本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
控制平面监控
API 服务器
在查看我们的 API 服务器时,请务必记住,其功能之一是限制入站请求以防止控制平面过载。看似在 API 服务器级别的瓶颈实际上可能是保护它免受更严重问题的侵害。我们需要考虑增加通过系统的请求量的利弊。为了确定是否应增加 API 服务器的值,以下是我们需要注意的事项的小示例:
-
在系统中传输的请求的延迟是多少?
-
那是 API 服务器本身的延迟,还是像 etcd 这样的 “下游”?
-
API 服务器队列深度是造成这种延迟的一个因素吗?
-
API 优先级和公平性 (APF) 队列是否针对我们想要的 API 调用模式设置正确?
问题出在哪里?
首先,我们可以使用 API 延迟指标来深入了解 API 服务器为请求提供服务所花费的时间。让我们使用下面的 PromQL 和 Grafana 热图来显示这些数据。
max(increase(apiserver_request_duration_seconds_bucket{subresource!="status",subresource!="token",subresource!="scale",subresource!="/healthz",subresource!="binding",subresource!="proxy",verb!="WATCH"}[$__rate_interval])) by (le)
注意
要详细了解如何使用本文中使用的 API 控制面板监控 API 服务器,请参阅以下博客
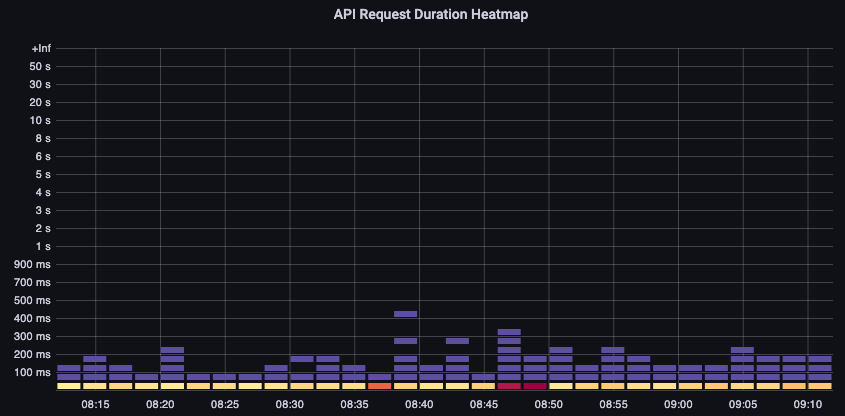
这些请求都在一秒钟以内,这很好地表明控制平面正在及时处理请求。但是,如果不是这样呢?
我们在上述 API 请求持续时间中使用的格式是热图。热图格式的好处在于,它可以告诉我们默认情况下 API 的超时值(60 秒)。但是,我们真正需要知道的是,在达到超时阈值之前,这个值应该在什么阈值上引起关注。有关可接受阈值的粗略指导,我们可以使用上游 Kubernetes SLO,可以在这里找到
注意
注意到这个语句上的 max 函数了吗? 使用聚合多台服务器(EKS 上默认为两台 API 服务器)的指标时,重要的是不要将这些服务器放在一起进行平均值。
非对称流量模式
如果一个 API 服务器 [pod] 加载得很轻,而另一个负载很重怎么办? 如果我们将这两个数字相加求平均值,我们可能会误解正在发生的事情。例如,这里我们有三个 API 服务器,但所有负载都在其中一个 API 服务器上。通常,在投资规模和性能问题时,任何具有多台服务器(例如etcd和API服务器)的东西都应进行细分。
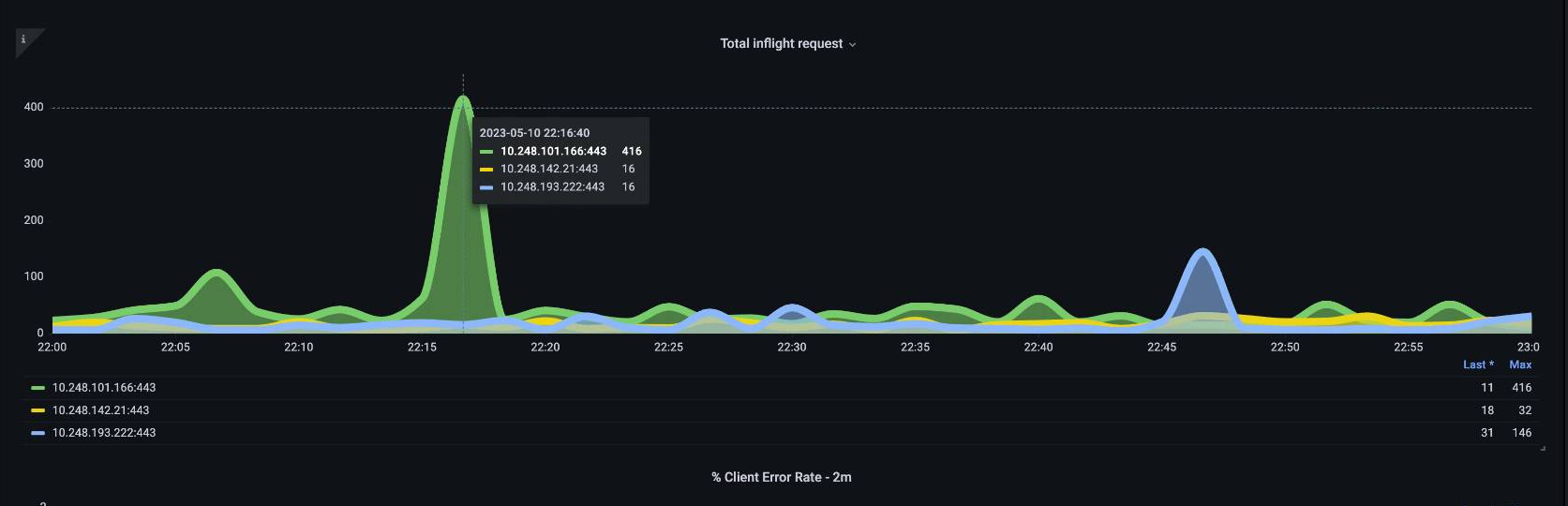
随着转向 API 优先级和公平性,系统上的请求总数只是检查 API 服务器是否超额订阅的一个因素。由于系统现在可以处理一系列队列,因此我们必须查看这些队列中是否有任何队列已满,以及该队列的流量是否被丢弃。
让我们用以下查询来看看这些队列:
max without(instance)(apiserver_flowcontrol_nominal_limit_seats{})
注意
有关 API A&F 工作原理的更多信息,请参阅以下最佳实践指南
在这里,我们可以看到集群中默认出现的七个不同的优先级组

接下来,我们想看看该优先级组中使用了多少百分比,这样我们就可以了解某个优先级是否已饱和。将请求限制在工作负载低级别可能是可取的,但是降低领导人选举级别则不是。
API 优先级与公平性 (APF) 系统有许多复杂的选项,其中一些选项可能会产生意想不到的后果。我们在现场看到的一个常见问题是将队列深度增加到开始增加不必要的延迟的程度。我们可以使用apiserver_flowcontrol_current_inqueue_request指标来监控这个问题。我们可以使用. 来检查掉落情况apiserver_flowcontrol_rejected_requests_total。如果任何存储桶超过其并发度,则这些指标将为非零值。
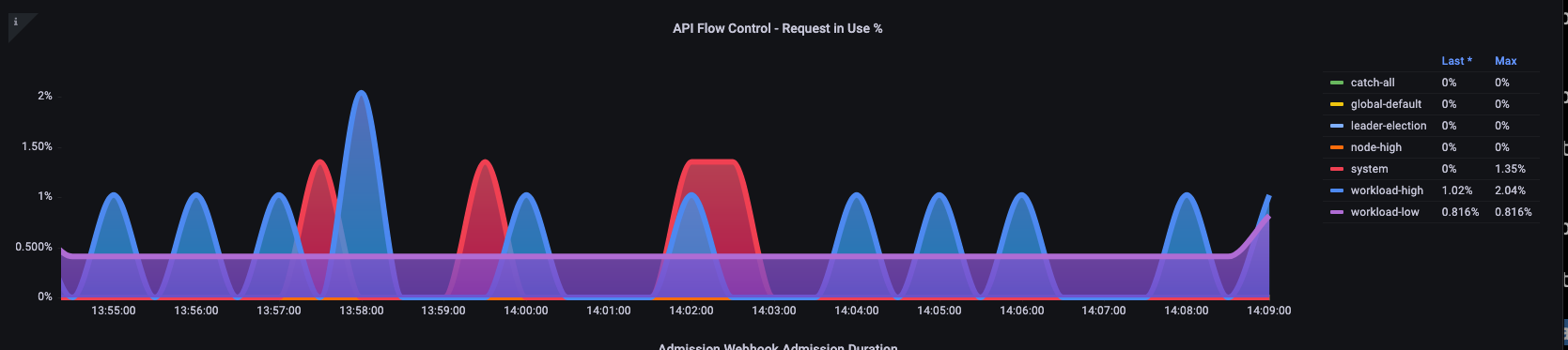
增加队列深度会使 API 服务器成为延迟的重要来源,因此应谨慎行事。我们建议谨慎对待创建的队列数量。例如,EKS 系统上的共享数量为 600,如果我们创建的队列太多,这可能会减少需要吞吐量的重要队列(例如领导者选举队列或系统队列)中的份额。创建过多的额外队列会使正确调整这些队列的大小变得更加困难。
为了专注于您可以在APF中进行的简单而有影响力的更改,我们只需从未充分利用的存储桶中提取份额,然后增加处于最大使用量的存储桶的大小。通过在这些桶之间智能地重新分配股份,您可以降低下跌的可能性。
有关更多信息,请访问《EKS 最佳实践指南》中的 API 优先级和公平性设置。
API 与 etcd 延迟
我们如何使用 API 服务器 metrics/logs 的来确定 API 服务器是否有问题,还是 API 服务器的问题,或者两者兼而有之。 upstream/downstream 为了更好地理解这一点,让我们来看看 API Server 和 etcd 是如何关联的,以及对错误的系统进行故障排除有多容易。
在下图中,我们看到了 API 服务器延迟,但我们也看到其中大部分延迟与 etcd 服务器相关,因为图表中的条形显示了 etcd 级别的大部分延迟。如果同时有 15 秒的 etcd 延迟,则有 20 秒的 API 服务器延迟,则大部分延迟实际上处于 etcd 级别。
通过查看整个流程,我们发现明智的做法是不要只关注 API 服务器,还要寻找表明 etcd 受到胁迫的信号(即缓慢的应用计数器增加)。只需一眼就能快速移动到正确的问题区域是仪表板的强大之处。
注意
部分中的仪表板可在以下网址找到 https://github.com/RiskyAdventure/Troubleshooting-Dashboards/blob/main/api-troubleshooter.json
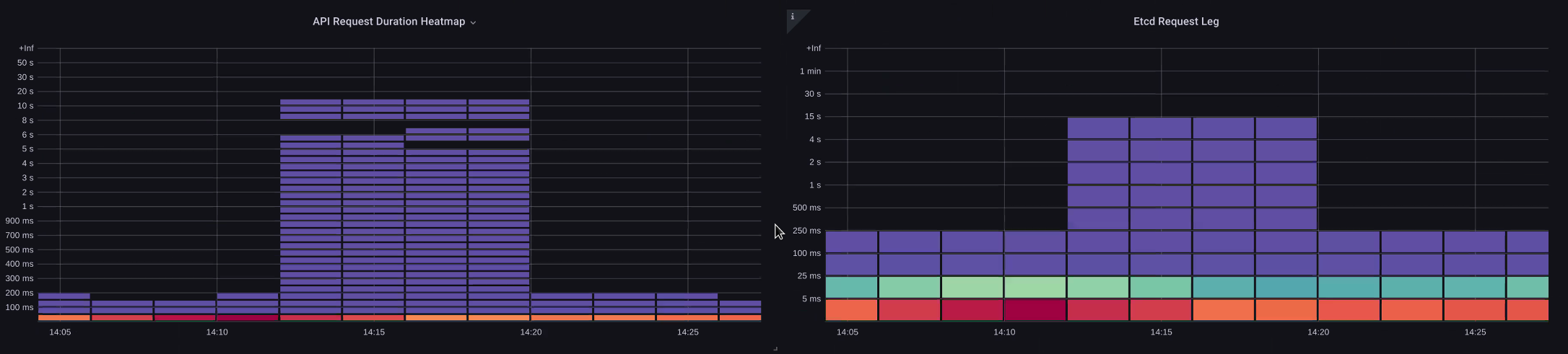
控制平面与客户端问题
在此图表中,我们正在寻找在此期间完成时间最长的 API 调用。在本例中,我们看到自定义资源 (CRD) 正在调用 APPLY 函数,这是 05:40 时间范围内最潜在的调用。
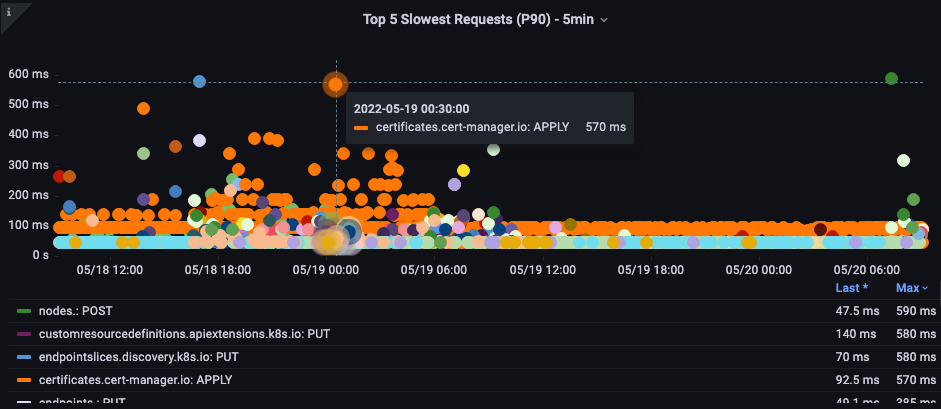
有了这些数据,我们就可以在该时间段内使用 Ad-Hoc PromQL 或 CloudWatch Insights 查询从审计日志中提取列表请求,以查看这可能是哪个应用程序。
通过以下方式寻找来源 CloudWatch
指标最好用于查找我们要查看的问题区域,并缩小问题的时间范围和搜索参数。有了这些数据后,我们想过渡到日志,以获取更详细的时间和错误。为此,我们将使用 Logs Insights 将CloudWatch 日志转换为指标。
例如,为了调查上述问题,我们将使用以下 L CloudWatch ogs Insights 查询来提取 userAgent 和 requestURI,这样我们就可以确定哪个应用程序导致了这种延迟。
注意
需要使用适当的计数,以免手表 List/Resync 出现正常行为。
fields @timestamp, @message | filter @logStream like "kube-apiserver-audit" | filter ispresent(requestURI) | filter verb = "list" | parse requestReceivedTimestamp /\d+-\d+-(?<StartDay>\d+)T(?<StartHour>\d+):(?<StartMinute>\d+):(?<StartSec>\d+).(?<StartMsec>\d+)Z/ | parse stageTimestamp /\d+-\d+-(?<EndDay>\d+)T(?<EndHour>\d+):(?<EndMinute>\d+):(?<EndSec>\d+).(?<EndMsec>\d+)Z/ | fields (StartHour * 3600 + StartMinute * 60 + StartSec + StartMsec / 1000000) as StartTime, (EndHour * 3600 + EndMinute * 60 + EndSec + EndMsec / 1000000) as EndTime, (EndTime - StartTime) as DeltaTime | stats avg(DeltaTime) as AverageDeltaTime, count(*) as CountTime by requestURI, userAgent | filter CountTime >=50 | sort AverageDeltaTime desc
通过此查询,我们发现两个不同的代理正在运行大量高延迟列表操作。Splunk 和 CloudWatch 特工。有了这些数据,我们就可以决定移除、更新这个控制器,或者用另一个项目替换这个控制器。

注意
有关此主题的更多详细信息,请参阅以下博客
调度器
由于 EKS 控制平面实例是在单独的 AWS 账户中运行的,因此我们将无法抓取这些组件来获取指标(API 服务器是个例外)。但是,由于我们可以访问这些组件的审计日志,因此我们可以将这些日志转换为指标,以查看是否有任何子系统导致了扩展瓶颈。让我们使用 Logs CloudWatch Insights 来查看调度器队列中有多少未调度的 pod。
调度器日志中未调度的 pod
如果我们可以直接在自我管理的 Kubernetes(例如 Kops)上抓取调度器指标,我们将使用以下 PromQL 来了解调度器待办事项。
max without(instance)(scheduler_pending_pods)
由于我们无法在 EKS 中访问上述指标,因此我们将使用以下 Lo CloudWatch gs Insights 查询来查看在特定时间段内有多少 pod 无法取消调度,从而查看积压情况。然后,我们可以进一步研究高峰时段的消息,以了解瓶颈的本质。例如,节点的旋转速度不够快,或者调度器本身的速率限制器。
fields timestamp, pod, err, @message
| filter @logStream like "scheduler"
| filter @message like "Unable to schedule pod"
| parse @message /^.(?<date>\d{4})\s+(?<timestamp>\d+:\d+:\d+\.\d+)\s+\S*\s+\S+\]\s\"(.*?)\"\s+pod=(?<pod>\"(.*?)\")\s+err=(?<err>\"(.*?)\")/
| count(*) as count by pod, err
| sort count desc
在这里,我们看到了调度程序的错误,说由于存储 PVC 不可用,Pod 没有部署。

注意
必须在控制平面上开启审计日志才能启用此功能。限制日志保留也是一种最佳做法,以免随着时间的推移不必要地增加成本。使用下面的 EKSCTL 工具开启所有日志功能的示例。
cloudWatch: clusterLogging: enableTypes: ["*"] logRetentionInDays: 10
Kube 控制器管理器
与所有其他控制器一样,Kube 控制器管理器对一次可以执行的操作数量有限制。让我们通过查看可以在其中设置这些参数的 KOPS 配置来回顾一下其中一些标志是什么。
kubeControllerManager: concurrentEndpointSyncs: 5 concurrentReplicasetSyncs: 5 concurrentNamespaceSyncs: 10 concurrentServiceaccountTokenSyncs: 5 concurrentServiceSyncs: 5 concurrentResourceQuotaSyncs: 5 concurrentGcSyncs: 20 kubeAPIBurst: 30 kubeAPIQPS: "20"
这些控制器的队列在集群流失率高时会被填满。在本例中,我们看到 replicaset 集控制器的队列中有大量待办事项。
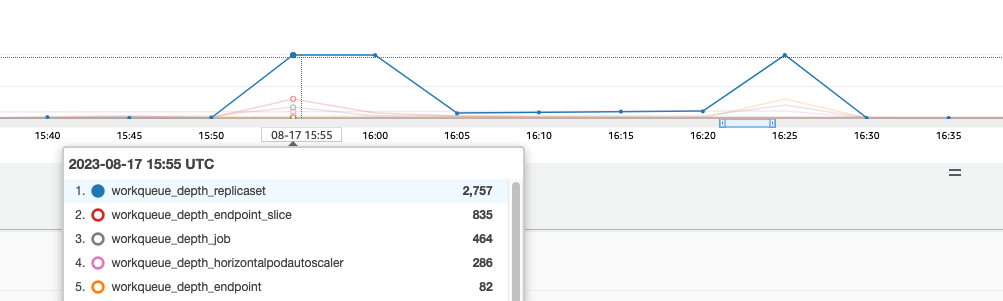
我们有两种不同的方法可以解决这种情况。如果运行自我管理,我们可以简单地增加并发 goroutine,但是这会在 KCM 中处理更多数据,从而对 etcd 产生影响。另一种选择是减少部署中使用的.spec.revisionHistoryLimit副本集对象的数量,以减少我们可以回滚的副本集对象的数量,从而减轻该控制器的压力。
spec: revisionHistoryLimit: 2
可以调整或关闭 Kubernetes 的其他 Kubernetes 功能,以减轻高流失率系统中的压力。例如,如果我们 pod 中的应用程序不需要直接与 k8s API 通信,那么关闭这些 pod 中的投影密将减少负载。 ServiceaccountTokenSyncs如果可能,这是解决此类问题的更理想方法。
kind: Pod spec: automountServiceAccountToken: false
在我们无法访问指标的系统中,我们可以再次查看日志来检测争用情况。如果我们想查看每个控制器或汇总级别上正在处理的请求数量,我们可以使用以下 L CloudWatch ogs Insights 查询。
KCM 处理的总容量
# Query to count API qps coming from kube-controller-manager, split by controller type. # If you're seeing values close to 20/sec for any particular controller, it's most likely seeing client-side API throttling. fields @timestamp, @logStream, @message | filter @logStream like /kube-apiserver-audit/ | filter userAgent like /kube-controller-manager/ # Exclude lease-related calls (not counted under kcm qps) | filter requestURI not like "apis/coordination.k8s.io/v1/namespaces/kube-system/leases/kube-controller-manager" # Exclude API discovery calls (not counted under kcm qps) | filter requestURI not like "?timeout=32s" # Exclude watch calls (not counted under kcm qps) | filter verb != "watch" # If you want to get counts of API calls coming from a specific controller, uncomment the appropriate line below: # | filter user.username like "system:serviceaccount:kube-system:job-controller" # | filter user.username like "system:serviceaccount:kube-system:cronjob-controller" # | filter user.username like "system:serviceaccount:kube-system:deployment-controller" # | filter user.username like "system:serviceaccount:kube-system:replicaset-controller" # | filter user.username like "system:serviceaccount:kube-system:horizontal-pod-autoscaler" # | filter user.username like "system:serviceaccount:kube-system:persistent-volume-binder" # | filter user.username like "system:serviceaccount:kube-system:endpointslice-controller" # | filter user.username like "system:serviceaccount:kube-system:endpoint-controller" # | filter user.username like "system:serviceaccount:kube-system:generic-garbage-controller" | stats count(*) as count by user.username | sort count desc
这里的关键要点是,在研究可扩展性问题时,在进入详细的故障排除阶段之前,要先查看路径中的每个步骤(API、调度程序、KCM 等)。通常在生产环境中,你会发现需要对 Kubernetes 的多个部分进行调整,才能让系统以最佳性能运行。很容易无意中对瓶颈大得多的症状(例如节点超时)进行故障排除。
ETCD
etcd 使用内存映射文件有效地存储键值对。有一种保护机制可以设置此可用内存空间的大小,通常设置为 2、4 和 8GB 的限制。数据库中较少的对象意味着在更新对象和需要清理旧版本时,etcd 需要做的清理工作更少。这种清理对象旧版本的过程称为压缩。经过多次压缩操作后,会有一个后续的过程来恢复可用空间空间,称为碎片整理,该过程发生在超过一定阈值或固定时间表上。
我们可以做一些与用户相关的项目来限制 Kubernetes 中对象的数量,从而减少压缩和碎片整理过程的影响。例如,Helm 保持高位revisionHistoryLimit。这样可以使系统 ReplicaSets 上的旧对象能够进行回滚。通过将历史记录限制设置为 2,我们可以将对象(比如 ReplicaSets)的数量从十个减少到两个,这反过来又会减少系统的负载。
apiVersion: apps/v1 kind: Deployment spec: revisionHistoryLimit: 2
从监控的角度来看,如果系统延迟峰值以设定的模式出现,以小时为间隔,则检查此碎片整理过程是否是源头可能会有所帮助。我们可以通过使用 L CloudWatch ogs 来看到这一点。
如果您想查看碎片整理 start/end 时间,请使用以下查询:
fields @timestamp, @message | filter @logStream like /etcd-manager/ | filter @message like /defraging|defraged/ | sort @timestamp asc

