本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用高级规则类型创建基于规则的匹配工作流
先决条件
在创建基于规则的匹配工作流程之前,您必须:
-
创建架构映射。有关更多信息,请参阅 创建架构映射。
-
如果使用 Connect 客户档案作为输出目标,请确保配置了相应的权限。
以下过程演示如何使用 AWS Entity Resolution 数据匹配服务 控制台或 API 创建具有高级规则类型的基于规则的匹配工作流。CreateMatchingWorkflow
- Console
-
使用创建基于规则的匹配工作流程 高级 使用控制台的规则类型
-
登录 AWS 管理控制台 并打开 AWS Entity Resolution 数据匹配服务 控制台,网址为https://console.aws.amazon.com/entityresolution/
。 -
在左侧导航窗格的 “工作流程” 下,选择 “匹配”。
-
在匹配工作流程页面的右上角,选择创建匹配工作流程。
-
对于 “步骤 1:指定匹配的工作流程详细信息”,请执行以下操作:
-
输入匹配的工作流程名称和可选的描述。
-
对于数据输入 AWS 区域,选择AWS Glue 数据库、AWS Glue 表,然后选择相应的架构映射。
您最多可以添加 19 个数据输入。
注意
要使用高级规则,您的架构映射必须满足以下要求:
-
除非字段组合在一起,否则每个输入字段都必须映射到唯一的匹配键。
-
如果将输入字段组合在一起,则它们可以共享相同的匹配键。
例如,以下架构映射对高级规则有效:
firstName: { matchKey: 'name', groupName: 'name' }lastName: { matchKey: 'name', groupName: 'name' }在这种情况下,
firstName和lastName字段组合在一起并共享相同的名称匹配密钥,这是允许的。检查您的架构映射并更新它们以遵循此一对一匹配规则,除非字段已正确分组,否则才能使用高级规则。
-
如果您的数据表有 DELETE 列,则架构映射的类型必须为,
String并且不能使用matchKey和groupName。
-
-
默认情况下,“标准化数据” 选项处于选中状态,以便在匹配之前对数据输入进行标准化。如果您不想对数据进行标准化处理,请取消选择 “标准化数据” 选项。
注意
创建架构映射中仅支持以下场景的标准化:
-
如果将以下 “名称” 子类型分组:名字、中间名、姓氏。
-
如果将以下地址子类型分组:街道地址 1、街道地址 2、街道地址 3、城市、州、国家、邮政编码。
-
如果将以下电话子类型分组:电话号码、电话国家/地区代码。
-
-
要指定服务访问权限,请选择一个选项并采取建议的操作。
Option 推荐操作 创建并使用新的服务角色 -
AWS Entity Resolution 数据匹配服务 使用此表所需的策略创建服务角色。
-
默认服务角色名称为
entityresolution-matching-workflow-<timestamp>。 -
您必须拥有创建角色并附加策略的权限。
-
如果您的输入数据已加密,则可以选择 “此数据使用 KMS 密钥加密” 选项,然后输入用于解密输入数据的密AWS KMS 钥。
使用现有服务角色 -
从下拉列表中选择一个现有服务角色名称。
如果您有列出角色的权限,则会显示角色列表。
如果您没有列出角色的权限,可以输入要使用的角色的 Amazon 资源名称 (ARN)。
如果没有现有的服务角色,则使用现有服务角色选项不可用。
-
通过选择在 IAM 中查看外部链接来查看服务角色。
默认情况下, AWS Entity Resolution 数据匹配服务 不会尝试更新现有角色策略以添加必要的权限。
-
-
(可选)要为资源启用标签,请选择添加新标签,然后输入密钥和值对。
-
选择下一步。
-
-
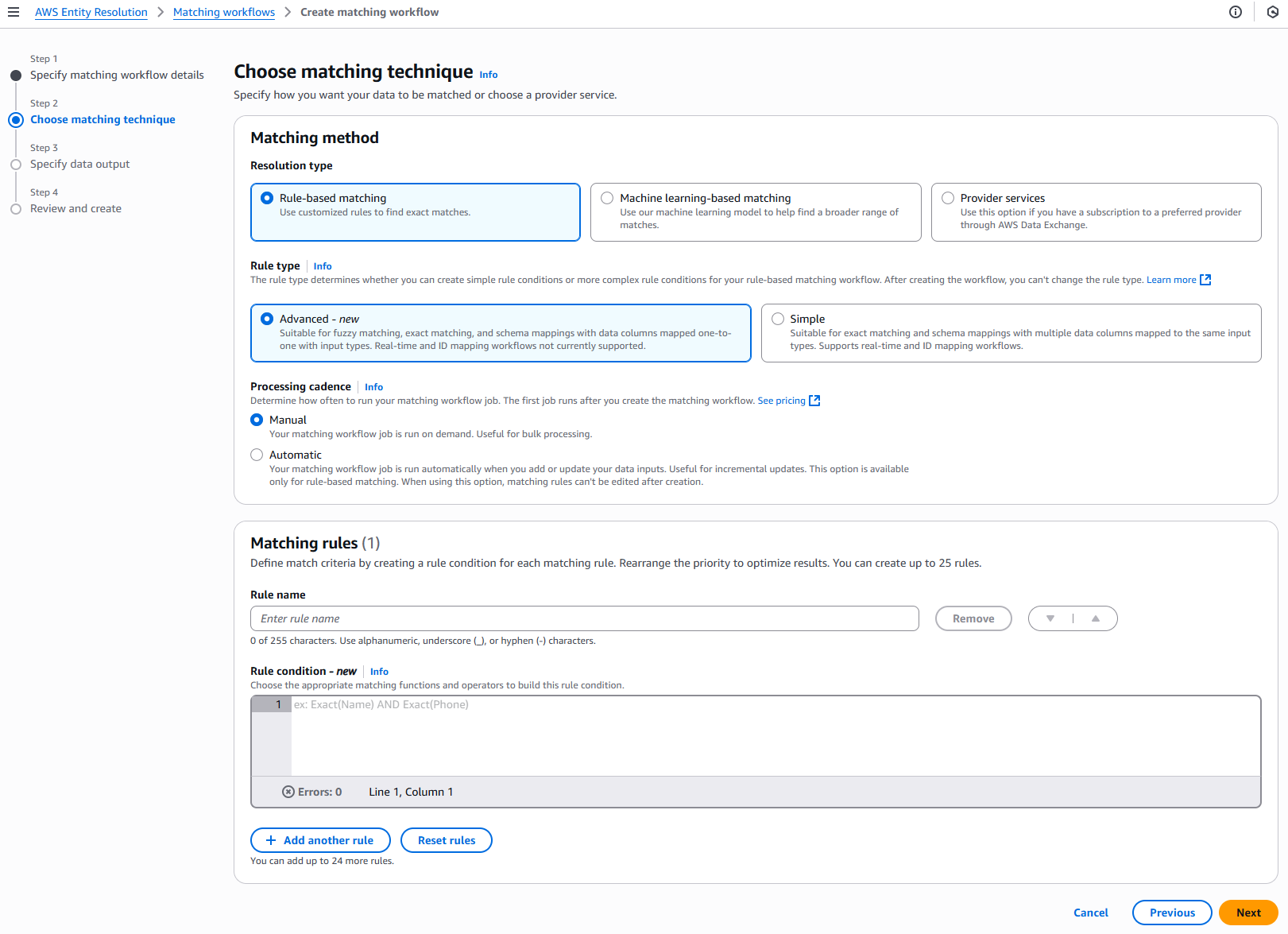
对于步骤 2:选择匹配技术:
-
在 “匹配方法” 中,选择Rule-based匹配。
-
对于 “规则类型”,选择 “高级”。
-
在 “处理节奏” 中,选择以下选项之一。
-
选择 “手动”,按需运行工作流以进行批量更新
-
选择 “自动” 以在 S3 存储桶中有新数据后立即运行工作流程
注意
如果您选择 “自动”,请确保您的 S3 存储桶已启用 Amazon EventBridge 通知。有关 EventBridge 使用 S3 控制台启用亚马逊的说明,请参阅 Amazon S3 用户指南 EventBridge中的启用亚马逊。
-
-
对于匹配规则,输入规则名称,然后根据您的目标从下拉列表中选择相应的匹配函数和运算符来构建规则条件。
您最多可以创建 25 条规则。
注意
必须使用 AND 运算符将模糊匹配函数(Cosine、Levenshtein 或 Soundex)与精确匹配函数(Exact、ExactManyToMany)组合在一起。
根据您的目标,您可以使用下表来帮助决定要使用哪种类型的函数或运算符。
您的目标 推荐的函数或运算符 推荐的可选修饰符 优点 在准确的数据上匹配相同的字符串,但在空值上不匹配。 精确 EmptyValues=进程 在准确的数据上匹配相同的字符串并忽略空值。 精确 ( matchKey)EmptyValues=忽略 在匹配键中匹配多条记录。适合灵活配对。限制:15 个匹配密钥 ExactManyToMany( matchKey,matchKey, ...)n/a 测量数据的数字表示形式之间的相似性,但在空值上不匹配。适用于文本、数字或两者的混合。 余弦 EmptyValues=进程 简单、高效。
与加 TF-IDF 权结合使用时,可以很好地处理长文本。
非常适合基于单词的精确匹配。
测量数据的数值表示之间的相似性并忽略空值。 余弦 ( matchKey,threshold,...)EmptyValues=忽略 很好地处理错别字、拼写错误和移位。
对各种 PII 类型有效。
适用于短字符串(例如,姓名或电话号码)。
计算将一个单词更改为另一个单词但与空值不匹配所需的最小更改次数。适用于拼写略有差异的文本。 莱文斯泰因 EmptyValues=进程 计算将一个单词更改为另一个单词并忽略空值所需的最小更改次数。 Levenshtein ( matchKey,,...threshold)EmptyValues=忽略 根据文本字符串的相似程度比较和匹配这些字符串,但在空值上却不匹配。适用于拼写或发音变化的文本。 Sounde EmptyValues=进程 有效进行语音匹配,识别发音相似的单词。
速度快且计算成本低。
适合匹配发音相似但拼写不同的名字。
根据文本字符串的相似程度对其进行比较和匹配,并忽略空值。 Soundex () matchKeyEmptyValues=忽略 组合函数。 AND n/a 单独的函数。 或者 n/a 对条件进行分组以创建嵌套条件。 (…) n/a 例与电话号码和电子邮件相匹配的规则条件
以下是匹配电话号码(电话匹配密钥)和电子邮件地址(电子邮件地址匹配密钥)记录的规则条件示例:
Exact(Phone,EmptyValues=Process) AND Levenshtein("Email address",2)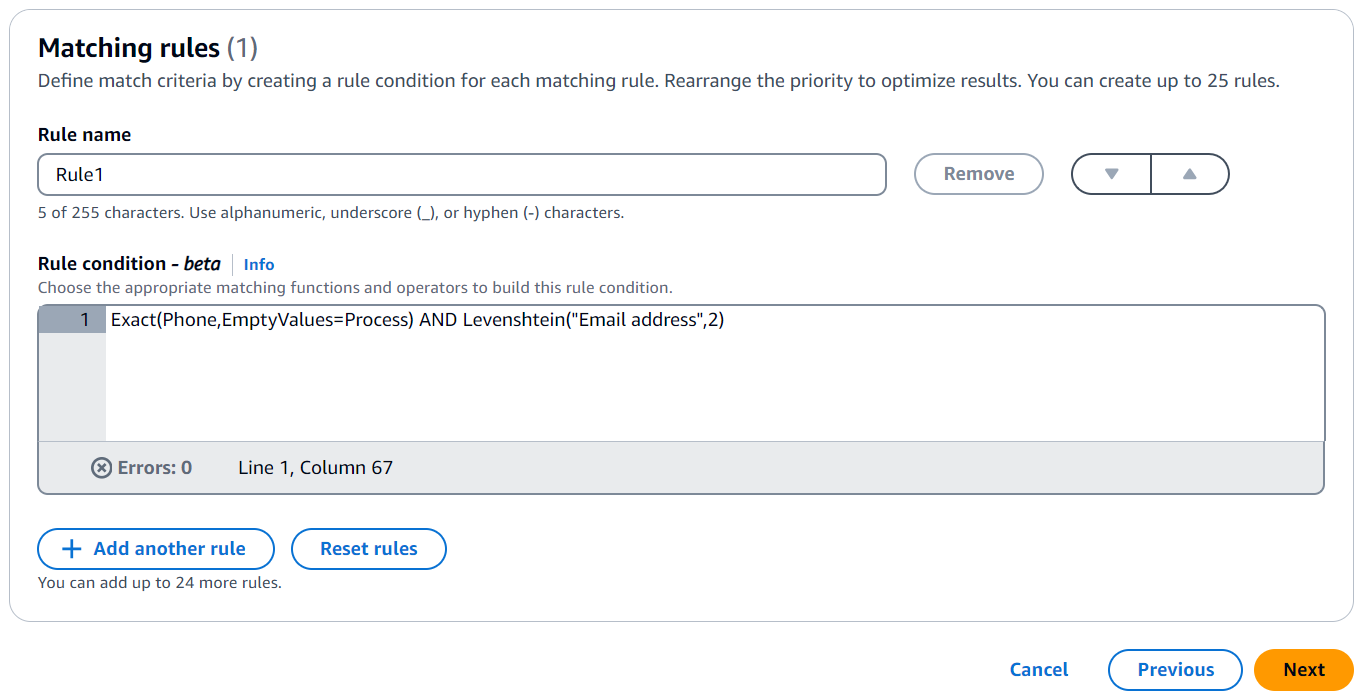
电话匹配键使用精确匹配功能来匹配相同的字符串。电话匹配键使用 EmptyValues=Process 修饰符处理匹配中的空值。
电子邮件地址匹配键使用 Levenshtein 匹配功能使用默认的 Levenshtein 距离算法阈值 2 来匹配拼写错误的数据。电子邮件匹配键不使用任何可选修饰符。
AND 运算符结合了精确匹配函数和 Levenshtein 匹配函数。
例用于执行火柴键匹配 ExactManyToMany 的规则条件
以下是一个规则条件示例,该规则条件用于匹配三个地址字段(HomeAddress匹配键、BillingAddress匹配键和ShippingAddress匹配键)上的记录,通过检查其中是否有相同值来查找潜在的匹配项。
ExactManyToMany运算符会评估指定地址字段的所有可能组合,以确定任意两个或多个地址之间的精确匹配项。例如,它将检测是否与或HomeAddress匹配ShippingAddress,BillingAddress或者所有三个地址是否完全匹配。ExactManyToMany(HomeAddress, BillingAddress, ShippingAddress)例使用聚类的规则条件
在具有模糊条件的基于规则的高级匹配中,系统首先根据精确匹配将记录分组为聚类。形成这些初始聚类后,系统会应用模糊匹配过滤器来识别每个聚类中的其他匹配项。为了获得最佳性能,您应该根据自己的数据模式选择精确匹配条件来创建定义明确的初始群集。
以下是将多个精确匹配与模糊匹配要求相结合的规则条件示例。它使用
AND运算符来检查三个字段 —FullName、出生日期 (DOB) 和Address— 在记录之间是否完全匹配。使用 Levenshtein 的距离,它还允许在InternalID场上进行细微的变化。1Levenshtein 距离测量将一个字符串更改为另一个字符串所需的最小单字符编辑次数。距离为 1 表示它将匹配仅InternalIDs相差一个字符(例如单个错字、删除或插入)。这种条件组合有助于识别极有可能代表同一实体的记录,即使标识符之间存在细微差异。Exact(FullName) AND Exact(DOB) AND Exact(Address) and Levenshtein(InternalID, 1) -
选择下一步。
-
-
对于步骤 3:指定数据输出和格式:
-
对于数据输出目标和格式,选择数据输出的 Amazon S3 位置,以及数据格式是标准化数据还是原始数据。
-
对于加密,如果您选择自定义加密设置,请输入AWS KMS 密钥 ARN。
-
查看系统生成的输出。
-
对于数据输出,请决定要包含、隐藏或掩盖哪些字段,然后根据目标采取建议的操作。
您的目标 推荐操作 包括字段 将输出状态保持为 “已包含”。 隐藏字段(从输出中排除) 选择 “输出” 字段,然后选择 “隐藏”。 掩码字段 选择 “输出” 字段,然后选择 “哈希输出”。 重置之前的设置 选择 重置。 -
选择下一步。
-
-
对于步骤 4:查看并创建:
-
查看您在之前的步骤中所做的选择,并在必要时进行编辑。
-
选择创建并运行。
将出现一条消息,表示匹配的工作流程已创建且作业已启动。
-
-
在匹配的工作流程详细信息页面的指标选项卡上,在 “上次作业指标” 下查看以下内容:
-
作业 ID。
-
匹配工作流作业的状态:已排队、进行中、已完成、失败
-
工作流作业的完成时间。
-
已处理的记录数。
-
未处理的记录数。
-
生成的唯一匹配 ID。
-
输入记录的数量。
您还可以查看任务历史记录下先前运行过的匹配工作流程作业的作业指标。
-
-
匹配的工作流程任务完成(状态为已完成)后,您可以转到数据输出选项卡,然后选择您的 Amazon S3 位置以查看结果。
-
(仅限手动处理类型)如果您创建了与 “手动” 处理类型的Rule-based 匹配工作流,则可以在匹配的工作流程详细信息页面上选择 “运行工作流”,随时运行匹配的工作流。
-
(仅限自动处理类型)如果您的数据表有 DELETE 列,则:
-
删除列
true中设置为的记录。 -
在 “删除” 列
false中设置为的记录将提取到 S3 中。
有关更多信息,请参阅 步骤 1:准备第一方数据表。
-
-
- API
-
使用创建基于规则的匹配工作流程 高级 使用 API 的规则类型
注意
默认情况下,工作流使用标准(批处理)处理。要使用增量(自动)处理,必须对其进行明确配置。
-
打开终端或命令提示符发出 API 请求。
-
向以下端点创建 POST 请求:
/matchingworkflows -
在请求标头中,将设置 Content-type 为 application/json。
注意
有关支持的编程语言的完整列表,请参阅 AWS Entity Resolution 数据匹配服务 API 参考。
-
对于请求正文,请提供以下必需的 JSON 参数:
{ "description": "string", "incrementalRunConfig": { "incrementalRunType": "string" }, "inputSourceConfig": [ { "applyNormalization":boolean, "inputSourceARN": "string", "schemaName": "string" } ], "outputSourceConfig": [ { "applyNormalization":boolean, "KMSArn": "string", "output": [ { "hashed": boolean, "name": "string" } ], "outputS3Path": "string" } ], "resolutionTechniques": { "providerProperties": { "intermediateSourceConfiguration": { "intermediateS3Path": "string" }, "providerConfiguration":JSON value, "providerServiceArn": "string" }, "resolutionType": "RULE_MATCHING", "ruleBasedProperties": { "attributeMatchingModel": "string", "matchPurpose": "string", "rules": [ { "matchingKeys": [ "string" ], "ruleName": "string" } ] }, "ruleConditionProperties": { "rules": [ { "condition": "string", "ruleName": "string" } ] } }, "roleArn": "string", "tags": { "string" : "string" }, "workflowName": "string其中:
-
workflowName(必填)— 必须是唯一的,并且必须介于 1—255 个字符之间,匹配模式 [a-z A-Z _0-9-] * -
inputSourceConfig(必填)— 1—20 个输入源配置列表 -
outputSourceConfig(必填)— 只有一个输出源配置 -
resolutionTechniques(必填)— 设置为 “RULE_MATCHING” 作为基于规则的匹配的分辨率类型 -
roleArn(必填)— 用于执行工作流程的 IAM 角色 ARN -
ruleConditionProperties(必填)-规则条件列表和匹配规则的名称。
可选参数包括:
-
description— 最多 255 个字符 -
incrementalRunConfig— 增量运行类型配置 -
tags— 最多 200 个键值对
-
-
(可选)要使用增量处理而不是默认的标准(批处理)处理,请在请求正文中添加以下参数:
"incrementalRunConfig": { "incrementalRunType": "AUTOMATIC" } -
发送 请求。
-
如果成功,您将收到状态码 200 的响应和包含以下内容的 JSON 正文:
{ "workflowArn": "string", "workflowName": "string", // Plus all configured workflow details } -
如果呼叫失败,您可能会收到以下错误之一:
-
400- ConflictException 如果工作流程名称已经存在
-
400 — ValidationException 如果输入未通过验证
-
402- ExceedsLimitException 如果超过账户限额
-
403 — AccessDeniedException 如果你没有足够的访问权限
-
429 — ThrottlingException 如果请求被限制
-
500 — InternalServerException 如果内部服务出现故障
-
-
