Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimização de custos compartilhando consultas agendadas entre painéis
Neste exemplo, veremos um cenário em que vários painéis exibem variações de informações semelhantes (encontrando altos hosts de CPU e uma fração da frota com alta utilização da CPU) e como é possível usar a mesma consulta agendada para pré-computar resultados que são usados para preencher vários painéis. Essa reutilização otimiza ainda mais seus custos, pois, em vez de usar consultas agendadas diferentes, uma para cada painel, você usa apenas o proprietário.
Painéis de painel com dados brutos
Utilização da CPU por região por microsserviço
O primeiro painel calcula as instâncias cuja utilização média da CPU é um limite abaixo ou acima da utilização da CPU acima para determinada implantação em uma região, célula, silo, zona de disponibilidade e microsserviço. Em seguida, ele classifica a região e o microsserviço que tem a maior porcentagem de hosts com alta utilização. Ajuda a identificar a temperatura dos servidores de uma implantação específica e, posteriormente, detalhar para entender melhor os problemas.
A consulta do painel demonstra a flexibilidade do suporte SQL LiveAnalytics do Timestream for para realizar tarefas analíticas complexas com expressões de tabela, funções de janela, junções e assim por diante comuns.

Consulte:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526593876) AND from_milliseconds(1636612993876) AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization) * 100.0 / COUNT(*), 0) AS percent_low_utilization_hosts FROM instances_above_threshold GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
Aprofunde-se em um microsserviço para encontrar pontos de acesso
O próximo painel permite que você se aprofunde em um dos microsserviços para descobrir qual região, célula e silo específicos desse microsserviço está executando qual fração de sua frota com maior utilização da CPU. Por exemplo, no painel geral da frota, você viu o microsserviço demeter aparecer nas primeiras posições do ranking, então, neste painel, você deseja aprofundar-se nesse microsserviço.
Esse painel usa uma variável para escolher o microsserviço para detalhamento, e os valores da variável são preenchidos usando valores exclusivos da dimensão. Depois de escolher o microsserviço, o restante do painel é atualizado.
Conforme apresentado abaixo, o primeiro painel apresenta a porcentagem de hosts em uma implantação (uma região, célula e silo para um microsserviço) ao longo do tempo, juntamente com a consulta utilizada para gerar o painel. Esse gráfico em si identifica uma implantação específica com maior porcentagem de hosts com alta CPU.

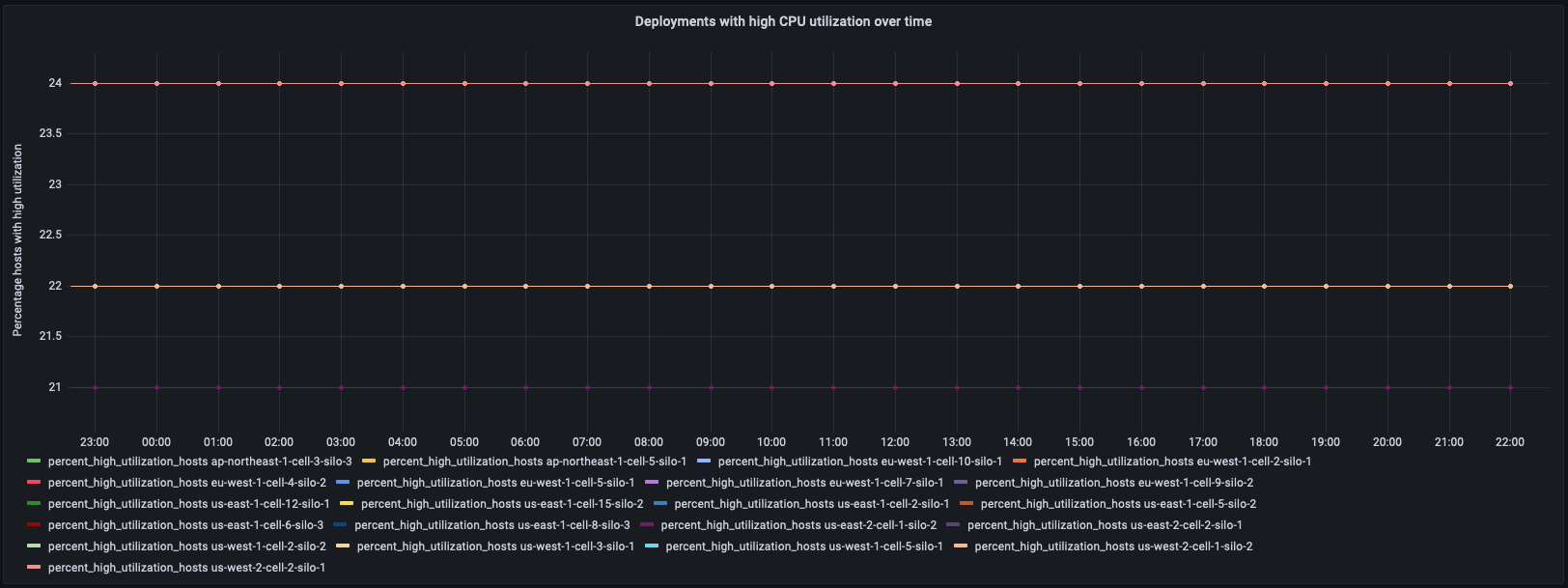
Consulta:
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM "raw_data"."devops" WHERE time BETWEEN from_milliseconds(1636526898831) AND from_milliseconds(1636613298831) AND measure_name = 'metrics' AND microservice_name = 'demeter' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ), high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, ROUND(SUM(high_utilization) * 100.0 / COUNT(*), 0) AS percent_high_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
Conversão em uma única consulta agendada, permitindo a reutilização
É importante observar que um cálculo semelhante é feito nos diferentes painéis dos dois painéis. É possível definir uma consulta agendada separada para cada painel. Aqui você verá como otimizar ainda mais seus custos definindo uma consulta agendada cujos resultados podem ser usados para renderizar todos os três painéis.
A seguir está a consulta que captura os agregados que são calculados e usados em todos os diferentes painéis. Você observará vários aspectos importantes na definição dessa consulta agendada.
-
A flexibilidade e a potência da área de superfície SQL suportadas por consultas agendadas, nas quais você consegue usar expressões comuns de tabela, junções, declarações de caso etc.
-
É possível utilizar uma consulta agendada para realizar cálculos estatísticos com uma precisão mais refinada do que a que um painel específico pode requerer, bem como para todos os dados que um painel pode empregar em relação a diversas variáveis. Por exemplo, você verá que os agregados são computados em uma região, célula, silo e microsserviço. Portanto, é possível combiná-los para criar agregados em nível de região, região e microsserviços. Da mesma forma, a mesma consulta calcula os agregados para todas as regiões, células, silos e microsserviços. Permite que você aplique filtros nessas colunas para obter os agregados de um subconjunto dos valores. Por exemplo, é possível calcular os agregados para qualquer região, digamos us-east-1, ou qualquer microsserviço, digamos, demeter ou detalhar uma implantação específica em uma região, célula, silo e microsserviço. Essa abordagem otimiza ainda mais seus custos de manutenção dos agregados pré-computados.
WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour
Veja a seguir uma definição de consulta agendada para a consulta anterior. A expressão de agendamento é estabelecida para ser atualizada a cada 30 minutos e renova os dados de até uma hora anterior, utilizando novamente a estrutura bin (@scheduled_runtime, 1h) para recuperar os eventos correspondentes a uma hora completa. Dependendo dos requisitos de atualização do seu aplicativo, é possível configurá-lo para ser atualizado com mais ou menos frequência. Ao usar WHERE time BETWEEN bin (@scheduled_runtime, 1h) - 1h AND bin (@scheduled_runtime, 1h) + 1h, é possível garantir que, mesmo se você atualizar a cada 15 minutos, receberá os dados completos da hora atual e da hora anterior.
Posteriormente, você verá como os três painéis usam esses agregados gravados na tabela deployment_cpu_stats_per_hr para visualizar as métricas que são relevantes para o painel.
{ "Name": "MultiPT30mHighCpuDeploymentsPerHr", "QueryString": "WITH microservice_cell_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, bin(time, 1h) as hour, AVG(cpu_user) AS microservice_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, bin(time, 1h) ), instance_avg AS ( SELECT region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) as hour, AVG(cpu_user) AS instance_avg_metric FROM raw_data.devops WHERE time BETWEEN bin(@scheduled_runtime, 1h) - 1h AND bin(@scheduled_runtime, 1h) + 1h AND measure_name = 'metrics' GROUP BY region, cell, silo, availability_zone, microservice_name, instance_name, bin(time, 1h) ), instances_above_threshold AS ( SELECT i.*, CASE WHEN i.instance_avg_metric > (1 + 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS high_utilization, CASE WHEN i.instance_avg_metric < (1 - 0.2) * m.microservice_avg_metric THEN 1 ELSE 0 END AS low_utilization FROM instance_avg i INNER JOIN microservice_cell_avg m ON i.region = m.region AND i.cell = m.cell AND i.silo = m.silo AND i.availability_zone = m.availability_zone AND m.microservice_name = i.microservice_name AND m.hour = i.hour ) SELECT region, cell, silo, microservice_name, hour, COUNT(*) AS num_hosts, SUM(high_utilization) AS high_utilization_hosts, SUM(low_utilization) AS low_utilization_hosts FROM instances_above_threshold GROUP BY region, cell, silo, microservice_name, hour", "ScheduleConfiguration": { "ScheduleExpression": "cron(0/30 * * * ? *)" }, "NotificationConfiguration": { "SnsConfiguration": { "TopicArn": "******" } }, "TargetConfiguration": { "TimestreamConfiguration": { "DatabaseName": "derived", "TableName": "deployment_cpu_stats_per_hr", "TimeColumn": "hour", "DimensionMappings": [ { "Name": "region", "DimensionValueType": "VARCHAR" }, { "Name": "cell", "DimensionValueType": "VARCHAR" }, { "Name": "silo", "DimensionValueType": "VARCHAR" }, { "Name": "microservice_name", "DimensionValueType": "VARCHAR" } ], "MultiMeasureMappings": { "TargetMultiMeasureName": "cpu_user", "MultiMeasureAttributeMappings": [ { "SourceColumn": "num_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "high_utilization_hosts", "MeasureValueType": "BIGINT" }, { "SourceColumn": "low_utilization_hosts", "MeasureValueType": "BIGINT" } ] } } }, "ErrorReportConfiguration": { "S3Configuration" : { "BucketName" : "******", "ObjectKeyPrefix": "errors", "EncryptionOption": "SSE_S3" } }, "ScheduledQueryExecutionRoleArn": "******" }
Painel de resultados pré-computados
Hosts de alta utilização da CPU
Para os hosts de alta utilização, você verá como os diferentes painéis usam os dados de deployment_cpu_stats_per_hr para calcular os diferentes agregados necessários para os painéis. Por exemplo, esses painéis fornecem informações em nível de região, portanto, relatam agregados agrupados por região e microsserviço, sem filtrar nenhuma região ou microsserviço.
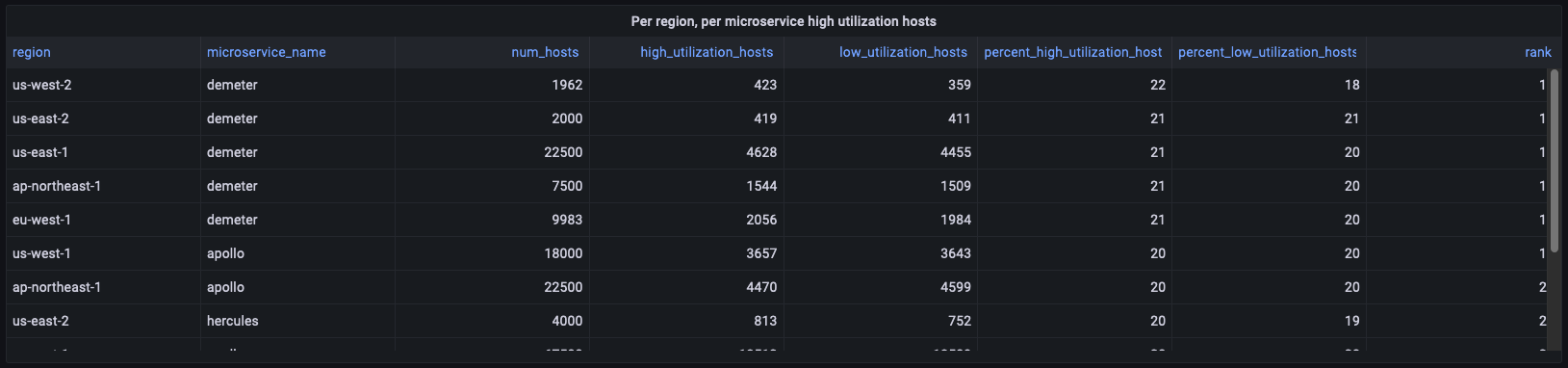
WITH per_deployment_hosts AS ( SELECT region, cell, silo, microservice_name, AVG(num_hosts) AS num_hosts, AVG(high_utilization_hosts) AS high_utilization_hosts, AVG(low_utilization_hosts) AS low_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636567785437) AND from_milliseconds(1636654185437) AND measure_name = 'cpu_user' GROUP BY region, cell, silo, microservice_name ), per_deployment_high AS ( SELECT region, microservice_name, SUM(num_hosts) AS num_hosts, ROUND(SUM(high_utilization_hosts), 0) AS high_utilization_hosts, ROUND(SUM(low_utilization_hosts),0) AS low_utilization_hosts, ROUND(SUM(high_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_high_utilization_hosts, ROUND(SUM(low_utilization_hosts) * 100.0 / SUM(num_hosts)) AS percent_low_utilization_hosts FROM per_deployment_hosts GROUP BY region, microservice_name ), per_region_ranked AS ( SELECT *, DENSE_RANK() OVER (PARTITION BY region ORDER BY percent_high_utilization_hosts DESC, high_utilization_hosts DESC) AS rank FROM per_deployment_high ) SELECT * FROM per_region_ranked WHERE rank <= 2 ORDER BY percent_high_utilization_hosts desc, rank asc
Aprofunde-se em um microsserviço para encontrar implantações de alto uso da CPU
O exemplo subsequente utiliza novamente a tabela derivada deployment_cpu_stats_per_hr, entretanto, aplica uma filtragem voltada para um microsserviço específico, nomeadamente o demeter, que apresentou hosts com elevada utilização no painel consolidado. Esse painel rastreia a porcentagem de hosts com alta utilização da CPU ao longo do tempo.
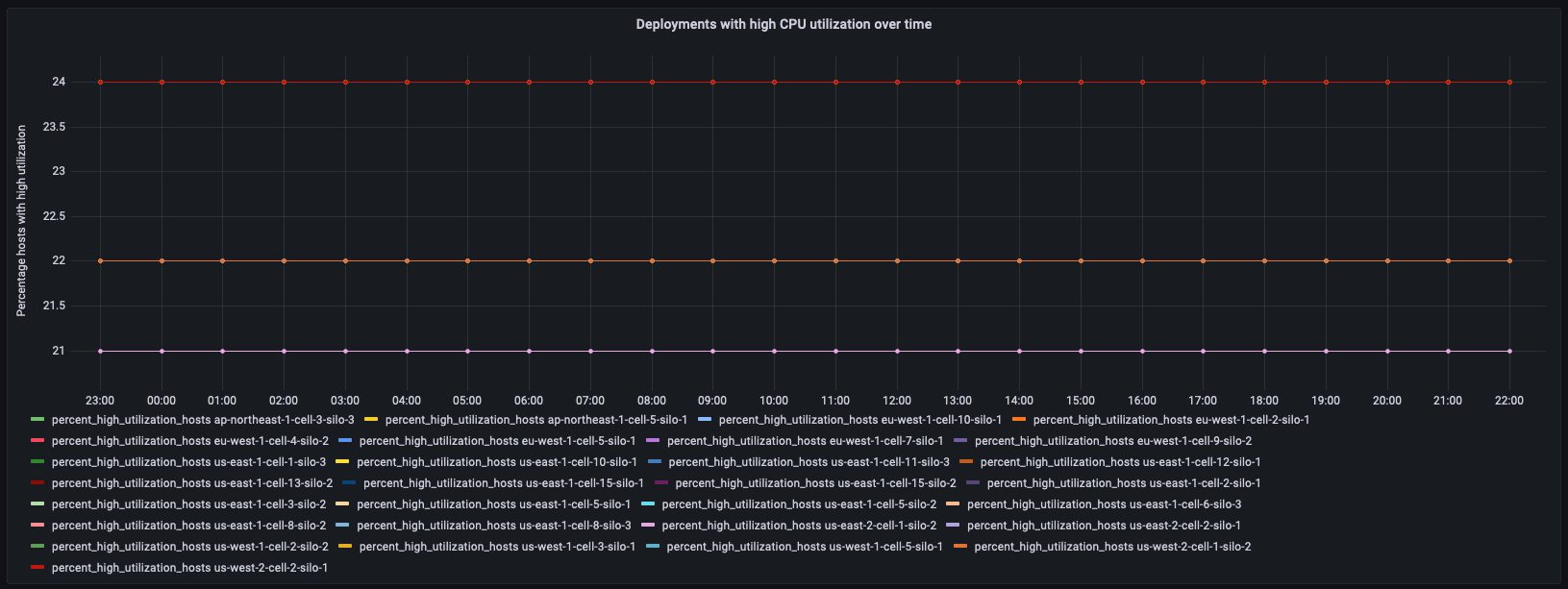
WITH high_utilization_percent AS ( SELECT region, cell, silo, microservice_name, bin(time, 1h) AS hour, MAX(num_hosts) AS num_hosts, MAX(high_utilization_hosts) AS high_utilization_hosts, ROUND(MAX(high_utilization_hosts) * 100.0 / MAX(num_hosts)) AS percent_high_utilization_hosts FROM "derived"."deployment_cpu_stats_per_hr" WHERE time BETWEEN from_milliseconds(1636525800000) AND from_milliseconds(1636612200000) AND measure_name = 'cpu_user' AND microservice_name = 'demeter' GROUP BY region, cell, silo, microservice_name, bin(time, 1h) ), high_utilization_ranked AS ( SELECT region, cell, silo, microservice_name, DENSE_RANK() OVER (PARTITION BY region ORDER BY AVG(percent_high_utilization_hosts) desc, AVG(high_utilization_hosts) desc) AS rank FROM high_utilization_percent GROUP BY region, cell, silo, microservice_name ) SELECT hup.silo, CREATE_TIME_SERIES(hour, hup.percent_high_utilization_hosts) AS percent_high_utilization_hosts FROM high_utilization_percent hup INNER JOIN high_utilization_ranked hur ON hup.region = hur.region AND hup.cell = hur.cell AND hup.silo = hur.silo AND hup.microservice_name = hur.microservice_name WHERE rank <= 2 GROUP BY hup.region, hup.cell, hup.silo ORDER BY hup.silo
