Amazon S3 buckets
Research and Engineering Studio (RES) supports mounting Amazon S3 buckets to Linux Virtual Desktop Infrastructure (VDI) instances. RES Administrators can onboard S3 buckets to RES, attach them to projects, edit their configuration, and remove buckets in the S3 buckets tab under Environment Management.
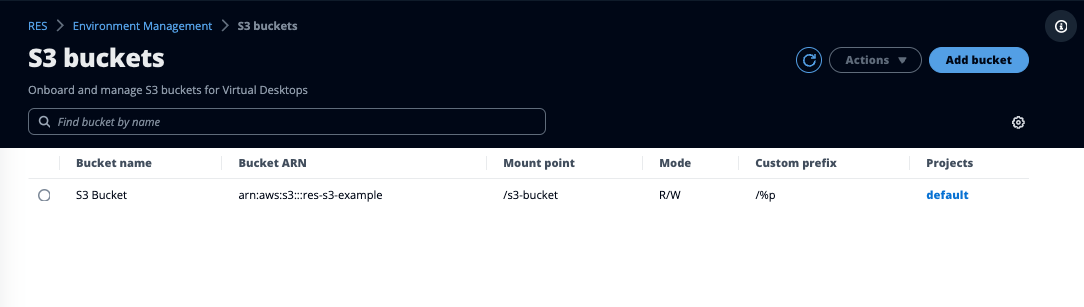
The S3 buckets dashboard provides a list of onboarded S3 buckets available to you. From the S3 buckets dashboard, you can:
-
Use Add bucket to onboard an S3 bucket to RES.
-
Select an S3 bucket and use the Actions menu to:
-
Edit a bucket
-
Remove a bucket
-
-
Use the search field to search by Bucket name and find onboarded S3 buckets.
The following sections describe how to manage Amazon S3 buckets in your RES projects.
Topics
