Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Agregados simples em nível de frota
Este primeiro exemplo mostra alguns dos conceitos básicos ao trabalhar com consultas agendadas usando um exemplo simples de computação de agregados em nível de frota. Ao utilizar esse exemplo, você aprenderá conforme a seguir.
-
Como fazer a consulta do painel usada para obter estatísticas agregadas e mapeá-la para uma consulta agendada.
-
Como o Timestream for LiveAnalytics gerencia a execução das diferentes instâncias de sua consulta agendada.
-
Como é possível permitir a sobreposição de diferentes instâncias de consultas agendadas em determinados períodos e, ao mesmo tempo, garantir a precisão dos dados na tabela de destino, de modo que o painel que utiliza os resultados da consulta agendada apresente resultados que correspondam ao mesmo agregado calculado nos dados brutos.
-
Como definir o intervalo de tempo e a cadência de atualização para sua consulta agendada.
-
Como é possível monitorar por conta própria os resultados das consultas agendadas para ajustá-las de forma que a latência de execução das instâncias de consulta esteja dentro dos prazos aceitáveis de atualização de seus painéis.
Tópicos
Agregar a partir de tabelas de origem
Neste exemplo, você está rastreando o número de métricas emitidas pelos servidores em uma determinada região em cada minuto. O gráfico abaixo é um exemplo de traçar essa série temporal para a região us-east-1.
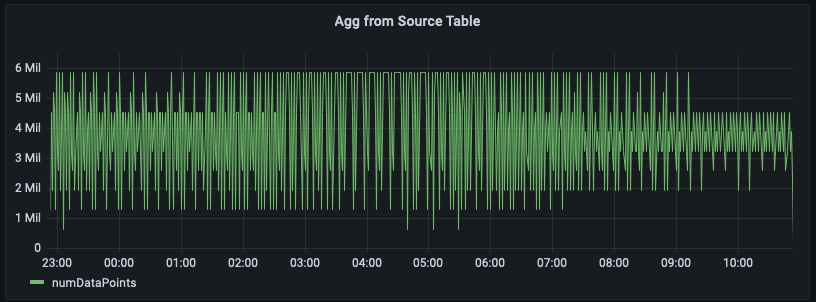
Abaixo está um exemplo de consulta para calcular esse agregado a partir dos dados brutos. Ele filtra as linhas da região us-east-1 e, em seguida, calcula a soma por minuto contabilizando as 20 métricas (se o measure_name for métrica) ou 5 eventos (se omeasure_name for eventos). Neste exemplo, a ilustração gráfica mostra que o número de métricas emitidas varia entre 1,5 milhão e 6 milhões por minuto. Ao traçar essa série temporal por várias horas (últimas 12 horas nesta figura), essa consulta sobre os dados brutos analisa centenas de milhões de linhas.
WITH grouped_data AS ( SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY region, measure_name, bin(time, 1m) ) SELECT minute, SUM(numDataPoints) AS numDataPoints FROM grouped_data GROUP BY minute ORDER BY 1 desc, 2 desc
Consulta agendada para pré-computar agregados
Caso queira otimizar seus painéis para carregar mais rápido e reduzir seus custos digitalizando menos dados, você pode usar uma consulta agendada para pré-computar esses agregados. As consultas agendadas no Timestream for LiveAnalytics permitem que você materialize esses pré-cálculos em outro Timestream for LiveAnalytics table, que você pode usar posteriormente em seus painéis.
A primeira etapa na criação de uma consulta agendada é identificar a consulta que você deseja pré-computar. Observe que o painel anterior foi desenhado para a região us-east-1. No entanto, um usuário diferente pode querer o mesmo agregado para uma região diferente, por exemplo us-west-2 ou eu-west-1. Para evitar a criação de uma consulta agendada para cada consulta, você pode pré-calcular o agregado para cada região e materializar os agregados por região em outro Timestream para tabela. LiveAnalytics
A consulta abaixo fornece um exemplo da pré-computação correspondente. Como é possível observar, é semelhante à expressão de tabela comum grouped_data usada na consulta dos dados brutos, exceto por duas diferenças: 1) ela não usa um predicado de região, de modo que podemos usar uma consulta para pré-computar para todas as regiões; e 2) ela usa um predicado de tempo parametrizado com um parâmetro especial @scheduled_runtime, que é explicado em detalhes abaixo.
SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region
A consulta anterior pode ser convertida em uma consulta agendada usando a especificação a seguir. A consulta agendada recebe um Nome, que é um mnemônico fácil de usar. Em seguida, inclui o QueryString, a ScheduleConfiguration, que é uma expressão cron. Ele especifica o TargetConfiguration que mapeia os resultados da consulta para a tabela de destino no Timestream for. LiveAnalytics Por fim, ele especifica várias outras configurações, como a NotificationConfiguration, em que as notificações são enviadas para execuções individuais da consulta, ErrorReportConfiguration em que um relatório é escrito caso a consulta encontre algum erro e a ScheduledQueryExecutionRoleArn, que é a função usada para realizar operações para a consulta agendada.
{ "Name": "MultiPT5mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/5 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt5m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
No exemplo, o ScheduleExpression cron (0/5 * * *? *) implica que a consulta seja executada uma vez a cada 5 minutos nos dias 5, 10, 15,.. minutos de cada hora de cada dia. Esses registros de data e hora, quando uma instância específica dessa consulta é acionada, correspondem ao parâmetro @scheduled_runtime empregado na consulta. Por exemplo, considere o caso desta consulta agendada para ser executada em 2021-12-01 às 00:00:00. Neste caso, o parâmetro @scheduled_runtime é inicializado com o registro de data/hora 2021-12-01 00:00:00 ao invocar a consulta. Portanto, essa instância específica será executada no timestamp 2021-12-01 00:00:00 e calculará os agregados por minuto do intervalo de tempo 2021-11-30 23:50:00 a 2021-12-01 00:01:00. Da mesma forma, a próxima instância dessa consulta é acionada no timestamp 2021-12-01 00:05:00 e, nesse caso, a consulta computará agregados por minuto a partir do intervalo de tempo 2021-11-30 23:55:00 a 2021-12-01 00:06:00. Assim, o parâmetro @scheduled_runtime oferece uma consulta agendada para realizar o pré-cálculo dos agregados para os períodos de tempo definidos, utilizando o momento de chamada das consultas.
Observe que duas instâncias subsequentes da consulta se sobrepõem em seus intervalos de tempo. Isso é algo possível de controlar dependendo das suas necessidades. Nesse caso, essa sobreposição permite que essas consultas atualizem os agregados com base em qualquer dado cuja chegada tenha sido um pouco atrasada, até 5 minutos neste exemplo. Para garantir a exatidão das consultas materializadas, o Timestream for LiveAnalytics garante que a consulta em 01/12/2021 00:05:00 seja executada somente após a conclusão da consulta em 01/12/2021 00:00:00 e que os resultados das últimas consultas possam atualizar qualquer agregado materializado anteriormente usando se um valor mais novo for gerado. Por exemplo, se alguns dados no timestamp 2021-11-30 23:59:00 chegarem após a consulta de 2021-12-01 00:00:00 ser executada, mas antes da consulta de 2021-12-01 00:05:00, a execução em 2021-12-01 00:05:00 recalculará os agregados do minuto 2021-11-30 23:59:00 e isso resultará na atualização do agregado anterior com o valor recém-calculado. Você pode confiar nessa semântica das consultas agendadas para equilibrar a velocidade da atualização dos seus pré-cálculos e a maneira como você gerencia dados que chegam com atraso. Considerações adicionais são discutidas abaixo sobre como você troca essa cadência de atualização com a atualização dos dados e como você aborda a atualização dos agregados por dados que chegam ainda mais atrasados ou se sua fonte de computação programada tem valores atualizados que exigiriam que os agregados fossem recalculados.
Cada computação programada tem uma configuração de notificação em que o Timestream for LiveAnalytics envia uma notificação de cada execução de uma configuração agendada. É possível configurar um tópico do SNS para receber notificações para cada invocação. Além do status de sucesso ou falha de uma instância específica, ela também tem várias estatísticas, como o tempo que essa computação levou para ser executada, o número de bytes que a computação verificou e o número de bytes que a computação gravou na tabela de destino. Essas estatísticas podem ser utilizadas para refinar ainda mais sua consulta, programar a configuração ou acompanhar os custos associados às suas consultas agendadas. Um aspecto digno de nota é o tempo de execução de uma instância. Neste exemplo, a computação programada é configurada para ser executada a cada cinco minutos. O tempo de execução determinará o atraso com o qual a pré-computação estará disponível, o que também definirá o atraso em seu painel quando você estiver usando os dados pré-computados em seus painéis. Além disso, se esse atraso for consistentemente maior do que o intervalo de atualização, por exemplo, se o tempo de execução for superior a 5 minutos para uma computação configurada para ser atualizada a cada 5 minutos, é importante ajustar sua computação para ser executada mais rapidamente para evitar mais atrasos em seus painéis.
Agregar da tabela derivada
Agora que você configurou as consultas agendadas e os agregados estão pré-computados e materializados em outro Timestream para a LiveAnalytics tabela especificada na configuração de destino da computação agendada, você pode usar os dados dessa tabela para escrever consultas SQL para alimentar seus painéis. Abaixo está um equivalente da consulta que usa os pré-agregados materializados para gerar o agregado de contagem de pontos de dados por minuto para us-east-1.
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996445) AND from_milliseconds(1636743196445) AND region = 'us-east-1' GROUP BY bin(time, 1m) ORDER BY 1 desc
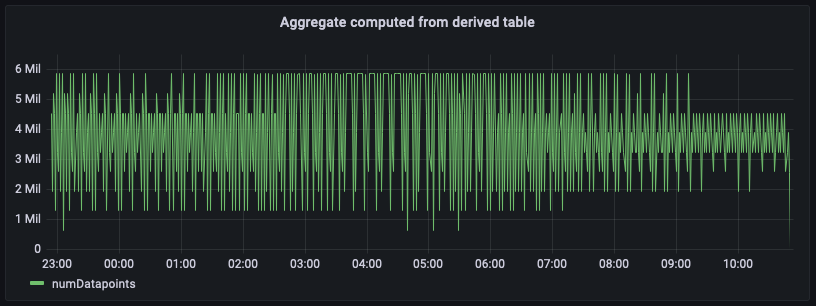
A figura anterior traça o agregado calculado a partir da tabela agregada. Comparando esse painel com o painel calculado a partir dos dados brutos da fonte, você notará que eles coincidem exatamente, embora esses agregados sejam atrasados em alguns minutos, controlados pelo intervalo de atualização que você configurou para o cálculo agendado mais o tempo para executá-lo.
Essa consulta sobre os dados pré-computados digitaliza dados de várias ordens de magnitude menores em comparação com os agregados calculados nos dados de origem bruta. Dependendo da granularidade das agregações, essa redução pode facilmente resultar em 100 vezes menos custo e latência de consulta. A execução dessa computação programada tem um custo. No entanto, dependendo da frequência com que esses painéis são atualizados e de quantos usuários simultâneos os carregam, você acaba reduzindo significativamente seus custos gerais usando esses pré-cálculos. E isso se soma aos tempos de carregamento de 10 a 100 vezes mais rápidos para os painéis.
Combinação agregada de tabelas de origem e derivadas
Os painéis criados usando as tabelas derivadas podem ter um atraso. Se o cenário do seu aplicativo exigir que os painéis tenham os dados mais recentes, você poderá usar o poder e a flexibilidade do suporte SQL LiveAnalytics do Timestream for para combinar os dados mais recentes da tabela de origem com os agregados históricos da tabela derivada para formar uma exibição mesclada. Essa exibição mesclada usa a semântica de união do SQL e intervalos de tempo não sobrepostos da tabela de origem e da tabela derivada. No exemplo abaixo, estamos usando a tabela derivada “derived ”.” per_minute_aggs_pt5m”. Como a computação programada para essa tabela derivada é atualizada a cada cinco minutos (conforme especificado na expressão de agendamento), a consulta a seguir utiliza os dados mais recentes da tabela de origem dos últimos 15 minutos e quaisquer dados anteriores a 15 minutos da tabela derivada. Em seguida, os resultados são combinados para criar uma exibição mesclada que oferece o melhor dos dois mundos: economia e baixa latência ao acessar agregados pré-computados mais antigos da tabela derivada, além da atualização da agregação da tabela de origem para otimizar seus casos de uso de análise em tempo real.
É importante observar que essa estratégia de união apresentará uma latência de consulta um pouco maior em relação à consulta que considera apenas a tabela derivada. Além disso, os dados digitalizados também serão um pouco mais altos, uma vez que os dados brutos são processados em tempo real para preencher o intervalo de tempo mais recente. Da mesma forma, ao usar a exibição mesclada para combinar a tabela derivada, você consulta os custos nessa exibição, e a latência de carregamento do painel será maior do que na consulta que envolve somente a tabela derivada. Como é possível ajustar os intervalos de tempo deste exemplo para atender às necessidades de atualização e à tolerância a atrasos do seu aplicativo.
WITH aggregated_source_data AS ( SELECT bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDatapoints FROM "raw_data"."devops" WHERE time BETWEEN bin(from_milliseconds(1636743196439), 1m) - 15m AND from_milliseconds(1636743196439) AND region = 'us-east-1' GROUP BY bin(time, 1m) ), aggregated_derived_data AS ( SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt5m" WHERE time BETWEEN from_milliseconds(1636699996439) AND bin(from_milliseconds(1636743196439), 1m) - 15m AND region = 'us-east-1' GROUP BY bin(time, 1m) ) SELECT minute, numDatapoints FROM ( ( SELECT * FROM aggregated_derived_data ) UNION ( SELECT * FROM aggregated_source_data ) ) ORDER BY 1 desc
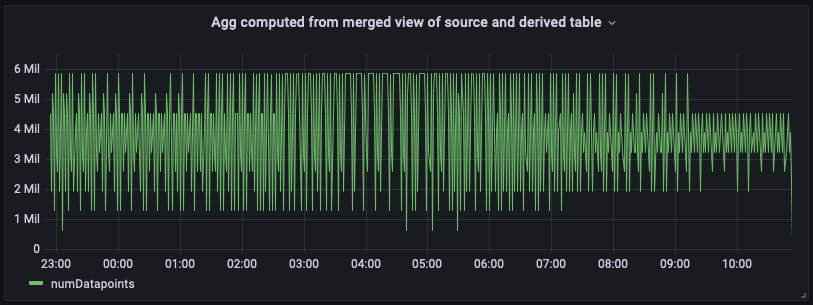
Abaixo está o painel do painel com essa visualização unificada e mesclada. Como você pode ver, o painel parece quase idêntico à exibição calculada a partir da tabela derivada, exceto pelo fato de que ele terá a maior quantidade up-to-date agregada na ponta mais à direita.
Agregado a partir de cálculos programados frequentemente atualizados
Dependendo da frequência com que seus painéis são carregados e da latência que você deseja para seu painel, há outra abordagem para obter resultados mais recentes em seu painel: fazer com que a computação programada atualize os agregados com mais frequência. Por exemplo, abaixo está a configuração da mesma computação programada, exceto que ela é atualizada uma vez a cada minuto (observe a programação expressa cron (0/1 * * *? *)). Com essa configuração, a tabela derivada per_minute_aggs_pt1m terá agregados muito mais recentes em comparação com o cenário em que o cálculo especificou um cronograma de atualização de uma vez a cada 5 minutos.
{ "Name": "MultiPT1mPerMinutePerRegionMeasureCount", "QueryString": "SELECT region, bin(time, 1m) as minute, SUM(CASE WHEN measure_name = 'metrics' THEN 20 ELSE 5 END) as numDataPoints FROM raw_data.devops WHERE time BETWEEN @scheduled_runtime - 10m AND @scheduled_runtime + 1m GROUP BY bin(time, 1m), region", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/1 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "per_minute_aggs_pt1m", "TimeColumn": "minute", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "numDataPoints", "MultiMeasureAttributeMappings": [ { "SourceColumn": "numDataPoints", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
SELECT bin(time, 1m) as minute, SUM(numDataPoints) as numDatapoints FROM "derived"."per_minute_aggs_pt1m" WHERE time BETWEEN from_milliseconds(1636699996446) AND from_milliseconds(1636743196446) AND region = 'us-east-1' GROUP BY bin(time, 1m), region ORDER BY 1 desc
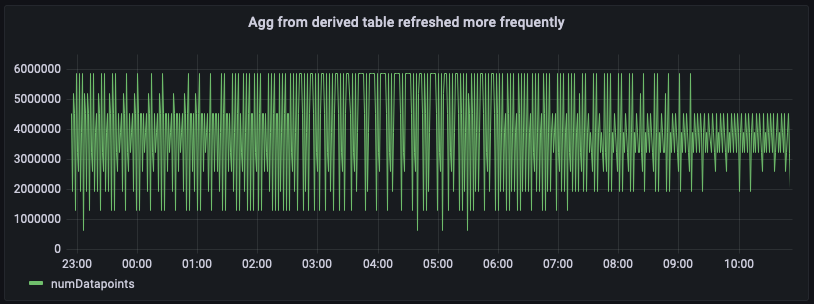
Como a tabela derivada tem agregados mais recentes, agora você consegue consultar diretamente a tabela derivada per_minute_aggs_pt1m para obter agregados mais recentes, como pode ser visto na consulta anterior e no instantâneo do painel abaixo.
Note que a atualização da computação programada para uma velocidade maior (por exemplo, 1 minuto em vez de 5 minutos) elevará os custos de manutenção da computação programada. A mensagem de notificação para a execução de cada computação fornece estatísticas de quantos dados foram digitalizados e quantos foram gravados na tabela derivada. Da mesma forma, ao utilizar a exibição mesclada para combinar a tabela derivada, você consulta os custos na exibição mesclada, e a latência de carregamento do painel será maior em relação à consulta que envolve apenas a tabela derivada. Portanto, a abordagem escolhida dependerá da frequência com que seus painéis são atualizados e dos custos de manutenção das consultas agendadas. Se você tiver dezenas de usuários atualizando os painéis aproximadamente uma vez a cada minuto, uma atualização mais frequente da tabela derivada provavelmente resultará em custos gerais mais baixos.
