本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
的组成部分 AWS Batch
AWS Batch 简化了在一个区域内的多个可用区中运行批处理作业。您可以在新的或现有的 VPC 中创建 AWS Batch 计算环境。在计算环境就绪并与任务队列关联后,您可以定义任务定义,以指定要运行任务的 Docker 容器映像。容器映像将在容器注册表中存储和提取,可能存在于您的 AWS 基础设施的内部或外部。
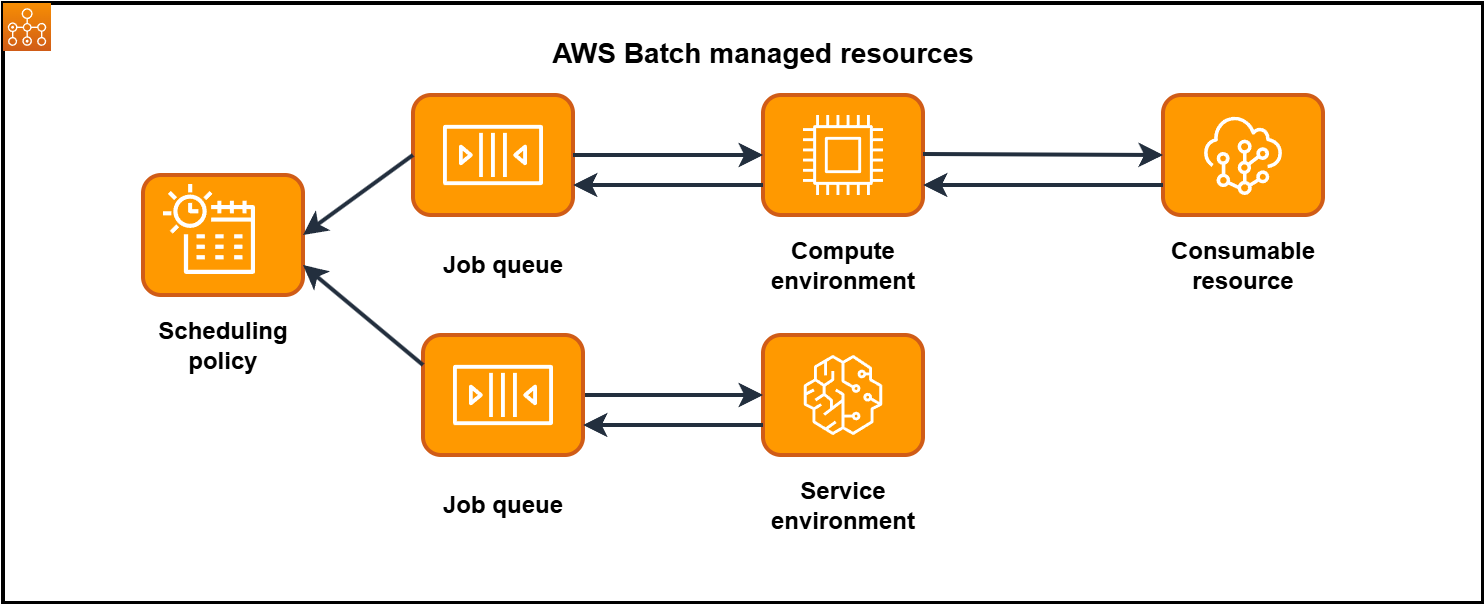
计算环境
计算环境是一组用于运行任务的托管或非托管计算资源。在托管计算环境中,您可以按多个详细级别指定所需的计算类型(Fargate 或 EC2)。您可以设置使用特定类型 EC2 实例的计算环境,例如 c5.2xlarge 或 m5.10xlarge。或者,您也可以选择仅指定要使用最新的实例类型。您还可以为环境指定最小、所需和最大 vCPU 数量,以及您愿意为竞价型实例支付的金额(占实例价格的 On-Demand 百分比和目标 VPC 子网集)。 AWS Batch 根据需要高效启动、管理和终止计算类型。您还可以管理自己的计算环境。因此,您负责在为您 AWS Batch 创建的 Amazon ECS 集群中设置和扩展实例。有关更多信息,请参阅 的计算环境 AWS Batch。
作业队列
提交 AWS Batch 作业时,将其提交到特定的作业队列,该作业在调度到计算环境之前一直驻留在该队列中。将一个或多个计算环境与作业队列相关联。您还可以为这些计算环境甚至作业队列本身分配优先级值。例如,您可以有一个高优先级队列用以提交时间敏感型任务,以及一个低优先级队列供可在计算资源较便宜时随时运行的任务使用。有关更多信息,请参阅 作业队列。
作业定义
作业定义指定作业的运行方式。您可以把作业定义看成是任务中的资源的蓝图。您可以为任务提供 IAM 角色以提供对其他 AWS 资源的访问权限。您还可以指定内存和 CPU 要求。任务定义还可以控制容器属性、环境变量和持久性存储的挂载点。任务定义中的许多规范可以通过在提交单个任务时指定新值来覆盖。有关更多信息,请参阅 作业定义。
作业
提交到 AWS Batch的工作单位 (如 shell 脚本、Linux 可执行文件或 Docker 容器映像)。它有一个名称,使用您在任务定义中指定的参数,在计算环境中的 AWS Fargate 或 Amazon EC2 资源上作为容器化应用程序运行。作业可以按名称或按 ID 引用其他作业,并且可以依赖于其他作业的成功完成或您的指定的资源的可用性。有关更多信息,请参阅 作业。
计划策略
您可以使用调度策略来配置如何在用户或工作负载之间分配作业队列中的计算资源。使用公平份额调度策略,您可以为工作负载或用户分配不同的份额标识符。 AWS Batch 作业调度器默认为先进先出 (FIFO) 策略。有关更多信息,请参阅 公平份额调度策略。
消耗性资源
消耗性资源是运行作业所需的资源,例如第三方许可证令牌、数据库访问带宽、对第三方 API 的调用进行节流的需求等。您可以指定作业运行所需的消耗性资源,Batch 在调度作业时会考虑这些资源依赖项。您可以通过仅分配具有全部所需资源的作业来减少计算资源利用不足的情况。有关更多信息,请参阅 资源感知调度。
服务环境
服务环境定义了如何与 AWS Batch 集成 SageMaker 以执行任务。服务环境 AWS Batch 允许提交和管理作业, SageMaker 同时提供排队、调度和优先级管理功能。 AWS Batch服务环境定义了特定服务类型(例如 SageMaker 训练作业)的容量限制。容量限制用于控制环境中服务作业可使用的最大资源量。有关更多信息,请参阅 的服务环境 AWS Batch。
服务作业
服务作业是您提交 AWS Batch 以在服务环境中运行的一个工作单元。服务作业利用排 AWS Batch队和调度功能,同时将实际执行委托给外部服务。例如,作为服务作业提交的 SageMaker 训练作业由排队并按优先级排序 AWS Batch,但 SageMaker 训练作业的执行发生在 SageMaker AI 基础架构中。这种集成使数据科学家和机器学习工程师能够从 SageMaker AI 培训工作负载 AWS Batch的自动化工作负载管理和优先排队中受益。服务作业可以按名称或 ID 引用其他作业,并支持作业依赖项。有关更多信息,请参阅 中的服务职位 AWS Batch。
