Para recursos semelhantes aos do Amazon Timestream para, considere o Amazon Timestream LiveAnalytics para InfluxDB. Ele oferece ingestão de dados simplificada e tempos de resposta de consulta de um dígito em milissegundos para análises em tempo real. Saiba mais aqui.
As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimizar o acesso a dados no Amazon Timestream
Você pode otimizar os padrões de acesso aos dados no Amazon Timestream usando o esquema de particionamento Timestream ou técnicas de organização de dados.
Esquema de particionamento do Timestream
O Amazon Timestream usa um esquema de particionamento altamente escalável em que cada tabela do Timestream pode ter centenas, milhares ou até milhões de partições independentes. Um serviço de indexação e rastreamento de partições altamente disponível gerencia o particionamento, minimizando o impacto das falhas e tornando o sistema mais resiliente.
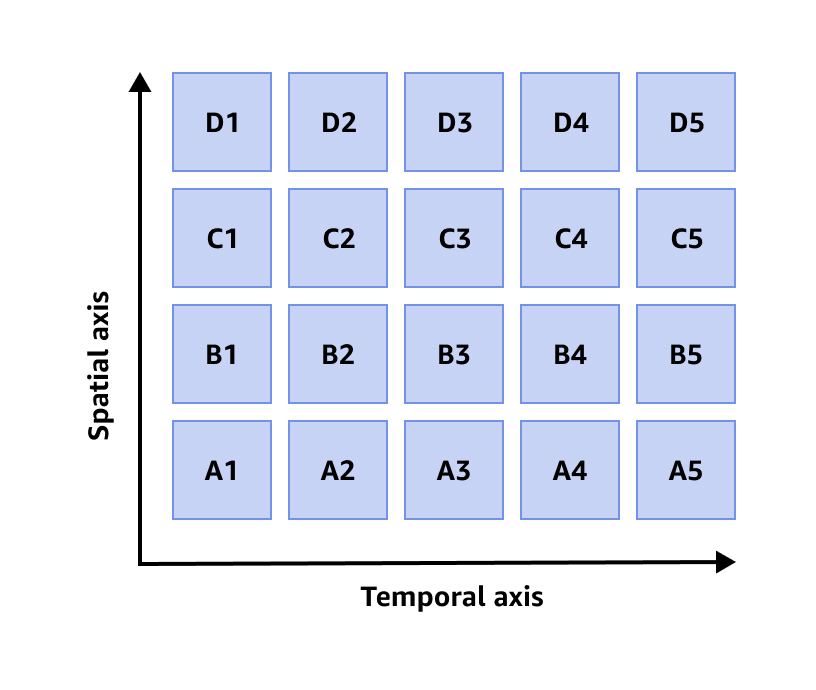
Organização de dados
O Timestream armazena cada ponto de dados que ingere em uma única partição. Conforme você ingere dados em uma tabela do Timestream, o Timestream cria automaticamente partições com base nos registros de data e hora, na chave de partição e em outros atributos de contexto nos dados. Além de particionar os dados no tempo (particionamento temporal), o Timestream também particiona os dados com base na chave de particionamento selecionada e em outras dimensões (particionamento espacial). Essa abordagem foi projetada para distribuir o tráfego de gravação e permitir a remoção eficaz dos dados para consultas.
O atributo de insights de consulta fornece informações valiosas sobre a eficiência de remoção da consulta, que inclui cobertura espacial da consulta e cobertura temporal da consulta.
QuerySpatialCoverage
A QuerySpatialCoveragemétrica fornece informações sobre a cobertura espacial da consulta executada e a tabela com a redução espacial mais ineficiente. Essas informações podem ajudar você a identificar áreas de melhoria na estratégia de particionamento para aprimorar a redução espacial. O valor da métrica QuerySpatialCoverage varia entre 0 e 1. Quanto menor o valor da métrica, melhor será a redução da consulta no eixo espacial. Por exemplo, um valor de 0,1 indica que a consulta analisou 10% do eixo espacial. Um valor de 1 indica que a consulta analisou 100% do eixo espacial.
exemplo Usando insights de consulta para analisar a cobertura espacial de uma consulta
Digamos que você tenha um banco de dados Timestream que armazena dados meteorológicos. Suponha que a temperatura seja registrada a cada hora em estações meteorológicas localizadas em diferentes estados dos Estados Unidos. Imagine que você escolha State como a chave de particionamento definida pelo cliente (CDPK) para particionar os dados por estado.
Suponha que você execute uma consulta para recuperar a temperatura média de todas as estações meteorológicas na Califórnia entre 14h e 16h em um dia específico. O exemplo a seguir mostra a consulta para esse cenário.
SELECT AVG(temperature) FROM "weather_data"."hourly_weather" WHERE time >= '2024-10-01 14:00:00' AND time < '2024-10-01 16:00:00' AND state = 'CA';
Usando o atributo de insights de consulta, você pode analisar a cobertura espacial da consulta. Imagine que a métrica QuerySpatialCoverage retorne um valor de 0,02. Isso significa que a consulta analisou apenas 2% do eixo espacial, o que é eficiente. Nesse caso, a consulta conseguiu reduzir efetivamente a faixa espacial, recuperando apenas dados da Califórnia e ignorando dados de outros estados.
Por outro lado, se a métrica QuerySpatialCoverage retornasse um valor de 0,8, isso indicaria que a consulta analisou 80% do eixo espacial, o que é menos eficiente. Isso pode sugerir que a estratégia de particionamento precisa ser refinada para melhorar a redução espacial. Por exemplo, você pode selecionar a chave de partição como cidade ou região em vez de estado. Ao analisar a métrica QuerySpatialCoverage, você pode identificar oportunidades para otimizar sua estratégia de particionamento e melhorar o desempenho de suas consultas.
A imagem a seguir mostra uma redução espacial deficiente.
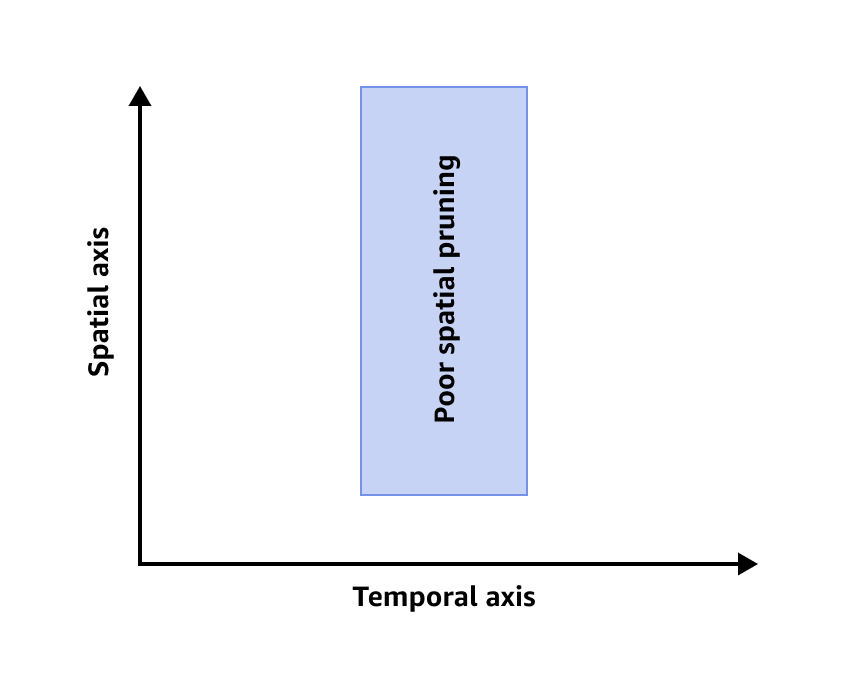
Para melhorar a eficiência da redução espacial, você pode fazer um dos seguintes procedimentos ou ambos:
-
Adicione
measure_name, que é a chave de particionamento padrão, ou use os predicados do CDPK em sua consulta. -
Se você já adicionou os atributos mencionados no ponto anterior, remova as funções em torno desses atributos ou cláusulas, como
LIKE.
QueryTemporalCoverage
A métrica QueryTemporalCoverage fornece informações sobre o intervalo temporal analisado pela consulta executada, incluindo a tabela com o maior intervalo de tempo verificado. O valor da métrica QueryTemporalCoverage é o intervalo de tempo representado em nanossegundos. Quanto menor o valor dessa métrica, melhor será a redução da consulta no intervalo temporal. Por exemplo, uma consulta que verifica os últimos minutos de dados tem melhor desempenho do que uma consulta que verifica todo o intervalo de tempo da tabela.
exemplo
Digamos que você tenha um banco de dados Timestream que armazena dados de sensores IoT, com medições feitas a cada minuto em dispositivos localizados em uma fábrica. Suponha que você tenha particionado seus dados por device_ID.
Suponha que você execute uma consulta para recuperar a leitura média do sensor de um dispositivo específico nos últimos 30 minutos. O exemplo a seguir mostra a consulta para esse cenário.
SELECT AVG(sensor_reading) FROM "sensor_data"."factory_1" WHERE device_id = 'DEV_123' AND time >= NOW() - INTERVAL 30 MINUTE and time < NOW();
Usando o recurso de insights de consulta, você pode analisar o intervalo temporal analisado pela consulta. Imagine que a métrica QueryTemporalCoverage retorne um valor de 1800000000000 nanossegundos (30 minutos). Isso significa que a consulta analisou apenas os últimos 30 minutos de dados, o que é um intervalo temporal relativamente estreito. Isso é um bom sinal porque indica que a consulta conseguiu eliminar efetivamente o particionamento temporal e recuperou somente os dados solicitados.
Por outro lado, se a métrica QueryTemporalCoverage retornou um valor de 1 ano em nanossegundos, isso indica que a consulta examinou um ano do intervalo de tempo na tabela, o que é menos eficiente. Isso pode sugerir que a consulta não está otimizada para remoção temporal, e você pode melhorá-la adicionando filtros de tempo.
A imagem a seguir mostra uma redução temporal deficiente.
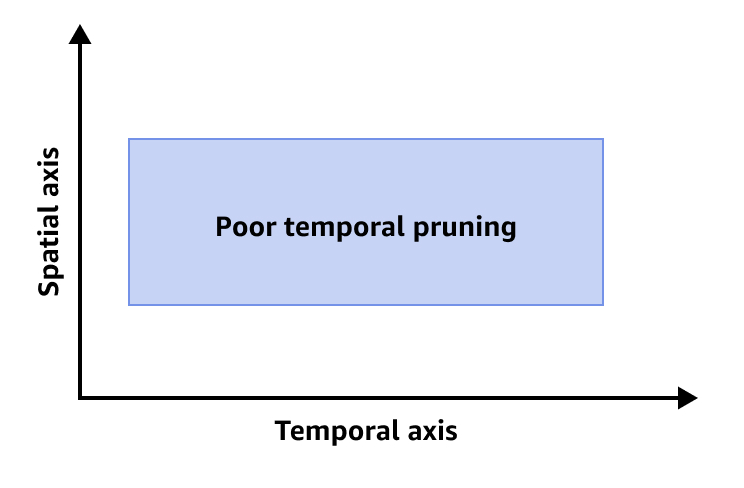
Para melhorar a redução temporal, é recomendável executar um ou todos os procedimentos a seguir:
-
Adicione os predicados de tempo ausentes na consulta e certifique-se de que os predicados de tempo estejam eliminando a janela de tempo desejada.
-
Remova funções, como
MAX(), de acordo com os predicados de tempo. -
Adicione predicados de tempo a todas as subconsultas. Isso é importante se suas subconsultas estiverem unindo tabelas grandes ou executando operações complexas.
