理的行为具有情境感知能力、目标一致性和适应性。
动作模块
操作模块负责执行代理的选定决策,并与外部世界或内部系统连接以产生有意义的效果。它代表了感知、理性、行为循环的行为阶段,在这个阶段,意图被转化为行为。
当认知模块选择动作时,动作模块通过专门的子模块协调执行,其中每个子模块都与代理的集成环境保持一致:
-
物理驱动:对于嵌入在机器人系统或物联网设备中的代理,该子模块将决策转化为现实世界的物理运动或硬件级别的指令。
示例:操纵机器人、触发阀门、打开传感器。
-
集成交互:此子模块处理非物理但外部可见的操作,例如与软件系统、平台或 API 交互。
示例:向云服务发送命令、更新数据库、通过调用 API 提交报告。
-
工具调用:代理通常通过使用专门的工具来扩展其能力,以完成以下子任务:
-
搜索:查询结构化或非结构化知识来源
-
摘要:将大型文本输入压缩为高级概览
-
计算:执行逻辑、数值或符号计算
工具调用通过模块化、可调用的技能实现复杂的行为组合。
-
学习模块
学习模块使代理能够根据经验随着时间的推移进行适应、概括和改进。它利用感知和行动的反馈不断完善代理的内部模型、策略和决策策略,从而为推理过程提供支持。
该模块与短期和长期记忆协调运行:
-
Short-term 内存:存储瞬态上下文,例如对话状态、当前任务信息和最近的观察结果。它可以帮助代理保持交互和任务的连续性。
-
Long-term 记忆:对过去经历中的持久知识进行编码,包括以前遇到的目标、行动结果和环境状态。 Long-term 内存使代理能够识别模式、重用策略并避免重复错误。
学习模式
学习模块支持一系列范式,例如监督学习、无监督学习和强化学习,它们支持不同的环境和代理角色:
-
监督学习:根据带标签的示例(通常来自人工反馈或训练数据集)更新内部模型。
示例:学习根据之前的对话对用户意图进行分类。
-
无监督学习:识别数据中的隐藏模式或结构,无需显式标签。
示例:对环境信号进行聚类以检测异常。
-
强化学习:通过在交互式环境中最大限度地提高累积奖励,通过反复试验优化行为。
示例:了解哪种策略可以最快地完成任务。
学习与代理人的认知模块紧密集成。它根据过去的结果完善规划策略,通过评估历史成功来加强决策,并不断改善感知与行动之间的映射。通过这种封闭的学习和反馈循环,代理从被动执行演变为能够随着时间的推移适应新的目标、条件和背景的自我完善系统。
