本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
负载均衡
提示
通过 Amazon EKS 研讨会@@ 探索
负载均衡器接收传入流量,并将其分配到 EKS 集群中托管的预期应用程序的目标之间。这提高了应用程序的弹性。部署在 EKS 集群中时,AWS Load Balancer 控制器将为该集群创建和管理 AWS 弹性负载均衡器。创建类型LoadBalancer 为 Kubernetes 的服务时,AWS 负载均衡器控制器会创建一个网络负载均衡器 (NLB),用于对 OSI 模型第 4 层接收到的流量进行负载均衡。而在创建 Kubernetes Ingress 对象时,AWS Load Balancer Contro ller 会创建一个应用程序负载均衡器 (ALB),用于对 OSI 模型第 7 层的流量进行负载均衡。
选择 Load Balancer 类型
AWS Elastic Load Balancing (ELB) 产品组合支持以下负载均衡器:应用程序负载均衡器 (ALB)、网络负载均衡器 (NLB)、网关负载均衡器 (GWLB) 和经典负载均衡器 (CLB)。本最佳实践部分将重点介绍 ALB 和 NLB,这两者与 EKS 集群最为相关。
选择负载均衡器类型的主要考虑因素是工作负载要求。
有关更多详细信息以及所有 AWS 负载均衡器的参考,请参阅产品
如果您的工作负载为,请选择 Application Load Balancer (ALB) HTTP/HTTPS
如果工作负载需要在 OSI 模型的第 7 层进行负载平衡,则可以使用 AWS Load Balancer Controller 来配置 ALB;我们将在下一节中介绍配置。ALB 由前面提到的 Ingress 资源控制和配置,将 HTTP 或 HTTPS 流量路由到集群中的不同 Pod。ALB 为客户提供了更改应用程序流量路由算法的灵活性;默认路由算法是循环算法,而未完成请求最少的路由算法也是另一种选择。
如果您的工作负载是 TCP,或者您的工作负载需要保留客户端的源 IP,请选择 Network Load Balancer (NLB)
Network Load Balancer 在开放系统互联 (OSI) 模型的第四层(传输)上运行。它适用于基于 TCP 和 UDP 的工作负载。默认情况下,Network Load Balancer 在向容器呈现流量时还会保留客户端地址的源 IP。
如果您的工作负载无法使用 DNS,请选择 Network Load Balancer (NLB)
使用 NLB 的另一个关键原因是您的客户无法使用 DNS。在这种情况下,NLB 可能更适合您的工作负载,因为 Network Load Balancer 上的 IP 是静态的。虽然建议客户端在连接到负载均衡器时使用 DNS 将域名解析为 IP 地址,但如果客户端的应用程序不支持 DNS 解析并且只接受硬编码的 IP,那么 NLB 更合适,因为 IP 是静态的,并且在 NLB 的生命周期内保持不变。
配置负载均衡器
在确定最适合您的工作负载的 Load Balancer 之后,客户可以选择多种配置负载均衡器。
通过部署 AWS Load Balancer 控制器来配置负载均衡器
在 EKS 集群中配置负载均衡器有两种主要方法。
-
利用 AWS 云提供商中的服务控制器(旧版)
-
利用 AWS Load Balancer 控制器(推荐)
默认情况下,Kubernetes 服务控制器(也称为树内控制器)会协调类型的 Kubernetes 服务资源。 LoadBalancer此控制器内置在 AWS 云提供商
已配置的 Elastic Load Balancer 的配置由必须添加到 Kubernetes 服务清单中的注释控制。服务控制器
服务控制器是旧版,目前仅修复了严重的错误。当您创建类型为 Kubernetes 服务时 LoadBalancer,服务控制器会默认创建 AWS 负载均衡,但如果您使用正确的注释,也可以创建 AWS NLB。值得注意的是,服务控制器不支持 Kubernetes 入口资源,也不支持 IPv6。
我们建议在您的 EKS 集群中使用 AWS Load Balancer 控制器来协调 Kubernetes 服务和入口资源。您必须在 Kubernetes 服务或 Ingress 清单中使用正确的注释,这样 AWS Load Balancer Controller 才能拥有协调流程。 (而不是服务控制器)
如果您使用的是 EKS 自动模式,则会自动为您提供 AWS Load Balancer 控制器;无需安装。
选择 Load Balancer Target-Type
使用 IP 将 Pod 注册为目标 Target-Type
AWS Elastic Load Balancer:网络和应用程序,将收到的流量发送到目标组中的注册目标。对于 EKS 集群,您可以在目标组中注册两种类型的目标:实例和 IP,使用哪种目标类型会影响注册的内容以及流量从 Load Balancer 路由到 Pod 的方式。默认情况下,AWS Load Balancer 控制器将使用 “实例” 类型注册目标,该目标将是工作节点的 IPNodePort,其含义包括:
-
来自 Load Balancer 的流量将被转发到上的 Worker 节点 NodePort,这由 iptables 规则(由节点上运行的 kube-proxy 配置)处理,然后通过其 clusterIP(仍在节点上)转发到服务,最后服务随机选择一个注册到它的 pod 并将流量转发给它。此流程涉及多个跃点,可能会产生额外的延迟,特别是因为服务有时会选择在另一个工作节点上运行的 pod,而该工作节点也可能位于另一个可用区中。
-
由于 Load Balancer 将工作节点注册为其目标,这意味着发送到目标的运行状况检查不会直接被 Pod 接收,而是由 Pod 上的工作节点接收,运行状况检查流量将遵循上述相同的路径。 NodePort
-
监控和故障排除更为复杂,因为 Load Balancer 转发的流量不会直接发送到 pod,因此您必须仔细关联工作节点上收到的数据包与服务 ClusterIP,并最终关联到 Pod,才能完全端到端地了解数据包的路径,以便进行正确的故障排除。

相比之下,如果您按照我们的建议将目标类型配置为 “IP”,则含义将如下:
-
来自 Load Balancer 的流量将直接转发到 pod,这简化了网络路径,因为它绕过了之前额外的 Worker 节点和服务集群 IP 跳数,减少了服务将流量转发到另一个可用区中的 pod 时本来会产生的延迟,最后它消除了工作节点上的 iptables 规则开销处理。
-
负载均衡器的运行状况检查由 Pod 直接接收和响应,这意味着目标状态 “健康” 或 “不健康” 直接表示 Pod 的健康状态。
-
监控和故障排除更容易,任何用于捕获数据包 IP 地址的工具都将在其源和目标字段中直接显示 Load Balancer 和 pod 之间的双向流量。

要创建使用 IP 目标的 AWS Elastic Load Balancing,请添加:
-
alb.ingress.kubernetes.io/target-type: ip配置 Kubernetes Ingress(Application Load Balancer)时的 Ingress 清单的注释 -
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip在配置你的 Kubernetes 服务类型 LoadBalancer (网络负载均衡器)时,在你的服务清单中添加注释。
配置 Load Balancer 运行状况检查
虽然 Kubernetes 提供了自己的运行状况检查机制(将在下一节中详细介绍),但我们建议实施 ELB 运行状况检查作为在 Kubernetes 控制平面之外运行的补充保护措施。即使在以下情况下,这个独立层也会继续监视您的应用程序:
-
Kubernetes 控制面板中断
-
探测器执行延迟
-
kubelet 和 pod 之间的网络分区
对于在上述场景中需要最大可用性加速恢复的关键工作负载,ELB 运行状况检查提供了一个与 Kubernetes 原生机制配合使用而不是取代 Kubernetes 原生机制的基本安全网。
要在 ELB 上配置和微调运行状况检查,您必须在 Kubernetes 服务或 Ingress 清单中使用将由服务控制器或 AWS Load Balancer Controller 协调的注释。
可用性和 Pod 生命周期
在应用程序升级期间,您必须确保您的应用程序始终可用于处理请求,这样用户就不会遇到任何停机时间。在这种情况下,一个常见的挑战是在 Kubernetes 层和基础架构(例如外部负载均衡器)之间同步工作负载的可用性状态。接下来的几节将重点介绍解决此类情况的最佳实践。
注意
以下解释是基于的,EndpointSlices
使用运行状况检查
默认情况下,Kubernetes 会运行进程运行状况检查
请参阅下方附录中的 Pod 创建部分,重新了解 Pod 创建过程中的事件顺序。
使用就绪探测器
默认情况下,当 Pod 中的所有容器都在运行success。另一方面,如果探测器在更远的距离内失败,则会将 Pod 从 EndpointSlice 物体中移除。您可以在 Pod 清单中为每个容器配置就绪探测器。 kubelet每个节点上的进程对该节点上的容器运行就绪探测。
利用 Pod 就绪门
就绪探测器的一个方面是它没有外部feedback/influence 机制,节点上的 kubelet 进程执行探测器并定义探测器的状态。这不会对 Kubernetes 层中微服务本身之间的请求(东西向流量)产生任何影响,因为 EndpointSlice 控制器会使端点列表 (Pod) 始终保持最新。那么,为什么以及何时需要外部机制呢?
当您使用 Load Balancer 或 Kubernetes Ingress(用于南北流量)的 Kubernetes 服务类型公开应用程序时,必须将相应的 Kubernetes 服务的 Pod IP 列表传播到外部基础设施负载均衡器,以便负载均衡器也具有最新的列表目标。AWS Load Balancer 控制器弥合了这里的差距。当你使用 AWS Load Balancer Controller 并利用target group: IP时,就像 kube-proxy AWS Load Balancer 控制器也会收到更新(通过watch),然后它会与 ELB API 通信,配置并开始在 ELB 上将 Pod IP 注册为目标。
当你对部署进行滚动更新时,会创建新的 Pod,一旦新 Pod 的状态为 “就绪”, old/existing Pod 就会被终止。在此过程中,Kubernetes EndpointSlice 对象的更新速度快于 ELB 将新 Pod 注册为目标所需的时间,请参阅目标注册。在短时间内,Kubernetes 层和可能丢弃客户端请求的基础设施层之间可能会出现状态不匹配。在这段时间内,在 Kubernetes 层中,新的 Pod 已经准备好处理请求了,但从 ELB 的角度来看,它们还没有。
Pod Readiness Gates
优雅地关闭应用程序
您的应用程序应通过开始正常关闭来响应 SIGTERM 信号,这样客户端就不会遇到任何停机时间。这意味着您的应用程序应该运行清理程序,例如保存数据、关闭文件描述符、关闭数据库连接、优雅地完成动态请求并及时退出以满足 Pod 终止请求。您应该将宽限期设置为足够长的时间,以便清理工作可以完成。要了解如何响应 SIGTERM 信号,您可以参考用于应用程序的相应编程语言的资源。
如果您的应用程序在收到 SIGTERM 信号后无法正常关闭,或者它ignores/does 没有收到信号
事件的总体顺序如下图所示。注意:无论应用程序的正常关闭过程的结果如何,或者 PreStop 挂钩的结果如何,应用程序容器最终都会通过 SIGKILL 在宽限期结束时终止。
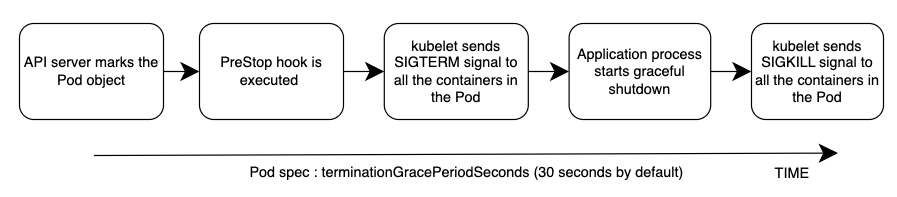
请参阅下方附录中的 Pod 删除部分,重新了解 Pod 删除过程中的事件顺序。
优雅地处理客户请求
Pod 删除中的事件顺序与 Pod 创建中的事件顺序不同。创建 Pod 后,会kubelet更新 Kubernetes API 中的 Pod IP,然后才会更新 EndpointSlice 对象。另一方面,当 Pod 被终止时,Kubernetes API 会同时通知 kubelet 和 EndpointSlice 控制器。仔细检查下图,该图显示了事件的顺序。
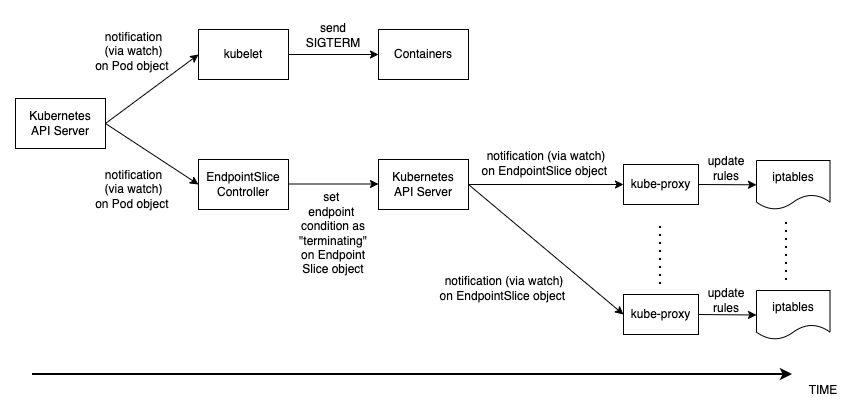
状态从 API 服务器一直传播到上面解释的节点上的 iptables 规则的方式创造了一个有趣的竞争条件。因为容器很有可能比每个节点上的 kube-proxy 更早地收到 SIGKILL 信号,所以更新本地 iptables 规则。在这种情况下,值得一提的两种情况是:
-
如果您的应用程序在收到SIGTERM后立即直言不讳地丢弃了正在进行的请求和连接,这意味着客户端将看到50倍的错误。
-
即使您的应用程序确保在收到 SIGTERM 后完全处理所有正在进行的请求和连接,但在宽限期内,新的客户端请求仍会发送到应用程序容器,因为 iptables 规则可能仍未更新。在清理过程关闭容器上的服务器套接字之前,这些新请求将导致新的连接。当宽限期结束时,这些在 SIGTERM 之后建立的连接将在发送 SIGKILL 后无条件中断。
在 Pod 规范中设置足够长的宽限期可能会解决这个问题,但是根据传播延迟和实际客户端请求的数量,很难预测应用程序优雅地关闭连接所需的时间。因此,这里不太完美但最可行的方法是使用 PreStop 钩子将SIGTERM信号延迟到iptables规则更新之前,以确保没有新的客户端请求发送到应用程序,而是只有现有的连接才能继续。 PreStop hook 可以是一个简单的 Exec 处理程序,例如。sleep 10
当您使用 Kubernetes 服务类型 Load Balancer 或 Kubernetes Ingress(适用于南北流量)使用 AWS Load Balancer Controller 和杠杆来公开应用程序时,上述行为和建议同样适用。target group: IP因为就像 kube-proxy AWS Load Balancer Controller 也会收到 EndpointSlice 对象的更新(通过监视),然后它与 ELB API 通信以开始从 ELB 注销 Pod IP。但是,根据 Kubernetes API 或 ELB API 的负载,这也可能需要一些时间,而且 SIGTERM 可能很久以前就已经发送到应用程序了。ELB 开始注销目标后,它将停止向该目标发送请求,因此应用程序将不会收到任何新请求,并且 ELB 还会开始取消注册延迟,默认为 300 秒。在注销过程中,目标基本上是 ELB 等待与该目标的飞行中 requests/existing 连接耗尽draining的地方。取消注册延迟到期后,目标将处于未使用状态,并且向该目标发出的任何正在进行的请求都将被强制丢弃。
使用 Pod 中断预算
为您的应用程序配置 Pod 中断预算
参考
-
KubeCon 2019 年欧洲会议—— 准备好了吗? 深入探讨 Service Health 的 Pod 就绪之门
-
图书-Kubernetes
在行动
附录
Pod 创建
在部署 Pod 然后开始 healthy/ready 接收和处理客户端请求的场景中,必须了解事件的顺序。让我们来谈谈事件的顺序。
-
Pod 是在 Kubernetes 控制平面上创建的(即通过 kubectl 命令、部署更新或扩展操作)。
-
kube-scheduler将 Pod 分配给集群中的一个节点。 -
在分配的节点上运行的 kubelet 进程(通过
watch)接收更新,并与容器运行时通信以启动 Pod 规范中定义的容器。 -
当容器开始运行时,kubelet 会像 Kubernet es API
Ready中的 Pod 对象一样更新 Pod 条件。 -
EndpointSlice控制器
接收 Pod 状态更新(通过 watch),并将 Pod IP/Port 作为新端点添加到相应 Kubernetes 服务的EndpointSlice对象(Pod IP 列表)中。 -
每个节点上的 kube-proxy
进程(通过 watch)接收EndpointSlice 对象的更新,然后使用新的 Pod 更新每个节点上的 iptables规则。 IP/port
吊舱删除
就像创建 Pod 一样,必须了解 Pod 删除期间的事件顺序。让我们来谈谈事件的顺序。
-
Pod 删除请求会发送到 Kubernetes API 服务器(即通过
kubectl命令、部署更新或扩展操作)。 -
Kubernetes API 服务器通过在 P od 对象中设置 deletionTimeStamp
字段来启动宽限期 ,默认为 30 秒。(宽限期可以通过以下方式在 Pod 规范中配置 terminationGracePeriodSeconds) -
节点上运行的
kubelet进程接收 Pod 对象的更新(通过 watch),并向该 Pod 中每个容器内的进程标识符 1(PID 1)发送 SIGTERM 信号。然后它看 terminationGracePeriodSeconds. -
EndpointSlice控制器
还接收步骤 2 中的更新(通过 watch),并在相应的 Kubernetes 服务的EndpointSlice对象(Pod IP 列表)中将端点条件设置为 “终止”。 -
每个节点上的 kube-proxy
进程(通过 watch)接收EndpointSlice 对象的更新,然后 kube-proxy 更新每个节点上的 iptables 规则,以停止将客户端的请求转发到 Pod。 -
当
terminationGracePeriodSeconds过期时,会向 Pod 中每个容器的父进程kubelet发送 SIGKILL 信号并强制终止它们。 -
TheEndpointSlice控制器
从EndpointSlice 对象中移除端点。 -
API 服务器会删除 Pod 对象。
