本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
通过数据分区加速迁移
对于大规模迁移,我们建议使用多个 DataSync任务对数据集进行分区。将源数据划分到多个任务(可能还有代理)中,可以并行处理传输并缩短迁移时间。
分区还可以帮助您保持在 DataSync 配额范围内,并简化对任务的监控和调试。
下图显示了如何使用多个 DataSync 任务和代理从同一个源存储位置传输数据。在这种情况下,各项任务都专注于源位置的特定文件夹。有关这些方法的更多信息和示例,请参阅如何使用横向 AWS DataSync 扩展架构加速数据传输
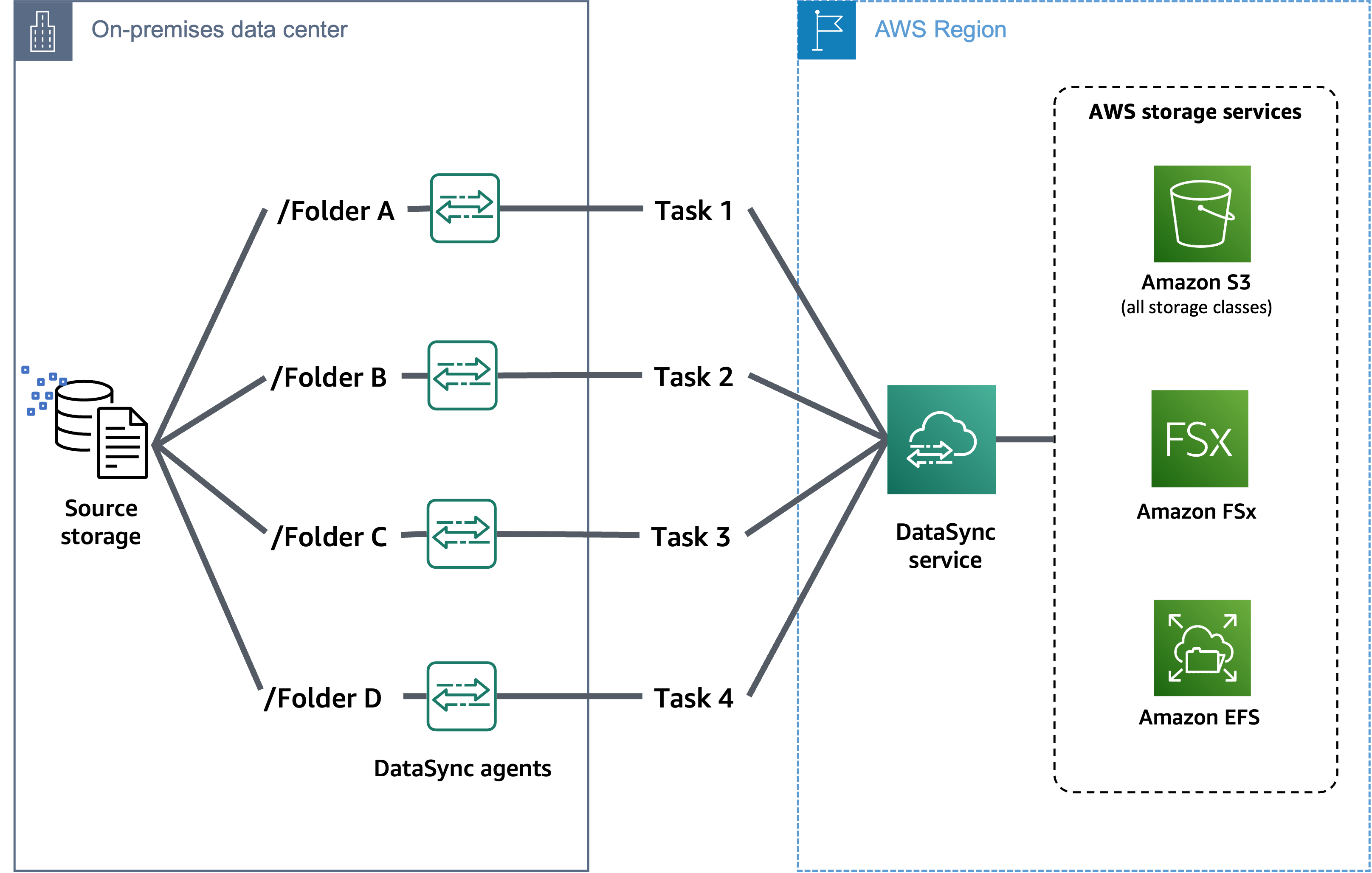
按文件夹或前缀对数据集进行分区
创建 DataSync 源位置时,您可以指定从中 DataSync 读取的文件夹、目录或前缀。例如,如果要迁移具有顶级目录的文件共享,则可创建多个位置来指定不同的目录路径。然后,您可以在迁移期间使用这些位置运行多个 DataSync任务。
使用筛选条件对数据集进行分区
您可以应用筛选条件,在传输中包含或排除源位置的数据。在大规模迁移的背景下,筛选条件有助于将任务范围限定到数据集的特定部分。
例如,如果要迁移按年份组织的存档数据,则可创建一个包含筛选条件来匹配特定年份或多个年份。此外还可以在每次运行任务时修改筛选条件以匹配不同的年份。
使用清单对数据集进行分区
清单是您要传输的文件或对象 DataSync 的列表。有了清单,就 DataSync 不必读取源位置的所有内容就能确定要传输的内容。
您可以根据源存储的清单创建清单,也可以通过事件驱动的方法创建清单(例如,参见AWS DataSync 使用数亿个对象实现
