优化 S3 Express One Zone 性能的最佳实践
构建从 Amazon S3 Express One Zone 上传和检索对象的应用程序时,请遵循最佳实践准则以优化性能。要使用 S3 Express One Zone 存储类,您必须创建 S3 目录存储桶。S3 Express One Zone 存储类不支持与 S3 通用存储桶一起使用。
有关其他所有 Amazon S3 存储类和 S3 通用存储桶的性能准则,请参阅最佳实践设计模式:优化 Amazon S3 性能。
要在大规模工作负载中使用 S3 Express One Zone 存储类和目录存储桶实现最佳性能和可扩展性,务必了解目录存储桶与通用存储桶的工作原理有何不同。然后,我们提供最佳实践,以使应用程序与目录存储桶的工作原理保持一致。
目录存储桶的工作原理
Amazon S3 Express One Zone 存储类对于每个目录存储桶可以支持高达每秒 2000000 个 GET 事务和 200000 个 PUT 事务(TPS)的工作负载。借助 S3 Express One Zone,数据存储在可用区内的 S3 目录存储桶中。目录存储桶中的对象可以在分层命名空间中访问,类似于文件系统,并与具有扁平命名空间的 S3 通用存储桶形成鲜明对比。与通用存储桶不同,目录存储桶将键分层组织到目录中,而不是前缀中。前缀是对象键名称开头的一串字符串。可以使用前缀来组织数据,并管理通用存储桶中的平面对象存储架构。有关更多信息,请参阅 使用前缀组织对象。
在目录存储桶中,使用正斜杠 (/) 作为唯一支持的分隔符,在分层命名空间中组织对象。当您使用类似于 dir1/dir2/file1.txt 的密钥上传对象时,Amazon S3 会自动创建和管理目录 dir1/ 和 dir2/。目录是在 PutObject 或 CreateMultiPartUpload 操作期间创建的,当这些目录在 DeleteObject 或 AbortMultiPartUpload 操作之后变为空时会被自动移除。目录中对象和子目录的数量没有上限。
在将对象上传到目录存储桶时创建的目录可以即时扩展,以减少出现 HTTP 503 (Slow Down) 错误的可能性。通过这种自动扩展,您的应用程序可以根据需要并行处理目录内和跨目录的读取和写入请求。对于 S3 Express One Zone,各个目录旨在支持目录存储桶的最大请求速率。无需随机化密钥前缀即可实现最佳性能,因为系统会自动分配对象以实现均匀的负载分配,但因此,密钥不会按字典顺序存储在目录存储桶中。这与 S3 通用存储桶形成鲜明对比,在这类存储桶中,按字典顺序更接近的密钥更有可能共存于同一台服务器上。
有关目录存储桶操作和目录交互的示例的更多信息,请参阅目录存储桶操作和目录交互示例。
最佳实践
遵循最佳实践来优化目录存储桶性能,并协助工作负载随时间推移而扩展。
使用包含许多条目(对象或子目录)的目录
默认情况下,目录存储桶可为所有工作负载提供高性能。为了进一步优化某些操作的性能,将更多条目(即对象或子目录)整合到目录中可以降低延迟和提高请求速率:
突变 API 操作(例如
PutObject、DeleteObject、CreateMultiPartUpload和AbortMultiPartUpload)在使用包含数千个条目的更少、更密集的目录而不是使用大量较小的目录来实现时,可以实现最佳性能。当需要遍历更少的目录来填充结果页时,
ListObjectsV2操作的性能会更好。
请勿在前缀中使用熵
在 Amazon S3 操作中,熵是指前缀命名的随机性,它有助于在存储桶间均匀分配工作负载。但是,由于目录存储桶在内部管理负载分布,因此建议不要在前缀中使用熵来实现最佳性能。这是因为对于目录存储桶,熵由于不重复使用已经创建的目录而导致请求速度变慢。
诸如 $HASH/directory/object 之类的密钥模式最终可能会创建许多中间目录。在以下示例中,所有 job-1 都是不同的目录,因为它们的父目录不同。目录将是稀疏的,且突变和列表请求会变慢。在此示例中,有 12 个中间目录,它们都有一个条目。
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
相反,为了获得更好的性能,我们可以移除 $HASH 组件,并支持 job-1 变为单个目录,从而提高目录的密度。在以下示例中,与前面的示例相比,具有 6 个条目的单个中间目录可以提高性能。
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
之所以会出现这种性能优势,是因为在最初创建对象键并且其键名称包含目录时,将自动为该对象创建该目录。后续对象上传到相同目录时不需要创建目录,这样可以减少将对象上传到现有目录的延迟。
如果在 ListObjectsV2 调用期间不需要对对象进行逻辑分组,请使用分隔符 / 以外的其它分隔符来分隔键的各个部分
由于 / 分隔符是专门针对目录存储桶处理的,因此应有意使用它。虽然目录存储桶不按字典顺序对对象进行排序,但目录中的对象在 ListObjectsV2 输出中仍会分组在一起。如果您不需要此功能,则可以将 / 替换为另一个字符作为分隔符,以避免创建中间目录。
例如,假设以下键采用 YYYY/MM/DD/HH/ 前缀模式
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
如果您不需要在 ListObjectsV2 结果中按小时或天对对象进行分组,但需要按月对对象进行分组,那么以下键模式 YYYY/MM/DD-HH- 将显著减少目录数并提高 ListObjectsV2 操作的性能。
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
尽可能使用分隔列表操作
不带 delimiter 的 ListObjectsV2 请求会对所有目录执行深度优先递归遍历。带有 delimiter 的 ListObjectsV2 请求仅检索由 prefix 参数指定的目录中的条目,从而减少了请求延迟并增加了每秒的聚合键数。对于目录存储桶,请尽可能使用分隔列表操作。分隔列表会减少访问目录的次数,从而增加每秒键数和减少请求延迟。
例如,对于目录存储桶中的以下目录和对象:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
为了提高 ListObjectsV2 性能,如果应用程序的逻辑支持,则可使用分隔列表来列出子目录和对象。例如,您可以对分隔列表操作运行以下命令:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
输出是子目录列表。
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
要列出性能更好的每个子目录,您可以运行类似以下示例的命令:
命令:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
输出:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
将 S3 Express One Zone 存储与您的 计算资源联合托管在一个位置
使用 S3 Express One Zone,每个目录存储桶均位于创建存储桶时选择的单个可用区中。首先,在计算工作负载或资源所在的可用区中,可以创建一个新的目录存储桶。然后就可以立即开始享受到延迟非常低的读取和写入。目录存储桶是一种 S3 存储桶类型,您可以在其中选择 AWS 区域中的可用区,以减少计算和存储之间的延迟。
如果您跨可用区访问目录存储桶,您可能会遇到延迟略有增加。为了优化性能,我们建议您尽可能从位于同一可用区的 Amazon Elastic Container Service、Amazon Elastic Kubernetes Service 和 Amazon Elastic Compute Cloud 实例访问目录存储桶。
使用并发连接对超过 1 MB 的对象实现高吞吐量
您可以将多个并行请求发送到目录存储桶,以便在不同的连接上分布请求,尽可能充分利用可用带宽,从而实现出色的性能。与通用存储桶类似,S3 Express One Zone 对与目录存储桶建立的连接数没有任何限制。在对同一目录进行大量并发写入操作时,这一目录可以横向自动扩展性能。
与目录存储桶的各个 TCP 连接对每秒可上传或下载的字节数有固定的上限。当对象变大时,请求时间将由字节流而不是事务处理主导。要使用多个连接来并行处理较大对象的上传或下载,您可以减少端到端延迟。如果使用 Java 2.x SDK,则应考虑使用 S3 Transfer Manager,它将利用性能改进(例如分段上传 API 操作和字节范围提取)来并行访问数据。
使用网关 VPC 端点
网关端点可提供从 VPC 到目录存储桶的直接连接,而无需为 VPC 提供互联网网关或 NAT 设备。为了减少数据包在网络上花费的时间量,应使用目录存储桶的网关 VPC 端点来配置 VPC。有关更多信息,请参阅 目录存储桶的联网。
使用会话身份验证,并在会话令牌有效时重用会话令牌
目录存储桶提供了一种会话令牌身份验证机制,以减少对性能敏感的 API 操作的延迟。您只需调用一次 CreateSession 即可获得会话令牌,该令牌在接下来的 5 分钟内对所有请求均有效。要在 API 调用中获得最低延迟,请务必获取会话令牌,并在该令牌的整个生命周期内重用该令牌,然后再刷新它。
如果您使用 AWS SDK,则 SDK 会自动处理会话令牌刷新,以避免在会话到期时服务中断。我们建议您使用 AWS SDK 来发起和管理对 CreateSession API 操作的请求。
有关 CreateSession 的更多信息,请参阅使用 CreateSession 对可用区端点 API 操作进行授权。
使用基于 CRT 的客户端
AWS 通用运行时(CRT)是一组用 C 语言编写的模块化、高性能和高效的库,旨在充当 AWS SDK 的基础。CRT 提供了改进的吞吐量、增强的连接管理和更快的启动时间。CRT 可通过除 Go 之外的所有 AWS SDK 获得。
有关如何为您使用的 SDK 配置 CRT 的更多信息,请参阅 AWS Common Runtime (CRT) libraries、Accelerate Amazon S3 throughput with the AWS Common Runtime
使用最新版本的 AWS SDK
AWS SDK 为许多用于优化 Amazon S3 性能的建议准则提供内置的支持。这些 SDK 提供了更简单的 API,以便从应用程序内部利用 Amazon S3,并定期更新以遵循最新的最佳实践。例如,SDK 会在 HTTP 503 错误之后自动重试请求,并处理慢速连接响应。
如果使用 Java 2.x SDK,则应考虑使用 S3 Transfer Manager,它会自动水平扩展连接,以便在适当时使用字节范围请求实现每秒数千个请求。字节范围请求可以提高性能,因为您可以使用到 S3 的并行连接,从相同对象中提取不同的字节范围。这有助于您通过单一整个对象请求实现更高的聚合吞吐量。因此,务必使用最新版本的 AWS SDK,以获取最新的性能优化功能。
性能故障排除
您是否要为延迟敏感型应用程序设置重试请求?
S3 Express One Zone 专为提供稳定的高性能而设计,无需额外调整。但是,设置更主动的超时值和重试次数可以进一步推动实现稳定的延迟和性能。AWS SDK 具有可配置的超时和重试值,您可以进行调整以符合特定应用程序的容限。
您是否要使用 AWS 通用运行时(CRT)库和最佳的 Amazon EC2 实例类型?
执行大量读取和写入操作的应用程序,相比不执行这些操作的应用程序会需要更多的内存或计算容量。在为具有高性能要求的工作负载启动 Amazon Elastic Compute Cloud(Amazon EC2)实例时,应选择具有您的应用程序需要的这些资源量的实例类型。S3 Express One Zone 高性能存储非常适合与更大、更新的实例类型搭配使用,这些实例类型具有更大的系统内存以及计算能力更强的 CPU 和 GPU,可以利用性能更高的存储。我们还建议使用启用了 CRT 的 AWS SDK 的最新版本,这样可以更好地加速并行读取和写入请求。
您是否要使用 AWS SDK 进行基于会话的身份验证?
借助 Amazon S3,在使用 HTTP REST API 请求时,您还可以遵循 AWS SDK 中相同的最佳实践,以此来优化性能。但是,对于 S3 Express One Zone 使用的基于会话的授权和身份验证机制,我们强烈建议您使用 AWS SDK 管理 CreateSession 及其托管会话令牌。AWS SDK 使用 CreateSession API 操作,自动代表您创建和刷新令牌。使用 CreateSession 可减少 AWS Identity and Access Management(IAM)授权各个请求的请求往返延迟。
目录存储桶操作和目录交互示例
以下显示了三个有关目录存储桶工作原理的示例。
示例 1:对目录存储桶的 S3 PutObject 请求如何与目录交互
-
在空存储桶中执行操作
PUT(<bucket>, "documents/reports/quarterly.txt")时,将创建存储桶根目录内的目录documents/,创建documents/内的目录reports/,并创建reports/内的对象quarterly.txt。对于此操作,除了对象之外,还创建了两个目录。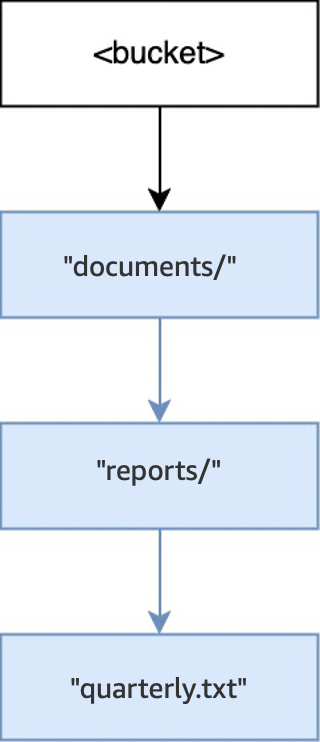
-
然后,当执行另一个操作
PUT(<bucket>, "documents/logs/application.txt")时,目录documents/已经存在,documents/中的目录logs/不存在并创建此目录,然后创建logs/中的对象application.txt。对于此操作,除了对象之外,只创建了一个目录。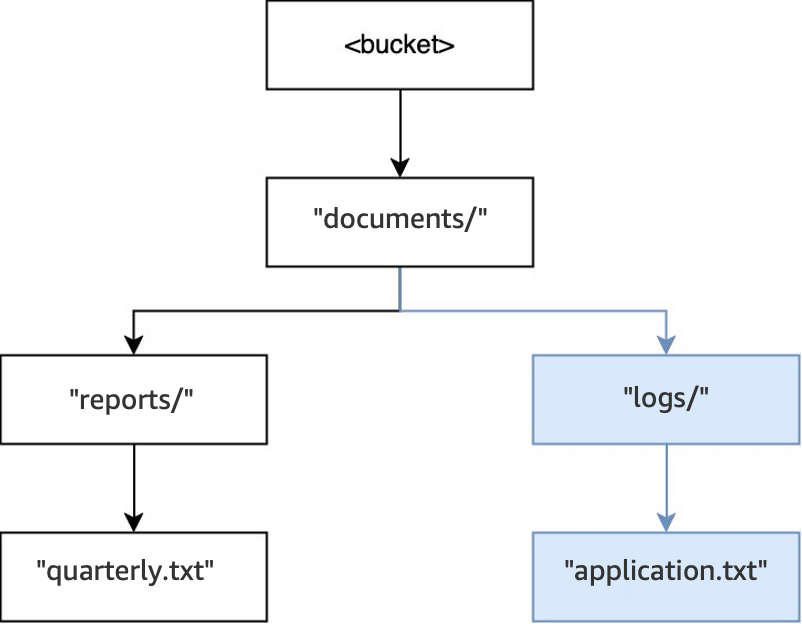
-
最后,当执行
PUT(<bucket>, "documents/readme.txt")操作时,根目录中的目录documents/已经存在,并创建对象readme.txt。对于此操作,未创建任何目录。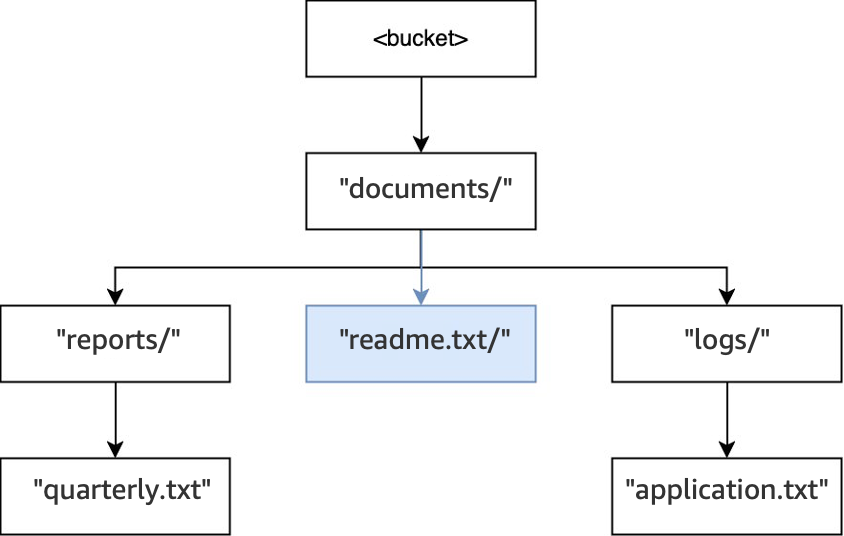
示例 2:对目录存储桶的 S3 ListObjectsV2 请求如何与目录交互
对于未指定分隔符的 S3 ListObjectsV2 请求,将以深度优先的方式遍历存储桶。输出以一致的顺序返回。但是,尽管此顺序在请求之间保持不变,但顺序不是按字典顺序排列的。对于在上一个示例中创建的存储桶和目录:
-
执行
LIST(<bucket>)时,将进入目录documents/并开始遍历。 -
进入
logs/子目录并开始遍历。 -
对象
application.txt位于logs/中。 -
logs/中没有更多条目。List 操作退出logs/并再次进入documents/。 -
继续遍历
documents/目录并找到对象readme.txt。 -
继续遍历
documents/目录,进入子目录reports/并开始遍历。 -
对象
quarterly.txt位于reports/中。 -
reports/中没有更多条目。List 退出reports/并再次进入documents/。 -
documents/中没有更多条目,List 将返回。
在此示例中,logs/ 的顺序排在 readme.txt 之前,readme.txt 的顺序排在 reports/ 之前。
示例 3:对目录存储桶的 S3 DeleteObject 请求如何与目录交互
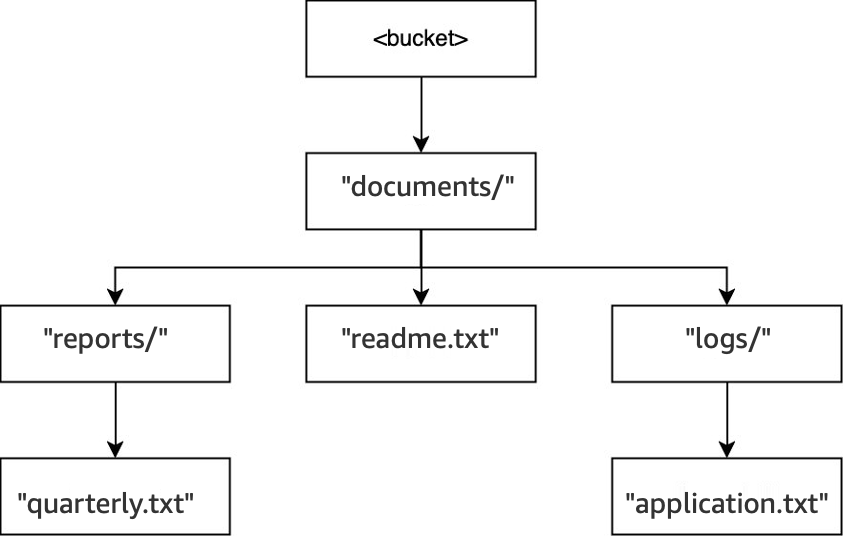
-
在该同一个存储桶中,当执行操作
DELETE(<bucket>, "documents/reports/quarterly.txt")时,将删除对象quarterly.txt,同时将目录reports/留空而导致立即将其删除。documents/目录不为空,因为该目录中同时具有目录logs/和对象readme.txt,所以不删除它。对于此操作,仅删除了一个对象和一个目录。
-
执行操作
DELETE(<bucket>, "documents/readme.txt")时,将删除对象readme.txt。documents/仍然不为空,因为它包含目录logs/,因此不删除它。对于此操作,未删除任何目录,而只删除该对象。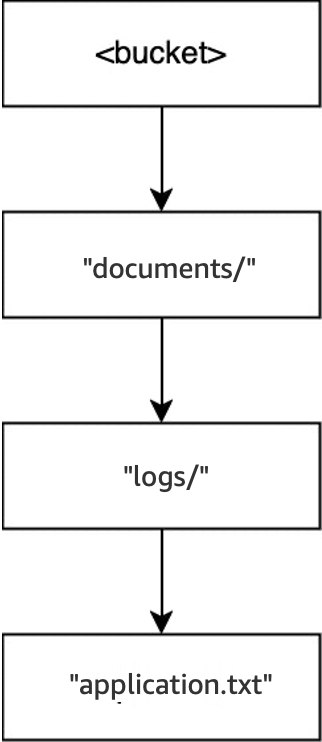
-
最后,当执行操作
DELETE(<bucket>, "documents/logs/application.txt")时,将删除application.txt,同时将logs/留空而导致立即将其删除。然后,这会将documents/留空而导致立即将其删除。对于此操作,删除两个目录和一个对象。存储桶现在为空。
