As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Enfileiramento de tarefas
Usando o enfileiramento de tarefas, você pode enviar mais solicitações de trabalhos de transcrição do que as que podem ser processadas simultaneamente. Sem o enfileiramento de tarefas, quando você atinge a cota de solicitações simultâneas permitidas, é necessário esperar até que uma ou mais solicitações sejam concluídas para só então enviar uma nova solicitação.
O enfileiramento de tarefas é opcional tanto para solicitações de tarefas de transcrição quanto para solicitações de tarefas de análise pós-chamada.
Se você habilitar o enfileiramento de trabalhos, Amazon Transcribe cria uma fila que contém todas as solicitações que excedem seu limite. Assim que uma solicitação é concluída, uma nova solicitação é retirada da fila e processada. As solicitações enfileiradas são processadas na ordem FIFO (primeiro a entrar, primeiro a sair).
Você pode adicionar até dez mil trabalhos à fila. Se você exceder esse limite, receberá um erro LimitExceededConcurrentJobException. Para manter o desempenho ideal, usa Amazon Transcribe apenas até 90% da sua cota (uma taxa de largura de banda de 0,9) para processar trabalhos em fila. Observe que esses são valores padrão que podem ser aumentados por meio de uma solicitação.
dica
Você pode encontrar uma lista de limites e cotas padrão para Amazon Transcribe recursos na Referência AWS geral. Alguns desses padrões podem ser aumentados por meio de uma solicitação.
Se você habilitar o enfileiramento de tarefas, mas não exceder a cota de solicitações simultâneas, todas as solicitações serão processadas simultaneamente.
Habilitar o enfileiramento de tarefas
Você pode habilitar o enfileiramento de tarefas usando o Console de gerenciamento da AWS, a AWS CLI ou SDKs da AWS . Consulte os exemplos a seguir:
-
Faça login no Console de gerenciamento da AWS
. -
No painel de navegação, escolha Tarefas de transcrição e selecione Criar tarefa (no canto superior direito). Isso abre a página Especificar os detalhes da tarefa.
-
Na caixa Configurações de tarefa, há o painel Configurações adicionais. Se você expandir esse painel, poderá selecionar a caixa Adicionar à fila de tarefas para habilitar o enfileiramento de tarefas.
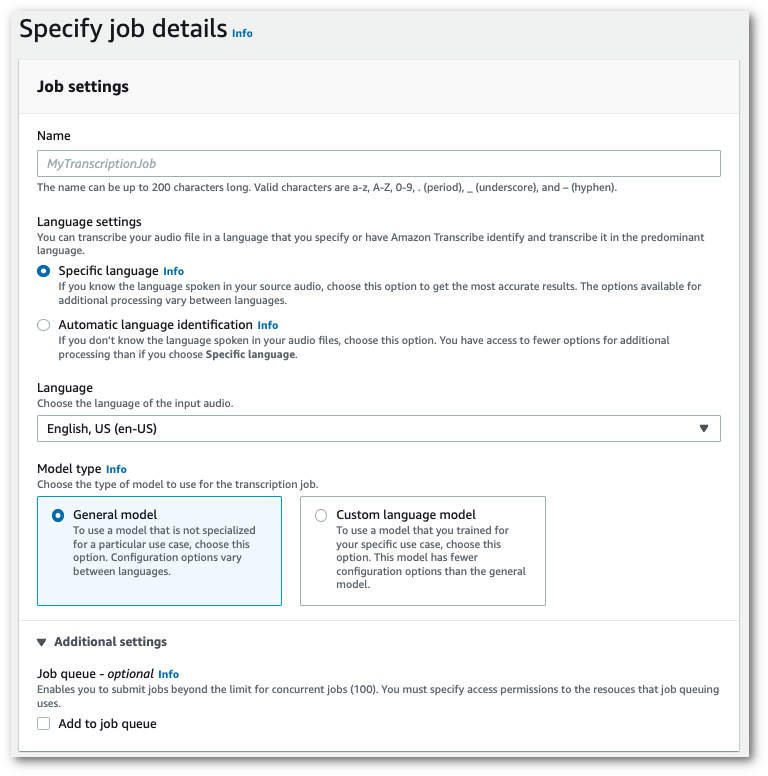
-
Preencha os outros campos que deseja incluir na página Especificar os detalhes da tarefa e selecione Próximo. Isso leva você à página Configurar tarefa: opcional.
-
Selecione Criar tarefa para executar a tarefa de transcrição.
Este exemplo usa o comando start-transcription-jobjob-execution-settings com o subparâmetro AllowDeferredExecution. Observe que, ao incluir AllowDeferredExecution na solicitação, você também deve incluir DataAccessRoleArn.
Para obter mais informações, consulte StartTranscriptionJob e JobExecutionSettings.
aws transcribe start-transcription-job \ --regionus-west-2\ --transcription-job-namemy-first-transcription-job\ --media MediaFileUri=s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac\ --output-bucket-nameamzn-s3-demo-bucket\ --output-keymy-output-files/ \ --language-codeen-US\ --job-execution-settings AllowDeferredExecution=true,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole
Veja a seguir outro exemplo usando o comando start-transcription-job
aws transcribe start-transcription-job \ --regionus-west-2\ --cli-input-json file://my-first-queueing-request.json
O arquivo my-first-queueing-request.json contém o corpo de solicitação a seguir.
{ "TranscriptionJobName": "my-first-transcription-job", "Media": { "MediaFileUri": "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" }, "OutputBucketName": "amzn-s3-demo-bucket", "OutputKey": "my-output-files/", "LanguageCode": "en-US", "JobExecutionSettings": { "AllowDeferredExecution": true, "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" } }
Este exemplo usa o AWS SDK para Python (Boto3) para habilitar o enfileiramento de trabalhos usando o AllowDeferredExecution argumento do método start_transcription_jobAllowDeferredExecution na solicitação, você também deve incluir DataAccessRoleArn. Para obter mais informações, consulte StartTranscriptionJob e JobExecutionSettings.
Para ver exemplos adicionais de uso dos AWS SDKs, incluindo exemplos específicos de recursos, cenários e entre serviços, consulte o capítulo. Exemplos de código para o Amazon Transcribe usando AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') job_name = "my-first-queueing-request" job_uri = "s3://amzn-s3-demo-bucket/my-input-files/my-media-file.flac" transcribe.start_transcription_job( TranscriptionJobName = job_name, Media = { 'MediaFileUri': job_uri }, OutputBucketName = 'amzn-s3-demo-bucket', OutputKey = 'my-output-files/', LanguageCode = 'en-US', JobExecutionSettings = { 'AllowDeferredExecution': True, 'DataAccessRoleArn': 'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_transcription_job(TranscriptionJobName = job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Você pode visualizar o progresso de um trabalho em fila por meio do Console de gerenciamento da AWS ou enviando uma solicitação. GetTranscriptionJob Quando um trabalho está na fila, o Status é QUEUED. O status muda para IN_PROGRESS quando o trabalho começa a ser processado e, em seguida, muda para COMPLETED ou FAILED quando o processamento é concluído.
