支持 Spark DataFrame 的 DynamoDB 连接器
借助支持 Spark DataFrame 的 DynamoDB 连接器,您可以使用 Spark DataFrame API 在 DynamoDB 中读取和写入表。连接器的设置步骤与基于 DynamicFrame 的连接器的设置步骤相同,可以在此处找到。
要加载基于 DataFrame 的连接器库,请务必将 DynamoDB 连接附加到 Glue 作业。
注意
Glue 控制台 UI 目前不支持创建 DynamoDB 连接。可以使用 Glue CLI(CreateConnection)创建 DynamoDB 连接:
aws glue create-connection \ --connection-input '{ \ "Name": "my-dynamodb-connection", \ "ConnectionType": "DYNAMODB", \ "ConnectionProperties": {}, \ "ValidateCredentials": false, \ "ValidateForComputeEnvironments": ["SPARK"] \ }'
创建 DynamoDB 连接后,可以通过 CLI(CreateJob、UpdateJob)或直接在“作业详细信息”页面将其附加到您的 Glue 作业:
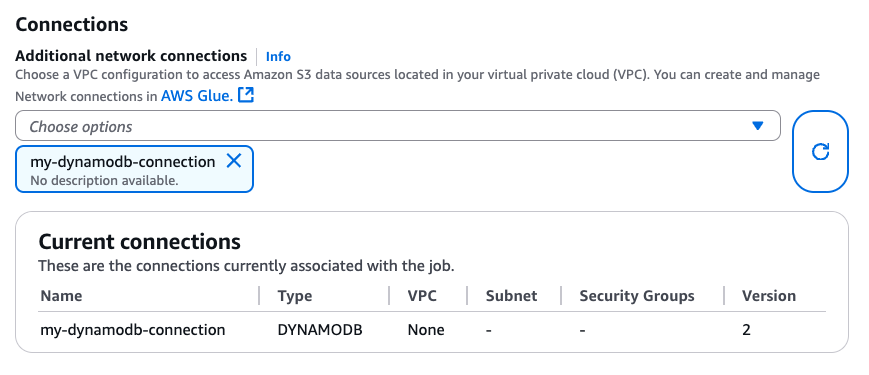
在确保与 DYNAMODB 类型的连接已附加到 Glue 作业后,可以从基于 DataFrame 的连接器使用以下读取、写入和导出操作。
使用基于 DataFrame 的连接器读取和写入 DynamoDB
以下代码示例演示了如何通过基于 DataFrame 的连接器读取和写入 DynamoDB 表。它们演示了如何从一个表读取数据并将数据写入其他表。
通过基于 DataFrame 的连接器使用 DynamoDB 导出
对于大于 80GB 的 DynamoDB 表大小,最好使用导出操作而不是读取操作。以下代码示例演示了如何通过基于 DataFrame 的连接器读取表、导出到 S3以及打印分区数量。
注意
DynamoDB 导出功能可以通过 Scala DynamoDBExport 对象使用。Python 用户可以通过 Spark 的 JVM 互操作进行访问,也可以将适用于 Python 的 Amazon SDK(Boto3)与 DynamoDB ExportTableToPointInTime API 一起使用。
配置选项
读取选项
| 选项 | 描述 | 默认 |
|---|---|---|
dynamodb.input.tableName |
DynamoDB 表名称(必填) | - |
dynamodb.throughput.read |
要使用的读取容量单位(RCU)。如果未指定,则使用 dynamodb.throughput.read.ratio 进行计算。 |
- |
dynamodb.throughput.read.ratio |
要使用的读取容量单位(RCU)的比率 | 0.5 |
dynamodb.table.read.capacity |
用于计算吞吐量的按需表的读取容量。此参数仅在按需容量表中有效。默认为温吞吐量读取单位。 | - |
dynamodb.splits |
定义在并行扫描操作中使用的分段数。如果未提供,连接器将计算出合理的默认值。 | - |
dynamodb.consistentRead |
是否使用强一致性读取 | FALSE |
dynamodb.input.retry |
定义出现可重试异常时我们执行的重试次数。 | 10 |
写入选项
| 选项 | 描述 | 默认 |
|---|---|---|
dynamodb.output.tableName |
DynamoDB 表名称(必填) | - |
dynamodb.throughput.write |
要使用的写入容量单位(WCU)。如果未指定,则使用 dynamodb.throughput.write.ratio 进行计算。 |
- |
dynamodb.throughput.write.ratio |
要使用的写入容量单位(WCU)的比率 | 0.5 |
dynamodb.table.write.capacity |
用于计算吞吐量的按需表的写入容量。此参数仅在按需容量表中有效。默认为温吞吐量写入单位。 | - |
dynamodb.item.size.check.enabled |
如果为 true,则在写入 DynamoDB 表之前,连接器会计算项目大小,如果大小超过最大大小,则会中止。 | TRUE |
dynamodb.output.retry |
定义出现可重试异常时我们执行的重试次数。 | 10 |
导出选项
| 选项 | 描述 | 默认 |
|---|---|---|
dynamodb.export |
如果设置为 ddb,将启用 AWS Glue DynamoDB 导出连接器,其中在 AWS Glue 作业期间将调用新的 ExportTableToPointInTimeRequet。新的导出将通过从 dynamodb.s3.bucket 和 dynamodb.s3.prefix 传递的位置生成。如果设置为 s3,将启用 AWS Glue DynamoDB 导出连接器,但会跳过创建新的 DynamoDB 导出,而使用 dynamodb.s3.bucket 和 dynamodb.s3.prefix 作为该表以前导出的 Amazon S3 位置。 |
ddb |
dynamodb.tableArn |
要从中读取数据的 DynamoDB 表。如果将 dynamodb.export 设置为 ddb,则是必需的。 |
|
dynamodb.simplifyDDBJson |
如果设置为 true,则执行转换,进而简化导出中存在的 DynamoDB JSON 结构的架构。 |
FALSE |
dynamodb.s3.bucket |
DynamoDB 导出期间用于存储临时数据的 S3 存储桶(必填) | |
dynamodb.s3.prefix |
DynamoDB 导出期间用于存储临时数据的 S3 前缀 | |
dynamodb.s3.bucketOwner |
指示跨账户 Amazon S3 访问所需的存储桶拥有者 | |
dynamodb.s3.sse.algorithm |
存储临时数据的存储桶上使用的加密类型。有效值为 AES256 和 KMS。 |
|
dynamodb.s3.sse.kmsKeyId |
用于加密存储临时数据的 S3 存储桶的 AWS KMS 托管式密钥的 ID(如果适用)。 | |
dynamodb.exportTime |
应进行导出的时间点。有效值:表示 ISO-8601 瞬时的字符串。 |
常规选项
| 选项 | 描述 | 默认 |
|---|---|---|
dynamodb.sts.roleArn |
用于跨账户访问的 IAM 角色 ARN | - |
dynamodb.sts.roleSessionName |
STS 会话名称 | glue-dynamodb-sts-session |
dynamodb.sts.region |
STS 客户端的区域(用于跨区域角色担任) | 与 region 选项相同 |
