As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Criar um modelo de idioma personalizado
Antes de criar um modelo de idioma personalizado, você deve:
-
Preparar seus dados. Os dados devem ser salvos em formato de texto sem formatação e não podem conter caracteres especiais.
-
Carregue seus dados em um Amazon S3 bucket. É recomendável criar pastas separadas para dados de treinamento e ajuste.
-
Certifique-se de Amazon Transcribe ter acesso ao seu Amazon S3 bucket. Você deve especificar uma IAM função que tenha permissões de acesso para usar seus dados.
Preparar seus dados
Você pode compilar todos os dados em um arquivo ou salvá-los como vários arquivos. Observe que, se você optar por incluir dados de ajuste, eles deverão ser salvos em um arquivo separado dos dados de treinamento.
Não importa quantos arquivos de texto são usados para os dados de treinamento ou ajuste. Carregar um arquivo com dez mil palavras produz o mesmo resultado que carregar dez arquivos com dez mil palavras. Prepare seus dados de texto da forma mais conveniente para você.
Todos os arquivos de dados devem atender aos seguintes critérios:
-
Todos estão no mesmo idioma do modelo que você deseja criar. Por exemplo, se você quiser criar um modelo de idioma personalizado que transcreva áudio em inglês dos EUA (
en-US), todos os dados de texto deverão estar em inglês dos EUA. -
Eles estão em formato de texto simples com UTF-8 codificação.
-
Eles não contêm nenhum caractere especial nem formatação, como tags HTML.
-
Ao todo, eles têm um total máximo de 2 GB para dados de treinamento e 200 MB para dados de ajuste.
Se algum desses critérios não for atendido, o modelo falhará.
Carregar seus dados
Antes de carregá-los, crie uma pasta para os dados de treinamento. Se estiver usando dados de ajuste, crie outra pasta separada.
Os URIs dos buckets podem ter a seguinte aparência:
-
s3://amzn-s3-demo-bucket/my-model-training-data/ -
s3://amzn-s3-demo-bucket/my-model-tuning-data/
Carregue os dados de treinamento e ajuste nos buckets apropriados.
Você pode adicionar mais dados a esses buckets posteriormente. No entanto, se você fizer isso, precisará recriar o modelo com os novos dados. Os modelos existentes não podem ser atualizados com novos dados.
Permitir acesso aos seus dados
Para criar um modelo de linguagem personalizado, você deve especificar uma IAM função que tenha permissões para acessar seu Amazon S3 bucket. Se você ainda não tem uma função com acesso ao Amazon S3 bucket em que colocou seus dados de treinamento, você deve criar uma. Depois de criar uma função, é possível anexar uma política para conceder permissões a essa função. Não anexe uma política a um usuário.
Para obter exemplos de políticas, consulte Amazon Transcribe exemplos de políticas baseadas em identidade.
Para saber como criar uma nova IAM identidade, consulte IAM Identidades (usuários, grupos de usuários e funções).
Para saber mais sobre as políticas do IAM, consulte:
Criar um modelo de idioma personalizado
Ao criar seu modelo de idioma personalizado, você deve escolher um modelo básico. Há duas opções de modelo básico:
-
NarrowBand: use essa opção para áudio com uma taxa de amostragem inferior a 16.000 Hz. Esse tipo de modelo é normalmente usado para conversas telefônicas gravadas a 8.000 Hz. -
WideBand: use essa opção para áudio com uma taxa de amostragem maior ou igual a 16.000 Hz.
Você pode criar modelos de linguagem personalizados usando os AWS SDKs Console de gerenciamento da AWS AWS CLI, ou.; veja os exemplos a seguir:
-
Faça login no Console de gerenciamento da AWS
. -
No painel de navegação, selecione Modelo de idioma personalizado. Isso abre a página Modelos de idioma personalizados, na qual você pode visualizar os modelos de idioma personalizados existentes ou treinar um modelo de idioma personalizado.
-
Para treinar um novo modelo, selecione Treinar modelo.
Isso leva você para a página Treinar modelo. Adicione um nome, especifique o idioma e escolha o modelo básico que você deseja para o modelo. Em seguida, adicione o caminho ao seu treinamento e, opcionalmente, seus dados de ajuste. Você deve incluir uma IAM função que tenha permissões para acessar seus dados.
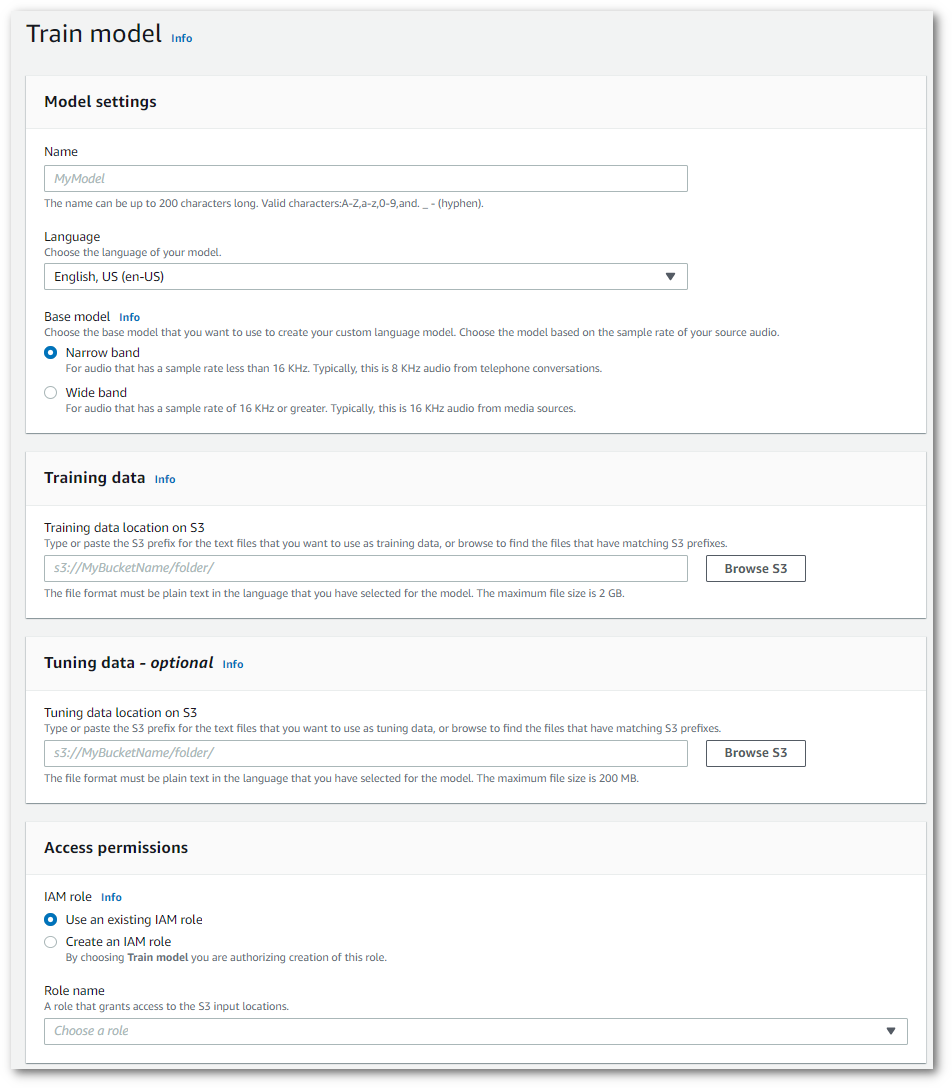
-
Depois de preencher todos os campos, selecione Treinar modelo na parte inferior da página.
Este exemplo usa o comando create-language-modelCreateLanguageModel e LanguageModel.
aws transcribe create-language-model \ --base-model-nameNarrowBand\ --model-namemy-first-language-model\ --input-data-config S3Uri=s3://amzn-s3-demo-bucket/my-clm-training-data/,TuningDataS3Uri=s3://amzn-s3-demo-bucket/my-clm-tuning-data/,DataAccessRoleArn=arn:aws:iam::111122223333:role/ExampleRole\ --language-codeen-US
Veja outro exemplo usando o comando create-language-model
aws transcribe create-language-model \ --cli-input-json file://filepath/my-first-language-model.json
O arquivo my-first-language-model.json contém o corpo de solicitação a seguir.
{ "BaseModelName": "NarrowBand", "ModelName": "my-first-language-model", "InputDataConfig": { "S3Uri": "s3://amzn-s3-demo-bucket/my-clm-training-data/", "TuningDataS3Uri"="s3://amzn-s3-demo-bucket/my-clm-tuning-data/", "DataAccessRoleArn": "arn:aws:iam::111122223333:role/ExampleRole" }, "LanguageCode": "en-US" }
Este exemplo usa o AWS SDK para Python (Boto3) para criar um CLM usando o método create_language_modelCreateLanguageModel e LanguageModel.
Para ver exemplos adicionais de uso dos AWS SDKs, incluindo exemplos específicos de recursos, cenários e entre serviços, consulte o capítulo. Exemplos de código para o Amazon Transcribe usando AWS SDKs
from __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe', 'us-west-2') model_name = 'my-first-language-model', transcribe.create_language_model( LanguageCode = 'en-US', BaseModelName = 'NarrowBand', ModelName = model_name, InputDataConfig = { 'S3Uri':'s3://amzn-s3-demo-bucket/my-clm-training-data/', 'TuningDataS3Uri':'s3://amzn-s3-demo-bucket/my-clm-tuning-data/', 'DataAccessRoleArn':'arn:aws:iam::111122223333:role/ExampleRole' } ) while True: status = transcribe.get_language_model(ModelName = model_name) if status['LanguageModel']['ModelStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)
Atualizar o modelo de idioma personalizado
Amazon Transcribe atualiza continuamente os modelos básicos disponíveis para modelos de linguagem personalizados. Para se beneficiar dessas atualizações, recomendamos treinar novos modelos de idioma personalizados a cada 6 a 12 meses.
Para ver se seu modelo de linguagem personalizada está usando o modelo base mais recente, execute uma DescribeLanguageModelsolicitação usando o AWS CLI ou um AWS SDK e encontre o UpgradeAvailability campo em sua resposta.
Se UpgradeAvailability for true, o modelo não está executando a versão mais recente do modelo básico. Para usar o modelo básico mais recente em um modelo de idioma personalizado, você deve criar um modelo de idioma personalizado. Os modelos de idioma personalizados não podem ser atualizados.
