创建数据库集群
使用以下流程可创建使用 Aurora PostgreSQL Limitless Database 的 Aurora PostgreSQL 数据库集群。
您可以使用 AWS 管理控制台或 AWS CLI 来创建使用 Aurora PostgreSQL Limitless Database 的数据库集群。您可以创建主数据库集群和数据库分片组。
使用 AWS 管理控制台创建主数据库集群时,数据库分片组也会在相同的流程中创建。
使用控制台创建数据库集群
登录 AWS 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
选择创建数据库。
将显示创建数据库页面。
-
对于引擎类型,选择 Aurora(PostgreSQL 兼容)。
-
对于版本,请选择下列选项之一:
-
带 Limitless Database 的 Aurora PostgreSQL(兼容 PostgreSQL 16.4)
-
带 Limitless Database 的 Aurora PostgreSQL(兼容 PostgreSQL 16.6)
-
-
对于 Aurora PostgreSQL Limitless Database:
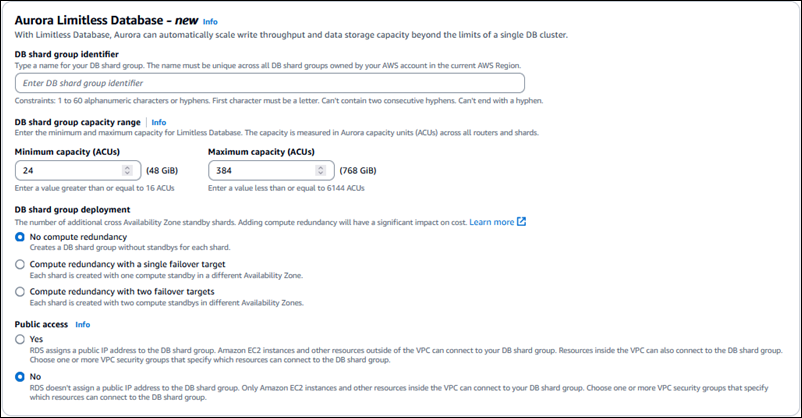
-
输入数据库分片组标识符。
重要
创建数据库分片组后,您将无法更改数据库集群标识符或数据库分片组标识符。
-
对于数据库分片组容量范围:
-
输入最小容量(ACU)。最小值为 16 ACU。
对于开发环境,默认值为 16 ACU。对于生产环境,默认值为 24 ACU。
-
输入最大容量(ACU)。使用至少 16 ACU 或最多 6144 ACU 的值。
对于开发环境,默认值为 64 ACU。对于生产环境,默认值为 384 ACU。
有关更多信息,请参阅 将数据库分片组的最大容量与创建的路由器和分片的数量相关联。
-
-
对于数据库分片组部署,选择是否为数据库分片组创建备用数据库:
-
没有计算冗余 – 为每个分片创建没有备用数据库的数据库分片组。这是默认值。
-
使用单个失效转移目标计算冗余 – 在不同的可用区(AZ)中创建带有一个计算备用数据库的数据库分片组。
-
使用两个失效转移目标计算冗余 – 在两个不同的可用区中创建带有两个计算备用数据库的数据库分片组。
注意
如果将计算冗余设置为非零值,则数据库实例的分片总数将增加一倍或两倍。这些额外的数据库实例是计算备用实例,可以纵向扩展和缩减到与写入器实例相同的容量。您无需为备用数据库单独设置容量范围。因此,ACU 用量和账单相应地增加一倍和两倍。要了解计算冗余产生的确切 ACU 用量,请参阅 DBShardGroup 指标中的
DBShardGroupComputeRedundancyCapacity指标。 -
-
选择是否可以公开访问数据库分片组。
注意
创建数据库分片组之后,您将无法修改此设置。
-
-
对于连接:
-
(可选)选择连接到 EC2 计算资源,然后选择现有 EC2 实例或创建新实例。
注意
如果您连接到 EC2 实例,则无法公开访问该数据库分片组。
-
对于网络类型,选择 IPv4 或双栈模式。
-
选择虚拟私有云(VPC)和数据库子网组,或者使用默认设置。
注意
如果在美国东部(弗吉尼亚州北部)区域创建 Limitless Database 数据库集群,请不要将
us-east-1e可用区(AZ)包含在数据库子网组中。由于资源限制,us-east-1e可用区不支持 Aurora serverless,因此也不支持 Limitless Database。 -
选择 VPC 安全组(防火墙),或使用默认设置。
-
-
对于数据库身份验证,选择密码身份验证或密码和 IAM 数据库身份验证。
-
对于监控,请确保选中启用性能详情 和启用增强监控复选框。
对于性能详情,请选择至少 1 个月的保留时间。
-
展开页面底部的其他配置。
-
对于日志导出,请确保选中 PostgreSQL 日志复选框。
-
根据需要指定其他设置。有关更多信息,请参阅 Aurora 数据库集群的设置。
-
选择创建数据库。
创建主数据库集群和数据库分片组后,它们将显示在数据库页面上。

使用 AWS CLI 创建使用 Aurora PostgreSQL Limitless Database 的数据库集群时,您需要执行以下任务:
创建主数据库集群
创建数据库集群需要以下参数:
-
--db-cluster-identifier– 数据库集群的名称。 -
--engine– 数据库集群必须使用aurora-postgresql数据库引擎。 -
--engine-version– 数据库集群必须使用的数据库引擎版本之一:-
16.4-limitless -
16.6-limitless
-
-
--storage-type– 数据库集群必须使用aurora-iopt1数据库集群存储配置。 -
--cluster-scalability-type– 指定 Aurora 数据库集群的可扩展性模式。设置为limitless时,集群将作为 Aurora PostgreSQL Limitless Database 运行。设置为standard(默认)时,集群使用正常的数据库实例创建。注意
创建数据库集群之后,您将无法修改此设置。
-
--master-username– 数据库集群的主用户名称。 -
--master-user-password– 主用户的密码。 -
--enable-performance-insights– 必须启用性能详情。 -
--performance-insights-retention-period– 性能详情的保留期必须至少为 31 天。 -
--monitoring-interval– 收集数据库集群的增强监控指标的时间点之间的间隔,以秒为单位。该值不能为0。 -
--monitoring-role-arn– 允许 RDS 将增强监控指标发送到 Amazon CloudWatch Logs 的 IAM 角色的 Amazon 资源名称(ARN)。 -
--enable-cloudwatch-logs-exports– 您必须将postgresql日志导出到 CloudWatch 日志。
以下参数可选:
-
--db-subnet-group-name– 要与该数据库集群关联的数据库子网组。这也决定了与数据库集群关联的 VPC。注意
如果在美国东部(弗吉尼亚州北部)区域创建 Limitless Database 数据库集群,请不要将
us-east-1e可用区(AZ)包含在数据库子网组中。由于资源限制,us-east-1e可用区不支持 Aurora serverless,因此也不支持 Limitless Database。 -
--vpc-security-group-ids– 要与数据库集群关联的 VPC 安全组的列表。 -
--performance-insights-kms-key-id– 用于加密性能详情数据的 AWS KMS key 标识符。如果未指定 KMS 密钥,则使用您 AWS 账户 的默认密钥。 -
--region– 创建数据库集群的 AWS 区域。它必须支持 Aurora PostgreSQL Limitless Database。
要使用默认 VPC 和 VPC 安全组,请忽略 --db-subnet-group-name 和 --vpc-security-group-ids 选项。
创建主数据库集群
-
aws rds create-db-cluster \ --db-cluster-identifiermy-limitless-cluster\ --engine aurora-postgresql \ --engine-version 16.6-limitless \ --storage-type aurora-iopt1 \ --cluster-scalability-type limitless \ --master-usernamemyuser\ --master-user-passwordmypassword\ --db-subnet-group-namemysubnetgroup\ --vpc-security-group-idssg-c7e5b0d2\ --enable-performance-insights \ --performance-insights-retention-period31\ --monitoring-interval5\ --monitoring-role-arn arn:aws:iam::123456789012:role/EMrole\ --enable-cloudwatch-logs-exports postgresql
有关更多信息,请参阅 create-db-cluster
创建数据库分片组
接下来,在刚创建的数据库集群中创建数据库分片组。以下参数为必需参数:
-
--db-shard-group-identifier– 数据库分片组的名称。数据库分片组标识符具有以下限制:
-
它在创建它的 AWS 区域和 AWS 账户中必须是唯一的。
-
必须包含 1-63 个字母、数字或连字符。
-
第一个字符必须是字母。
-
它不能以连字符结尾,也不能包含两个连续连字符。
-
重要
创建数据库分片组后,您将无法更改数据库集群标识符或数据库分片组标识符。
-
-
--db-cluster-identifier– 要在其中创建数据库分片组的数据库集群的名称。 -
--max-acu– 数据库分片组的最大容量。必须是 16-6144 ACU。如果容量限制高于 6144 ACU,请联系 AWS。初始路由器和分片数量由您在创建数据库分片组时设置的最大容量决定。最大容量越大,在数据库分片组中创建的路由器和分片的数量就越多。有关更多信息,请参阅 将数据库分片组的最大容量与创建的路由器和分片的数量相关联。
以下参数可选:
-
--compute-redundancy– 是否为数据库分片组创建备用数据库。此参数可能具有以下值:-
0– 为每个分片创建没有备用数据库的数据库分片组。这是默认值。 -
1– 在不同的可用区(AZ)中创建带有一个计算备用数据库的数据库分片组。 -
2– 在两个不同的可用区中创建带有两个计算备用数据库的数据库分片组。
注意
如果将计算冗余设置为非零值,则分片总数将增加一倍或两倍。这将产生额外费用。
计算备用数据库中的节点会扩展和缩减到与写入器相同的容量。您无需为备用数据库单独设置容量范围。
-
-
--min-acu– 数据库分片组的最小容量。它必须至少为 16 ACU,这是默认值。 -
--publicly-accessible|--no-publicly-accessible– 是否向数据库分片组分配可公开访问的 IP 地址。对数据库分片组的访问由集群使用的安全组控制。默认值为
--no-publicly-accessible。注意
创建数据库分片组之后,您将无法修改此设置。
创建数据库分片组
-
aws rds create-db-shard-group \ --db-shard-group-identifiermy-db-shard-group\ --db-cluster-identifier my-limitless-cluster \ --max-acu1000
