As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Independência da zona de disponibilidade
Para alcançar o primeiro resultado, ou seja, parar de enviar trabalho para a zona de disponibilidade afetada, a evacuação exige que você implemente a Independência da zona de disponibilidade
Em um workload do tipo solicitação/resposta, a implementação da AZI exige que você desative o balanceamento de carga entre zonas dos Application Load Balancers (ALB), Classic Load Balancers (CLB) e Network Load Balancers (NLB) (o balanceamento de carga entre zonas fica desativado por padrão para NLBs). Desabilitar balanceamento de carga entre zonas tem algumas desvantagens. Quando você desativa o balanceamento de carga entre zonas, o tráfego é dividido uniformemente entre cada zona de disponibilidade, independentemente de quantas instâncias estejam em cada zona. Se você tiver recursos desbalanceados ou grupos do Auto Scaling, isso pode sobrecarregar os recursos em uma zona de disponibilidade com menos recursos que outras. Isso é mostrado na figura a seguir, onde duas instâncias na zona de disponibilidade 1 estão recebendo 25% da carga e as cinco instâncias na zona de disponibilidade 2 estão recebendo 10% da carga cada uma.
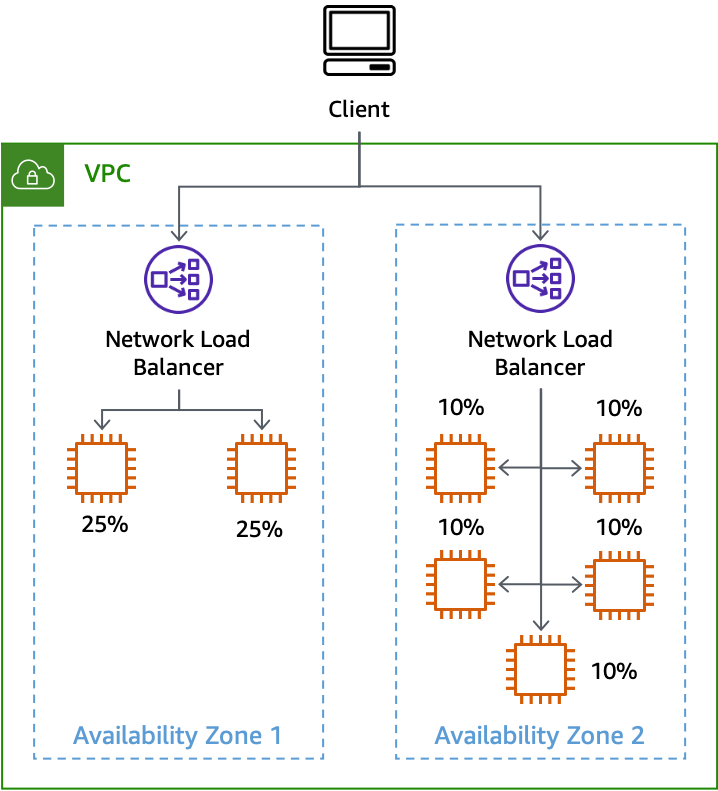
O efeito da desativação do balanceamento de carga entre zonas com instâncias desbalanceadas
Outros serviços zonais que você usa também precisarão ser implementados usando padrões AZI para apoiar a evacuação efetiva da zona de disponibilidade. Por exemplo, os endpoints da VPC de interface fornecem nomes DNS específicos para cada zona de disponibilidade na qual o endpoint da interface é disponibilizado.
Um desafio com a implementação da AZI é com bancos de dados, especialmente porque a maioria dos bancos de dados relacionais suporta apenas um único gravador primário a qualquer momento. Ao se comunicar com a instância primária, talvez seja necessário cruzar o limite da zona de disponibilidade. Muitos serviços de banco de dados AWS oferecem suporte a uma configuração multi-AZ definida pelo usuário e têm um atributo de failover multi-AZ integrado, como Amazon RDS ou Amazon Aurora. Em muitos cenários de falha, o serviço pode detectar o impacto e fazer o failover automático do banco de dados para uma zona de disponibilidade diferente quando ocorre um problema. No entanto, durante uma falha cinzenta, o serviço pode não detectar o impacto que está afetando o workload ou o impacto pode não estar relacionado ao banco de dados. Nesses casos, depois de detectar o impacto em uma zona de disponibilidade, você pode invocar manualmente um failover para mover o banco de dados principal. Isso permite que você reaja de forma eficaz a um simples comprometimento da zona de disponibilidade.
Se você estiver usando réplicas de leitura com esses bancos de dados, talvez também queira implementar a AZI para eles, pois não é possível fazer o failover de uma réplica de leitura para uma zona de disponibilidade diferente, como acontece com o banco de dados primário. Se você tiver uma única réplica de leitura na zona de disponibilidade 1 e as instâncias de três zonas de disponibilidade estiverem configuradas para usá-la, um comprometimento que esteja afetando a zona de disponibilidade 1 também afetará as operações nas outras duas zonas de disponibilidade. Esse é o impacto que você quer evitar.
Para instâncias do RDS, você recebe um endpoint DNS para acessar a réplica em uma zona de disponibilidade específica. Para obter a AZI, você precisa de uma réplica de leitura por zona de disponibilidade e de seu aplicativo saber, de alguma maneira, qual endpoint de réplica usar para a zona de disponibilidade em que está. Uma abordagem que você pode adotar é usar o ID da zona de disponibilidade como parte do identificador do banco de dados, algo como use1-az1-read-replica.cbkdgoeute4n.us-east-1.rds.amazonaws.com. Você também pode fazer isso usando a descoberta de serviços (como com AWS Cloud Map
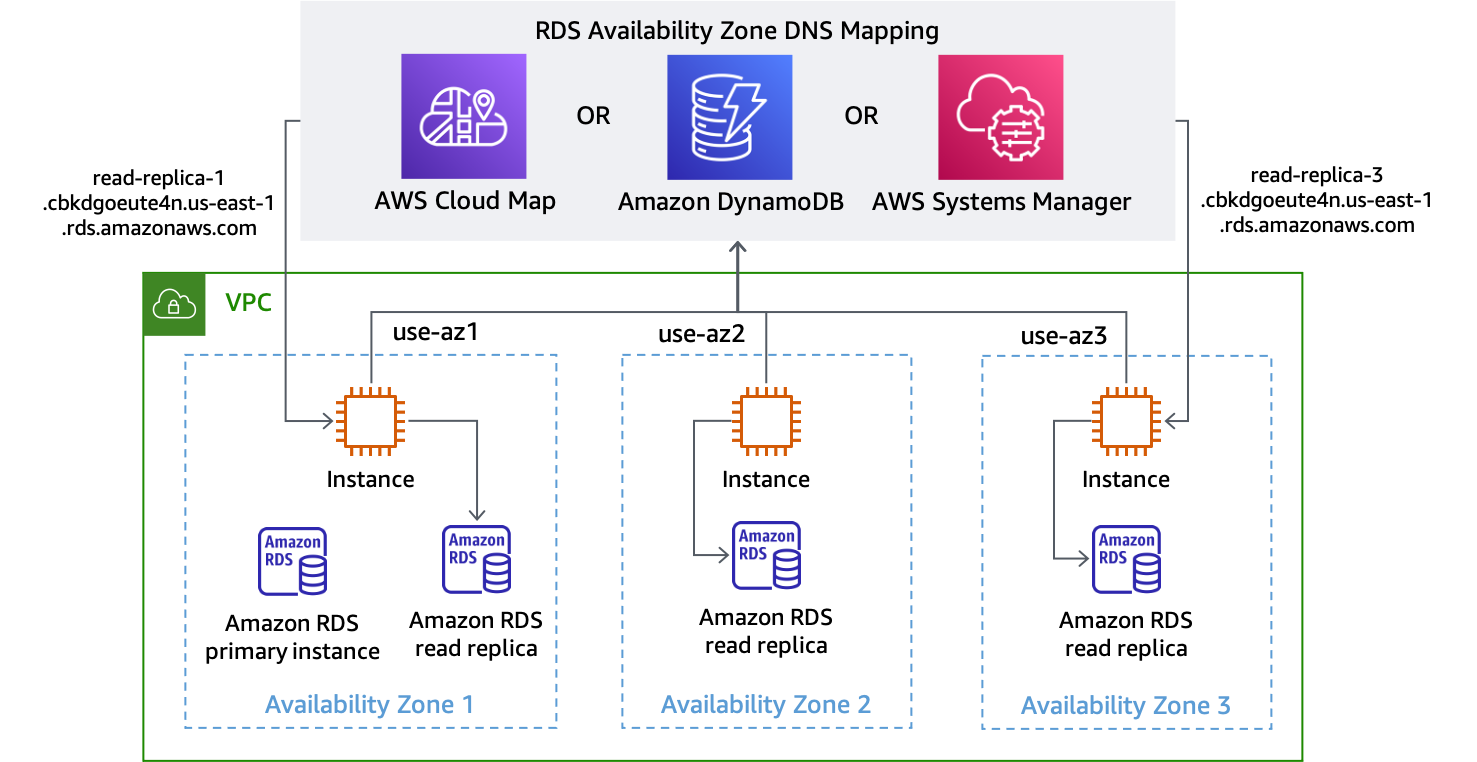
Descoberta de nomes DNS de endpoints do RDS para cada zona de disponibilidade
A configuração padrão do Amazon Aurora é fornecer um único endpoint de leitura que equilibra a carga das solicitações entre as réplicas de leitura disponíveis. Para implementar a AZI usando o Aurora, você pode usar um endpoint personalizado para cada réplica de leitura usando o tipo ANY (para viabilizar a promoção de uma réplica de leitura, se necessário). Atribua um nome ao endpoint personalizado com base na ID da zona de disponibilidade em que a réplica será implantada. Em seguida, você pode usar o nome DNS fornecido pelo endpoint personalizado para se conectar a uma réplica de leitura específica em uma zona de disponibilidade específica, como mostra a figura a seguir.
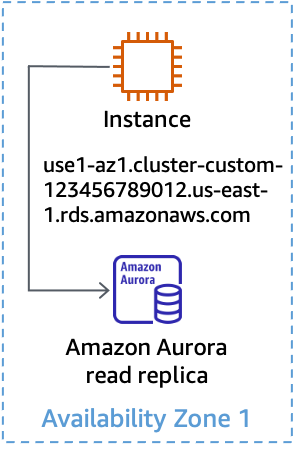
Uso de um endpoint personalizado para uma réplica de leitura do Aurora
Quando seu sistema é arquitetado dessa forma, a evacuação da zona de disponibilidade torna-se uma tarefa muito mais simples. Por exemplo, na figura a seguir, quando há um comprometimento afetando a zona de disponibilidade 3, as operações de leitura e gravação nas zonas de disponibilidade 1 e 2 não são afetadas.
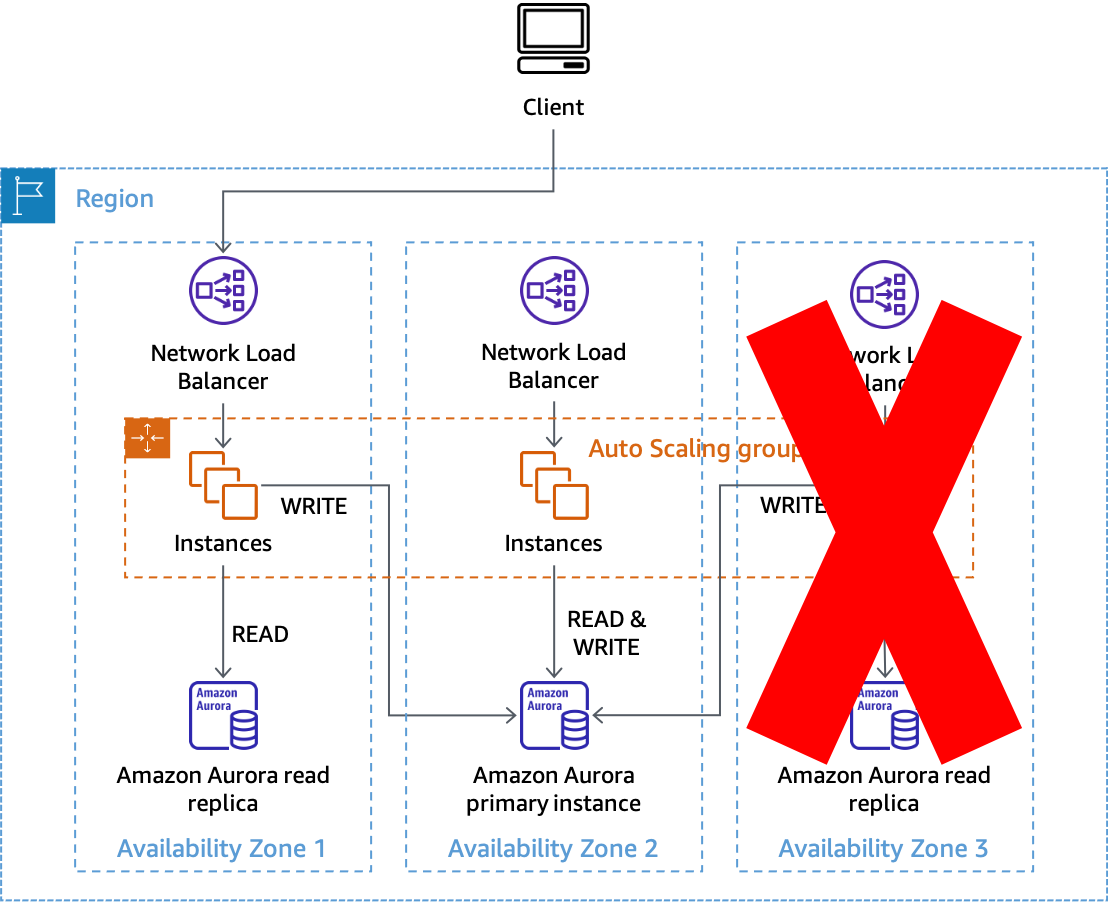
Usando a AZI para evitar impactos com réplicas de leitura do Amazon Aurora
Como alternativa, se a zona de disponibilidade 2 fosse afetada, as operações de leitura ainda seriam bem-sucedidas nas zonas de disponibilidade 1 e 3. Então, se o Amazon Aurora não fizer o failover automático do banco de dados principal, você poderá invocar manualmente um failover para uma zona de disponibilidade diferente para restaurar a capacidade de processamento de gravações. Essa abordagem evita a necessidade de fazer alterações na configuração das conexões do banco de dados quando for necessário evacuar uma zona de disponibilidade. Ao minimizar as mudanças necessárias e manter o processo o mais simples possível o tornará mais confiável.
