帮助改进此页面
要帮助改进本用户指南,请选择位于每个页面右侧窗格中的在 GitHub 上编辑此页面链接。
快速入门:在 Amazon EKS 上使用 vLLM 进行高吞吐量 LLM 推理
简介
本快速入门指南提供了使用 vlLM 和 GPU 在 Amazon EKS 上部署大语言模型(LLM)的演练,用于基于文本的实时推理应用程序。
该解决方案利用 Amazon EKS 进行容器编排,利用 vLLM 实现高效的模型服务,让您能够通过 GPU 加速和高吞吐量推理服务构建可扩展的 AI 应用程序。Llama 3.1 8B Instruct 模型用于演示,但您可以部署 vLLM 支持的任何其他 LLM(有关支持的模型列表,请查看 vLLM 文档
EKS 上的 vlLM 架构

完成此过程后,您将拥有针对吞吐量和低延迟进行了优化的 vLLM 推理端点,并且将能够通过聊天前端应用程序与 Llama 模型进行交互,从而演示聊天机器人助手和其他基于 LLM 的应用程序的典型使用案例。
如需其他指导和高级部署资源,请查看EKS AI/ML 工作负载最佳实践指南以及生产就绪型 EKS 推理图表上的 AI
开始前的准备工作
在开始之前,请确保您满足以下条件:
-
具有包含以下主要组件的 Amazon EKS 集群:带有 G5 或 G6 EC2 实例系列的 Karpenter 节点池、在支持 GPU 的 Worker 节点上安装的 NVIDIA 设备插件,以及安装的 S3 Mountpoint CSI 驱动程序。要创建此基线设置,请按照 Amazon EKS 上实时推理的最佳实践集群设置指南中的步骤操作,直至完成步骤 4。
-
一个 Hugging Face 账户。要注册账户,请参阅 https://huggingface.co/login。
使用 Amazon S3 设置模型存储
在 Amazon S3 中高效存储大型 LLM 文件,以便将存储与计算资源分开。此方法可简化模型更新和生产设置中的管理,并降低成本。S3 可以可靠地处理海量文件,而通过 Mountpoint CSI 驱动程序与 Kubernetes 集成,让容器组(pod)可以访问本地存储等模型,无需在启动期间进行耗时的下载。按照以下步骤创建 S3 存储桶、上传 LLM 并将其作为卷挂载到推理服务容器中。
EKS 上还提供用于模型缓存的其他存储解决方案,例如适用于 Lustre 的 EFS 和 FSx。有关更多信息,请查看 EKS 最佳实践。
设置环境变量
为新 Amazon S3 存储桶创建唯一名称,我们将在本指南稍后部分创建该名称。创建后,在所有步骤中使用这一相同的存储桶名称。例如:
MY_BUCKET_NAME=model-store-$(date +%s)
定义环境变量并将其存储在文件中:
cat << EOF > .env-quickstart-vllm export BUCKET_NAME=${MY_BUCKET_NAME} export AWS_REGION=us-east-1 export AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text) EOF
在 Shell 环境中加载环境变量。如果关闭当前的 Shell 环境并打开新的 Shell 环境,请确保使用相同的命令重新获取环境变量:
source .env-quickstart-vllm
创建 S3 存储桶以存储模型文件
创建 S3 存储桶以存储模型文件:
aws s3 mb s3://${BUCKET_NAME} --region ${AWS_REGION}
从 Hugging Face 下载模型
Hugging Face 是访问 LLM 模型的主要模型中心之一。要下载 Llama 模型,您需要接受模型许可并设置令牌身份验证:
-
接受 Llama 3.1 8B Instruct 模型许可,网址为 https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct。
-
生成访问令牌(转到“个人资料”>“设置”>“访问令牌”,然后使用“读取令牌”类型创建新令牌)。
使用 Hugging Face 令牌设置环境变量:
export HF_TOKEN=your_token_here
如果环境中尚未安装 pip3 软件包,请安装。Amazon Linux 2023 中的示例命令:
sudo dnf install -y python3-pip
安装 Hugging Face CLI
pip install huggingface-hub
使用 --exclude 标志从 Hugging Face 下载 Llama-3.1-8B-Instruct 模型(约 15 GB),跳过旧版 PyTorch 格式,仅下载经过优化的 Safetensors 格式文件,这样可以减少下载大小,同时保持与常用推理引擎完全兼容:
huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct \ --exclude "original/*" \ --local-dir ./llama-3.1-8b-instruct \ --token $HF_TOKEN
验证下载文件:
$ ls llama-3.1-8b-instruct
预期输出应如下所示:
LICENSE config.json model-00002-of-00004.safetensors model.safetensors.index.json tokenizer_config.json README.md generation_config.json model-00003-of-00004.safetensors special_tokens_map.json USE_POLICY.md model-00001-of-00004.safetensors model-00004-of-00004.safetensors tokenizer.json
上传模型文件
启用 AWS 通用运行时(CRT)以提高 S3 传输性能。基于 CRT 的传输客户端为大型文件操作提供了更高的吞吐量和可靠性:
aws configure set s3.preferred_transfer_client crt
上传模型:
aws s3 cp ./llama-3.1-8b-instruct s3://$BUCKET_NAME/llama-3.1-8b-instruct \ --recursive
预期输出应如下所示:
... upload: llama-3.1-8b-instruct/tokenizer.json to s3://model-store-1753EXAMPLE/llama-3.1-8b-instruct/tokenizer.json upload: llama-3.1-8b-instruct/model-00004-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00004-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00002-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00002-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00003-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00003-of-00004.safetensors upload: llama-3.1-8b-instruct/model-00001-of-00004.safetensors to s3://model-store-1753890326/llama-3.1-8b-instruct/model-00001-of-00004.safetensors
设置 S3 Mountpoint CSI 权限
S3 Mountpoint CSI 驱动程序支持 Kubernetes 与 S3 之间的原生集成,让容器组(pod)可以像本地存储一样直接访问模型文件,从而无需在容器启动期间使用本地副本。
创建 IAM 策略以允许 S3 挂载点从 S3 存储桶读取:
aws iam create-policy \ --policy-name S3BucketAccess-${BUCKET_NAME} \ --policy-document "{\"Version\": \"2012-10-17\", \"Statement\": [{\"Effect\": \"Allow\", \"Action\": [\"s3:GetObject\", \"s3:GetObjectVersion\", \"s3:ListBucket\", \"s3:GetBucketLocation\"], \"Resource\": [\"arn:aws:s3:::${BUCKET_NAME}\", \"arn:aws:s3:::${BUCKET_NAME}/*\"]}]}"
查看 S3 CSI 驱动程序服务账户注释,找到 S3 Mountpoint CSI 驱动程序使用的 IAM 角色名称:
ROLE_NAME=$(kubectl get serviceaccount s3-csi-driver-sa -n kube-system -o jsonpath='{.metadata.annotations.eks\.amazonaws\.com/role-arn}' | cut -d'/' -f2)
将您的 IAM 策略附加至 S3 Mountpoint CSI 角色:
aws iam attach-role-policy \ --role-name ${ROLE_NAME} \ --policy-arn arn:aws:iam::${AWS_ACCOUNT_ID}:policy/S3BucketAccess-${BUCKET_NAME}
如果集群中未安装 S3 Mountpoint CSI,请按照 Amazon EKS 上实时推理的最佳实践集群设置指南中的部署步骤进行操作。
将 S3 存储桶挂载为 Kubernetes 卷
创建持久卷(PV)和持久卷声明(PVC),以提供跨多个推理容器组(pod)对 S3 存储桶的只读访问权限。ReadOnlyMany 访问模式可确保并行访问模型文件,而 CSI 驱动程序可处理 S3 存储桶的挂载:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: model-store spec: storageClassName: "" capacity: storage: 100Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain mountOptions: - region ${AWS_REGION} csi: driver: s3.csi.aws.com volumeHandle: model-store volumeAttributes: bucketName: ${BUCKET_NAME} --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: model-store spec: storageClassName: "" volumeName: model-store accessModes: - ReadOnlyMany resources: requests: storage: 100Gi EOF
GPU 基础设施设置
集群节点
我们正在使用 Amazon EKS 上实时推理的最佳实践集群设置指南中创建的 EKS 集群。此集群包括 Karpenter 节点池,这些节点池可以为支持 GPU 的节点预调配足够的节点存储空间来下载 vLLM 容器映像。如果使用自定义 EKS 集群,请确保它可以启动支持 GPU 的节点。
实例选择
正确选择用于 LLM 推理的实例,需要确保可用的 GPU 内存足以加载模型权重。Llama 3.1 8B Instruct 的模型权重约为 16 GB(模型文件 .safetensor 的大小),因此我们需要向 vllm 进程提供至少此数量的内存来加载模型。
搭载 A10G GPU 的 Amazon G5 EC2 实例
NVIDIA 设备驱动程序
NVIDIA 驱动程序为容器提供了高效访问 GPU 资源所需的运行时环境。该驱动程序支持在 Kubernetes 内分配和管理 GPU 资源,使 GPU 可以作为可调度资源使用。
我们的集群使用 EKS Bottlerocket AMI,其中包括所有支持 GPU 的节点上所有必要的 NVIDIA 设备驱动程序和插件,确保容器化工作负载无需额外设置即可立即访问 GPU。如果您使用的是其他类型的 EKS 节点,则需要确保已安装所有必要的驱动程序和插件。
测试 GPU 基础设施
通过执行以下步骤来测试集群的 GPU 功能,确保容器组(pod)可以访问 NVIDIA GPU 资源并在支持 GPU 的节点上正确调度。
部署 Nvidia SMI 测试容器组(pod):
cat <<EOF | envsubst | kubectl apply -f - apiVersion: v1 kind: Pod metadata: name: gpu-nvidia-smi-test spec: restartPolicy: OnFailure tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker # Matches GPU NodePool's label containers: - name: cuda-container image: nvidia/cuda:12.9.1-base-ubuntu20.04 command: ["nvidia-smi"] resources: requests: memory: "24Gi" limits: nvidia.com/gpu: 1 EOF
查看容器组(pod)日志以检查是否列出了 GPU 详细信息,类似于以下输出(不一定是相同的 GPU 模型):
$ kubectl wait --for=jsonpath='{.status.phase}'=Succeeded pod/gpu-nvidia-smi-test $ kubectl logs gpu-nvidia-smi-test
Wed Jul 30 15:39:58 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 570.172.08 Driver Version: 570.172.08 CUDA Version: 12.9 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10G On | 00000000:00:1E.0 Off | 0 | | 0% 30C P8 9W / 300W | 0MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
此输出显示容器组(pod)可以成功访问 GPU 资源。
重要提示:此容器组(pod)使用与 Amazon EKS 上实时推理的最佳实践集群设置指南中的 Karpenter 节点池一致的 nodeSelector 配置。如果您使用不同的节点池,请确保容器组(pod)与 nodeSelector 和 Tolerations 相匹配。
部署推理容器
服务堆栈决定了推理基础设施的性能和可扩展性。vLLM 已成为生产部署的领先解决方案。vLLM 的架构可为动态请求处理提供持续批处理、实现内核优化以加快推理,以及通过 PageDattention 进行高效的 GPU 内存管理。这些功能,再加上生产就绪的 REST API 和对常用模型格式的支持,使其成为高性能推理部署的最佳选择。
选择 AWS 深度学习容器映像
AWS 深度学习容器
在此部署中,我们将使用适用于 vlLM 0.9 的 AWS DLC,其中包括 Nvidia 库和经优化的 GPU 性能配置,这些配置专门针对 AWS GPU 实例上的转换器模型推理进行了调整。
image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2
应用 vlLM Kubernetes 清单
在 EKS 中部署 vLMM 有多种方法。本指南演示了使用 Kubernetes 部署进行的 vLLM 部署,这是一种 Kubernetes 原生且易于入门的方法。有关高级部署选项,请参阅 vLLM 文档
通过 Kubernetes 清单定义部署参数,以控制资源分配、节点放置、运行状况探测、服务公开等。使用适用于 vlLM 的 AWS 深度学习容器映像,将您的部署配置为运行支持 GPU 的容器组(pod)。为 LLM 推理设置优化参数,并通过 AWS 负载均衡器服务公开兼容 vlLM OpenAPI 的端点:
cat <<EOF | envsubst | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: vllm-inference-app spec: replicas: 1 selector: matchLabels: app: vllm-inference-app template: metadata: labels: app: vllm-inference-app spec: tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" nodeSelector: role: gpu-worker containers: - name: vllm-inference image: 763104351884.dkr.ecr.us-east-1.amazonaws.com/vllm:0.9-gpu-py312-ec2 ports: - containerPort: 8000 env: - name: MODEL_PATH value: "/mnt/models/llama-3.1-8b-instruct" args: - "--model=/mnt/models/llama-3.1-8b-instruct" - "--host=0.0.0.0" - "--port=8000" - "--tensor-parallel-size=1" - "--gpu-memory-utilization=0.9" - "--max-model-len=8192" - "--max-num-seqs=1" readinessProbe: httpGet: path: /health port: 8000 initialDelaySeconds: 30 periodSeconds: 5 timeoutSeconds: 10 resources: limits: nvidia.com/gpu: 1 requests: memory: "24Gi" cpu: "4" ephemeral-storage: "25Gi" # Ensure enough node storage for vLLM container image volumeMounts: - name: models mountPath: /mnt/models readOnly: true volumes: - name: models persistentVolumeClaim: claimName: model-store --- apiVersion: v1 kind: Service metadata: name: vllm-inference-svc annotations: service.beta.kubernetes.io/aws-load-balancer-type: nlb service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing spec: type: LoadBalancer ports: - port: 80 targetPort: 8000 protocol: TCP selector: app: vllm-inference-app EOF
检查 vlLM 容器组(pod)是否处于 Ready 1/1 状态:
kubectl get pod -l app=vllm-inference-app -w
预期输出:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
提取容器映像并且 vLLM 将模型文件加载到 GPU 内存中可能需要几分钟时间。仅当容器组(pod)处于“就绪且可用”时才继续。
公开服务
通过 Kubernetes 端口转发在本地公开推理端点,用于本地开发和测试。让此命令在单独的终端窗口中运行:
export POD_NAME=$(kubectl get pod -l app=vllm-inference-app -o jsonpath='{.items[0].metadata.name}') kubectl port-forward pod/$POD_NAME 8000:8000
AWS 负载均衡器控制器会自动创建向外部公开 vLM 服务端点的网络负载均衡器。通过运行以下命令获取 NLB 端点:
NLB=$(kubectl get service vllm-inference-svc -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
是否需要安装 AWS 负载均衡器控制器? 按照使用 AWS 负载均衡器控制器路由互联网流量中的部署步骤进行操作。
运行推理
验证推理容器组(pod)
通过转发的端口在本地验证推理容器功能。发送连接请求并确保响应中包含 HTTP 代码 200:
$ curl -IX GET "http://localhost:8000/v1/models"
HTTP/1.1 200 OK date: Mon, 13 Oct 2025 23:24:57 GMT server: uvicorn content-length: 516 content-type: application/json
通过 NLB 端点向 LLM 发送完成请求,测试推理功能并验证外部连接:
curl -X POST "http://$NLB:80/v1/completions" \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/models/llama-3.1-8b-instruct", "prompt": "Explain artificial intelligence:", "max_tokens": 512, "temperature": 0.7 }'
此端点遵循 OpenAI API 格式,使其与现有应用程序兼容,同时提供可配置的生成参数(例如响应长度和温度),以控制输出多样性。
运行聊天机器人应用程序
为了进行演示,本指南使用 nextjs-vllm-ui
将聊天机器人用户界面作为 Docker 容器运行,该容器可将端口 3000 映射到本地主机并连接至 vlLM NLB 端点:
docker run --rm \ -p 3000:3000 \ -e VLLM_URL="http://${NLB}:80" \ --name nextjs-vllm-ui-demo \ ghcr.io/yoziru/nextjs-vllm-ui:latest
打开 Web 浏览器并导航至:http://localhost:3000/
您应该会看到聊天界面,您可以在其中与 Llama 模型互动。
聊天用户界面

优化推理性能
像 vLLM 这样的专业推理引擎提供了可显著提高推理性能的高级功能,包括连续批处理、高效的 KV 缓存和经优化的记忆注意力机制。您可以调整 vLLM 配置参数以提高推理性能,同时满足特定使用案例要求和工作负载模式。正确的配置对于实现 GPU 饱和度至关重要,从而确保您从昂贵的 GPU 资源中获取最大价值,同时提供高吞吐量、低延迟和具有成本效益的操作。以下优化有助于您最大限度地提高 vlLM 部署在 EKS 上的性能。
对 vLLM 配置进行基准测试
要针对使用案例调整 vLLM 配置参数,请使用 GuideLLM
基线 vLLM 配置
这是用于运行 vlLM 的基线配置:
| vlLM 参数 | 说明 |
|---|---|
|
tensor_parallel_size:1 |
在 1 个 GPU 上分配模型 |
|
gpu_memory_utilization:0.90 |
预留 10% 的 GPU 内存以备系统开销 |
|
max_sequence_length:8192 |
最大序列总长度(输入 + 输出) |
|
max_num_seqs:1 |
每个 GPU 的最大并发请求数(批处理) |
使用此基线设置运行 GuideLLM 以建立性能基线。在此测试中,GuideLLM 配置为每秒生成 1 个请求,包含 256 个令牌请求和 128 个令牌响应。
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
预期输出:
基线基准测试结果

经调整的 vLLM 配置
调整 vlLM 参数以更好地利用 GPU 资源和并行化:
| vlLM 参数 | 说明 |
|---|---|
|
tensor_parallel_size:1 |
保持在 1 个 GPU。张量并行化必须与 vLLM 要使用的 GPU 数量相匹配 |
|
gpu_memory_utilization:0.92 |
尽可能减少 GPU 内存开销,同时确保 vlLM 继续运行而不会出现错误 |
|
max_sequence_length:4096 |
根据使用案例要求调整最大序列;较低的最大序列可以腾出可用于提高并行化的资源 |
|
max_num_seqs:8 |
增加最大序列会增加吞吐量,但也会增加延迟。增加此值以最大限度地提高吞吐量,同时确保延迟保持在使用案例要求范围内 |
使用 kubectl patch 命令将这些更改应用于正在运行的部署:
kubectl patch deployment vllm-inference-app --type='json' -p='[ {"op": "replace", "path": "/spec/template/spec/containers/0/args/4", "value": "--gpu-memory-utilization=0.92"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/5", "value": "--max-model-len=4096"}, {"op": "replace", "path": "/spec/template/spec/containers/0/args/6", "value": "--max-num-seqs=8"} ]'
检查 vlLM 容器组(pod)是否处于 Ready 1/1 状态:
kubectl get pod -l app=vllm-inference-app -w
预期输出:
NAME READY UP-TO-DATE AVAILABLE AGE vllm-inference-app-65df5fddc8-5kmjm 1/1 1 1 5m
然后使用与以前相同的基准测试值再次运行 GuideLLM:
guidellm benchmark \ --target "http://${NLB}:80" \ --processor meta-llama/Llama-3.1-8B-Instruct \ --rate-type constant \ --rate 1 \ --max-seconds 30 \ --data "prompt_tokens=256,output_tokens=128"
预期输出:
经优化的基准测试结果
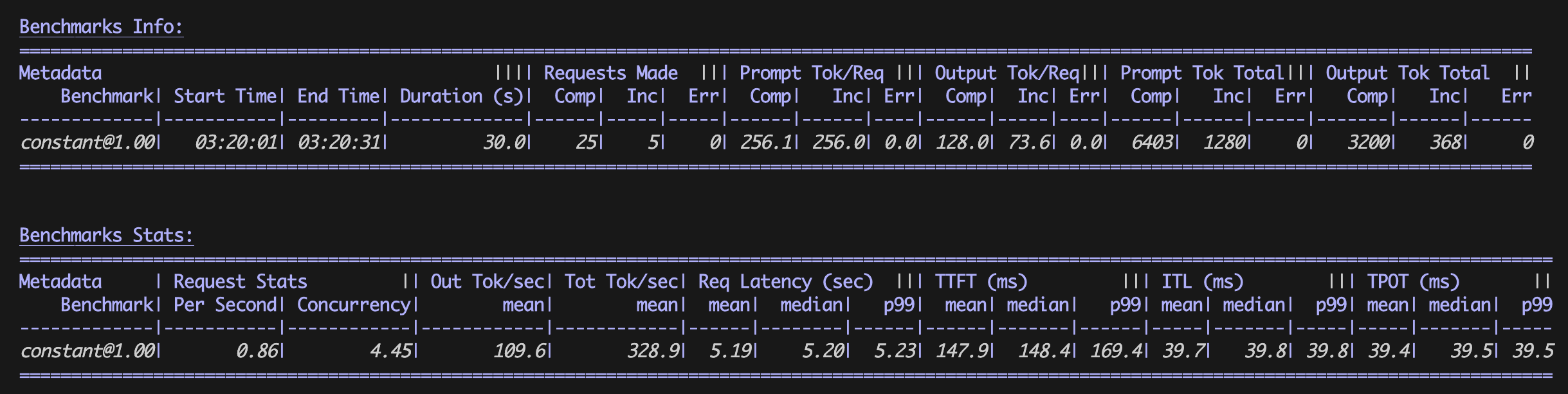
基准测试结果
针对基线和经优化的 vLLM 配置,在表格中计算基准测试结果:
| 平均值 | 基线配置 | 经优化的配置 |
|---|---|---|
|
RPS |
0.23 个请求/秒 |
0.86 个请求/秒 |
|
E2E |
12.99 秒 |
5.19 秒 |
|
TTFT |
8637.2 毫秒 |
147.9 毫秒 |
|
TPOT |
34.0 毫秒 |
39.5 毫秒 |
经优化的 vLLM 配置显著提高了推理吞吐量(RPS)并降低了延迟(E2E、TTFT),每个输出词元的响应时间(TPOT)仅略增加毫秒。这些结果表明 vLLM 如何显著提高推理性能,让每个容器都可以在更短的时间内处理更多请求,从而实现更具成本效益的操作。
