配置零 ETL 集成的目标
在配置零 ETL 集成的目标时,AWS Glue 提供了多种选项。目标可以是加密的 Amazon Redshift 数据仓库或 Amazon SageMaker 智能湖仓架构。
在选择零 ETL 集成的目标之前,您需要配置以下其中一个目标资源。零 ETL 集成中目标的配置选项包括:
使用 Amazon SageMaker 智能湖仓架构的常规 Amazon S3 存储桶。请参阅配置常规 S3 存储桶目标。
使用 Amazon SageMaker 智能湖仓架构的 Amazon S3 表类数据存储服务存储桶。请参阅配置 Amazon S3 表类数据存储服务目标。
使用 Amazon SageMaker 智能湖仓架构的 Amazon Redshift 托管式存储。请参阅配置 Amazon Redshift 托管式存储目标。
由 Redshift 命名空间标识的 Amazon Redshift 数据仓库。请参阅配置 Amazon Redshift 数据仓库目标。
注意
创建零 ETL 集成后,便无法修改其目标。
配置常规 S3 存储桶目标
本节介绍了在零 ETL 集成中使用 Amazon SageMaker 智能湖仓架构,将常规 Amazon S3 存储桶配置为目标存储的先决条件和设置步骤。
使用常规 S3 存储创建采用 Amazon SageMaker 智能湖仓架构的零 ETL 集成之前,需要完成以下设置任务:
设置 AWS Glue 数据库
提供 Catalog RBAC 策略
创建目标 IAM 角色
将目标角色、KMS(可选)和连接(可选)关联到目标资源
(可选)配置目标表属性
设置 AWS Glue 数据库
要使用 Amazon S3 常规存储桶位置在 Data Catalog 中设置目标数据库,请执行以下操作:
在 AWS Glue 控制台主页中,在 Data Catalog 下选择数据库。
选择右上角的添加数据库。如果您已经创建了数据库,请确保为数据库设置带有 Amazon S3 URI 的位置。
输入名称和位置 (Amazon S3 URI)。请注意,零 ETL 集成需要该位置。完成后,单击创建数据库。
注意
该常规 Amazon S3 存储桶必须与 AWS Glue 数据库位于同一区域。
有关在 AWS Glue 中创建新数据库的信息,请参阅开始使用 Data Catalog。
您还可以使用 create-database CLI 在 AWS Glue 中创建数据库。请注意,--database-input 中的 LocationUri 是必需的。
优化 Iceberg 表
一旦 AWS Glue 在目标数据库中创建了表,您就可以启用压缩来加快 Amazon Athena 中的查询速度。有关为资源(IAM 角色)设置压缩的信息,请参阅表优化的先决条件。
有关在集成创建的 AWS Glue 表上设置压缩的更多信息,请参阅优化 Iceberg 表。
提供目录基于资源的访问 (RBAC) 策略
对于使用 AWS Glue 数据库的集成,请将下面的权限添加到目录 RBAC 策略以允许源和目标之间的集成。
注意
对于跨账户集成,集成创建用户的角色策略和目录资源策略都需要在该资源上允许 glue:CreateInboundIntegration。对于同一账户,在资源上允许 glue:CreateInboundIntegration 的资源策略或角色策略就足够了。这两种情况仍然需要允许 glue.amazonaws.com 执行 glue:AuthorizeInboundIntegration。
可访问 Data Catalog 下的目录设置。然后提供下面的权限并填写缺失的信息。
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
创建目标 IAM 角色
创建具有以下权限和信任关系的目标 IAM 角色:
{ "Version": "2012-10-17", "Statement": [ { "Action": "s3:ListBucket", "Resource": "arn:aws:s3:::amzn-s3-bucket", "Effect": "Allow" }, { "Action": [ "s3:GetObject", "s3:PutObject", "s3:DeleteObject" ], "Resource": "arn:aws:s3:::amzn-s3-demo-bucket/prefix/*", "Effect": "Allow" }, { "Action": [ "glue:GetDatabase" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name" ], "Effect": "Allow" }, { "Action": [ "glue:CreateTable", "glue:GetTable", "glue:GetTables", "glue:DeleteTable", "glue:UpdateTable", "glue:GetTableVersion", "glue:GetTableVersions", "glue:GetResourcePolicy" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog", "arn:aws:glue:us-east-1:111122223333:database/database-name", "arn:aws:glue:us-east-1:111122223333:table/database-name/*" ], "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
添加下面的信任策略以允许 AWS Glue 服务代入该角色:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
将目标角色、KMS(可选)和连接(可选)关联到目标资源
将上述目标角色关联到目标资源(即 AWS Glue 数据库)。也可为目标 AWS Glue 数据库配置 KMS 和连接 ARN,前者用于在将数据存储到目标 Iceberg 表之前加密数据,后者用于访问该 S3 存储桶。这可让 AWS Glue 使用提供的角色访问目标 S3 位置上的数据,以及(可选)使用提供的 KMS 密钥对数据进行加密。如果将目标 S3 存储桶配置为可使用特定 VPC 进行访问,则可以关联该连接 ARN 以便 AWS Glue 在该 VPC 内运行处理。有关设置 VPC 的更多信息,请参阅创建 VPC。
也可使用 AWS Glue CLI/API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --target-processing-properties '{"RoleArn": "arn:aws:iam::123456789012:role/gmi_target_role"}' \ --region us-east-1
(可选)配置目标表属性
也可为要同步到目标的目标表配置目标表属性。
您可以在 AWS Glue 控制台中集成创建工作流的输出设置部分配置以下设置:

选择指定自定义分区键后,即可以配置分区键及其功能和转换规范:

如果源和目标位于同一个账户,则可以在 AWS Glue 控制台 UI 的集成创建工作流中完成此配置。但如果目标位于另一个账户中,则需要首先完成此配置,然后再创建集成。使用 CLI 或 API 时,即使源和目标都在同一账户中,也应在调用 Create-Integration API 之前完成此操作。AWS Glue 控制台 UI 仅封装了针对同一账户场景的此 API 调用。
如果未配置此属性,则同步表时将使用默认值。此配置还可以在创建集成后随时更改。
注意
如果在创建集成后更新此属性,但更新后的配置与现有配置冲突时,则可能会触发完整表重新同步。例如,将表“解嵌套”从“No-Unnest”更新为“Full-Unnest”,或者更改分区列。
使用 CLI 或 API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:database/database-name\ --table-nametable-name\ --target-table-config '{ "UnnestSpec":"TOPLEVEL"|"FULL"|"NOUNNEST", "PartitionSpec": [ { "FieldName":"string", "FunctionSpec":"string", "ConversionSpec":"string"} ... ], "TargetTableName":"string" }' \ --region us-east-1
为使用常规 Amazon S3 存储桶存储配置 Amazon SageMaker 智能湖仓架构后,就可以继续配置与目标的集成以完成集成设置。
配置 Amazon S3 表类数据存储服务目标
本节介绍了使用 Amazon SageMaker 智能湖仓架构,将 Amazon S3 表类数据存储服务配置为零 ETL 集成目标的先决条件和设置步骤。
在创建作为目标的 Amazon S3 表类数据存储服务的零 ETL 集成之前,需要完成以下设置任务:
设置 Amazon S3 表类数据存储服务存储桶(以及分析服务集成)
提供 Catalog RBAC 策略
创建目标 IAM 角色
将目标角色、KMS(可选)和连接(可选)关联到目标资源
(可选)配置目标表属性
设置 Amazon S3 表类数据存储服务存储桶(含分析服务集成)
按照开始使用 Amazon S3 表类数据存储服务中的说明,在您的账户中创建 S3 表类数据存储服务存储桶。
按照以下说明启用 Analytics 与 S3 表类数据存储服务存储桶的集成:AWS 服务与 Amazon S3 表类数据存储服务集成。
这将在 AWS Lake Formation 中创建一个新的 S3-Table 目录。
提供目录 RBAC 策略
必须向目录 RBAC 策略添加以下权限才能进行源和 Amazon S3 表类数据存储服务目录目标之间的集成。
目标 AWS Glue 目录资源策略需要包含执行 AuthorizeInboundIntegration 的 AWS Glue 服务权限。此外,创建集成的源主体或目标 AWS Glue 资源策略也需要包含 CreateInboundIntegration 权限。
注意
对于跨账户场景,源主体和目标 AWS Glue 目录资源策略都需要包含该资源的 glue:CreateInboundIntegration 权限。
{ "Version": "2012-10-17", "Statement": [ { "Principal": { "AWS": [ "arn:aws:iam::123456789012:user/Alice" ] }, "Effect": "Allow", "Action": [ "glue:CreateInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } }, { "Principal": { "Service": [ "glue.amazonaws.com" ] }, "Effect": "Allow", "Action": [ "glue:AuthorizeInboundIntegration" ], "Resource": [ "arn:aws:glue:us-east-1:111122223333:catalog/s3tablescatalog/*" ], "Condition": { "StringEquals": { "aws:SourceArn": "arn:aws:dynamodb:us-east-1:444455556666:table/table-name" } } } ] }
注意
将 s3tablescatalogs3tablescatalog。
创建目标 IAM 角色
创建具有以下权限和信任关系的目标 IAM 角色:
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3tables:ListTableBuckets", "s3tables:GetTableBucket", "s3tables:GetTableBucketEncryption", "s3tables:GetNamespace", "s3tables:CreateNamespace", "s3tables:ListNamespaces", "s3tables:CreateTable", "s3tables:DeleteTable", "s3tables:GetTable", "s3tables:GetTableEncryption", "s3tables:ListTables", "s3tables:GetTableMetadataLocation", "s3tables:UpdateTableMetadataLocation", "s3tables:GetTableData", "s3tables:PutTableData" ], "Resource": "arn:aws:s3tables:us-east-1:111122223333:bucket/s3-table-bucket", "Effect": "Allow" }, { "Action": [ "cloudwatch:PutMetricData" ], "Resource": "*", "Condition": { "StringEquals": { "cloudwatch:namespace": "AWS/Glue/ZeroETL" } }, "Effect": "Allow" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "*", "Effect": "Allow" } ] }
在目标 IAM 角色中添加以下信任策略,以允许 AWS Glue 服务代入该角色:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "glue.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
注意
确保 S3 表类数据存储服务存储桶资源策略中没有针对此目标 IAM 角色的显式拒绝声明。显式拒绝将覆盖任何“允许”权限并阻止集成正常运行。
将目标角色、KMS(可选)和连接(可选)关联到目标资源
将上述目标角色关联到目标资源。也可以配置 KMS 和连接 ARN,前者用于在将数据存储到目标 Iceberg 表之前加密数据,后者用于访问目标 S3 存储桶。如果将目标 S3 存储桶配置为可使用特定 VPC 进行访问,则可以关联该连接 ARN 以便 AWS Glue 在该 VPC 内运行处理。有关设置 VPC 的更多信息,请参阅创建 VPC。
使用 AWS Glue CLI/API:
aws glue create-integration-resource-property \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --target-processing-properties '{ "RoleArn": "arn:aws:iam::123456789012:role/target_role" }' \ --region us-east-1
(可选)配置目标表属性
也可为要同步到目标的目标表配置目标表属性。规则与常规 S3 目标部分所述相同。
使用 CLI 或 API:
aws glue create-integration-table-properties \ --resource-arn arn:aws:glue:us-east-1:123456789012:catalog/s3tablescatalog/S3 table bucket name\ --table-nametable-name\ --target-table-config '' \ --region us-east-1
使用 Amazon SageMaker 智能湖仓架构配置 Amazon S3 表类数据存储服务存储后,就可以继续配置与目标的集成以完成集成设置。
配置 Amazon Redshift 托管式存储目标
本节介绍了使用 Amazon SageMaker 智能湖仓架构,将 Amazon Redshift 托管式存储(RMS)配置为零 ETL 集成目标的先决条件和设置步骤。
使用 Redshift 托管式存储创建采用 Amazon SageMaker 智能湖仓架构的零 ETL 集成之前,需要完成以下设置任务:
设置 Amazon Redshift 集群或 Serverless 工作组
向 Lake Formation 注册 Amazon Redshift 集成
在 Lake Formation 中创建托管目录
配置 IAM 权限
设置 Amazon Redshift 托管存储
为零 ETL 集成设置 Amazon Redshift 托管式存储:
创建或使用现有的 Amazon Redshift 集群或 Serverless 工作组。要成功进行集成,务必确保目标 Amazon Redshift 工作组或集群启用
enable_case_sensitive_identifier参数。有关启用区分大小写的更多信息,请参阅《Amazon Redshift 管理指南》中的为您的数据仓库开启区分大小写。将 Redshift 的集成注册到 AWS Lake Formation 中的目录中。请参阅将 Amazon Redshift 集群和命名空间注册到 Data Catalog。
在 AWS Lake Formation 中创建联合目录或托管目录。有关更多信息,请参阅:
为目标角色配置 IAM 权限。该角色需要拥有权限才能同时访问 Redshift 和 Lake Formation 资源。该角色至少应具有:
访问 Redshift 集群或工作组的权限
访问 Lake Formation 目录的权限
在目录中创建和管理表的权限
CloudWatch 和 CloudWatch Logs 监控权限
使用 Amazon Redshift 托管式存储配置 Amazon SageMaker 智能湖仓目录后,就可以继续配置与目标的集成以完成集成设置。
配置 Amazon Redshift 数据仓库目标
本节介绍了将 Amazon Redshift 数据仓库配置为零 ETL 集成目标的先决条件和设置步骤。
在创建 Amazon Redshift 数据仓库目标的零 ETL 集成之前,需要完成以下设置任务:
设置 Amazon Redshift 集群或 Serverless 工作组
配置区分大小写
配置 IAM 权限
设置 Amazon Redshift 数据仓库
为零 ETL 集成设置 Amazon Redshift 数据仓库:
导航到Amazon Redshift控制台
,然后单击创建集群或使用现有的集群。要创建 Amazon Redshift 集群,请参阅创建集群。对于 Amazon Redshift Serverless 工作组,单击创建工作组。要创建 Amazon Redshift Serverless 工作组,请参阅创建带有命名空间的工作组。 如果要创建新的集群,请选择适当的集群大小,并确保集群已加密。对于 Serverless,请根据要求配置工作组设置。
要成功进行集成,务必确保目标 Amazon Redshift 工作组或集群启用
enable_case_sensitive_identifier参数。有关启用区分大小写的更多信息,请参阅《Amazon Redshift 管理指南》中的为您的数据仓库开启区分大小写。配置 IAM 权限以便进行零 ETL 集成,从而访问 Amazon Redshift 数据仓库。需要创建具有以下权限的 IAM 角色:
访问 Amazon Redshift 集群或工作组的权限
在 Amazon Redshift 中创建和管理数据库和表的权限
CloudWatch 和 CloudWatch Logs 监控权限
在 Amazon Redshift 工作组或集群设置完成后,您需要为零 ETL 集成配置数据仓库。有关更多信息,请参阅《Amazon Redshift 管理指南》中的开始使用零 ETL 集成。
注意
将 Amazon Redshift 数据仓库用作目标时,集成会在指定数据库中创建一个存储复制数据的架构。该架构的名称源自集成名称。
注意
要成功进行集成,目标 Amazon Redshift 工作组或集群必须启用 enable_case_sensitive_identifier 参数。
配置 Amazon Redshift 数据仓库后,就可以继续执行 配置与目标的集成 完成集成设置。
配置与目标的集成
配置源资源和目标资源后,请按照以下步骤完成集成设置:
导航到“零 ETL 集成”页面并启动集成创建工作流。
选择在之前步骤中配置的源资源。
选择或指定在之前步骤中配置的目标资源(同账户或跨账户)。
选择之前配置的目标 IAM 角色。
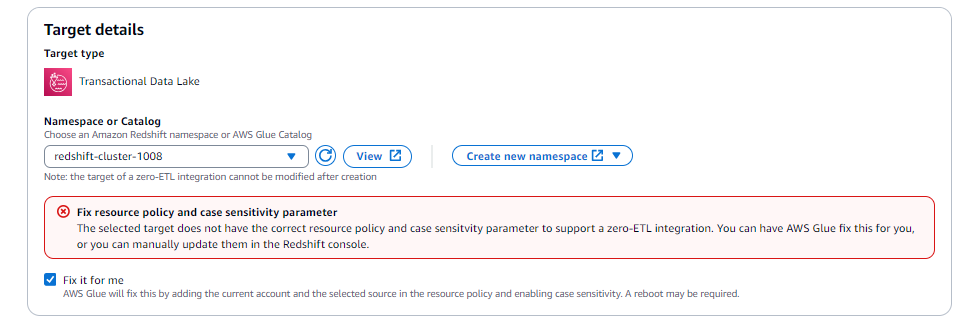
选择为我修复选项(仅在目标位于同一账户中时可用)。
对于常规 Amazon S3(AWS Glue 数据库)和 S3 表类数据存储服务(目录)目标,这将:
将授权服务主体应用于目标目录资源策略。
将授权 AWS Glue 源主体 ARN 应用于目标目录资源策略。
对于 Amazon Redshift 目标,这将:
在 Amazon Redshift 集群或 Serverless 工作组上应用授权的服务主体。
将授权的 AWS Glue 源 ARN 应用于 Amazon Redshift 集群或 Serverless 工作组。
将新的参数组与
enable_case_sensitive_identifier = true关联。
使用以下命令通过 API 或 CLI 创建集成:CreateIntegration API。
