As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Transforme eventos do Amazon SNS em Event Fork AWS Pipelines
| Para arquivamento e análise de eventos, o Amazon SNS agora recomenda o uso de sua integração nativa com o Amazon Data Firehose. Você pode inscrever streams de entrega do Firehose em tópicos do SNS, o que permite enviar notificações para endpoints de arquivamento e análise, como buckets do Amazon Simple Storage Service (Amazon S3), tabelas do Amazon Redshift, Amazon Service (Service) e muito mais. OpenSearch OpenSearch Usar o Amazon SNS com os streams de entrega do Firehose é uma solução totalmente gerenciada e sem código que não exige o uso de funções. AWS Lambda Para obter mais informações, consulte Fanout de fluxos de entrega do Firehose. |
Você pode usar o Amazon SNS para desenvolver aplicações orientadas por eventos que usam serviços de assinante para executar o trabalho automaticamente em resposta a eventos acionados por serviços do editor. Esse padrão de arquitetura pode tornar os serviços mais reutilizáveis, interoperáveis e dimensionáveis. No entanto, pode ser trabalhoso usar o processamento de eventos em pipelines que abordam os requisitos de manipulação de eventos comuns, como armazenamento de eventos, backup, pesquisa, análise e reprodução.
Para acelerar o desenvolvimento de seus aplicativos orientados a eventos, você pode inscrever pipelines de tratamento de eventos — desenvolvidos pelo AWS Event Fork Pipelines — em tópicos do Amazon SNS. AWS O Event Fork Pipelines é um conjunto de aplicativos aninhados de código aberto, baseado no AWS Serverless Application Model
Para um AWS caso de uso do Event Fork Pipelines, consulte. Implantar e testar a aplicação de exemplo de event fork pipelines do Amazon SNS
Tópicos
Como funciona o AWS Event Fork Pipelines
AWS O Event Fork Pipelines é um padrão de design sem servidor. No entanto, também é um conjunto de aplicativos sem servidor aninhados baseados no AWS SAM (que você pode implantar diretamente do (AWS SAR) para o AWS Serverless Application Repository seu, a fim de enriquecer suas Conta da AWS plataformas orientadas a eventos). Você pode implantar essas aplicações aninhadas individualmente, conforme sua arquitetura exigir.
Tópicos
O diagrama a seguir mostra um aplicativo AWS Event Fork Pipelines complementado por três aplicativos aninhados. Você pode implantar qualquer um dos pipelines do pacote AWS Event Fork Pipelines no AWS SAR de forma independente, conforme sua arquitetura exige.
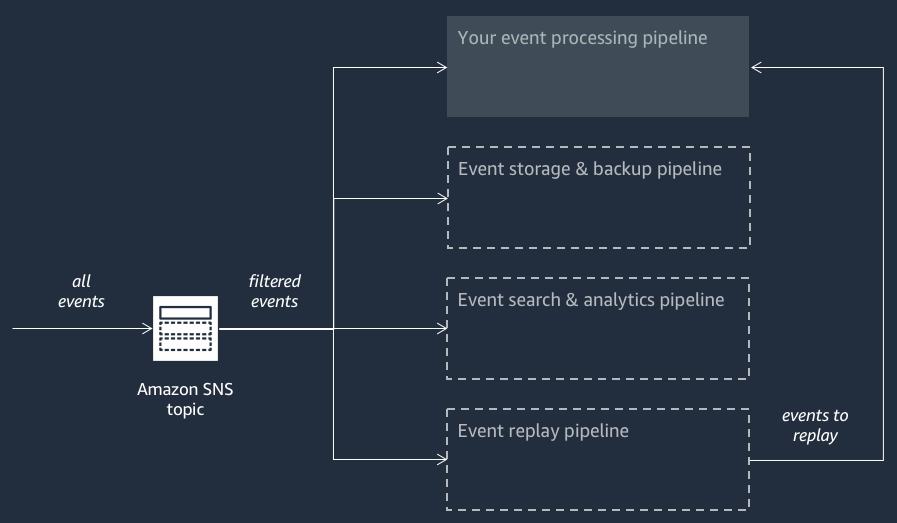
Cada pipeline é inscrito no mesmo tópico do Amazon SNS, o que permite que ele processe eventos em paralelo conforme esses eventos são publicados no tópico. Cada pipeline é independente e pode definir sua própria política de filtro de assinatura. Isso permite que um pipeline processe apenas um subconjunto dos eventos em que está interessado (em vez de todos os eventos publicados no tópico).
nota
Como você coloca os três AWS Event Fork Pipelines ao lado de seus pipelines regulares de processamento de eventos (possivelmente já inscritos no tópico do Amazon SNS), você não precisa alterar nenhuma parte do seu editor de mensagens atual para aproveitar os AWS Event Fork Pipelines em suas cargas de trabalho existentes.
O pipeline de armazenamento e backup de eventos
O diagrama a seguir mostra o pipeline de armazenamento e backup de eventos
Esse pipeline é composto por uma fila do Amazon SQS que armazena em buffer os eventos entregues pelo tópico do Amazon SNS, AWS Lambda uma função que pesquisa automaticamente esses eventos na fila e os envia para um stream e um bucket do Amazon S3 que faz backup duradouro dos eventos carregados pelo stream.
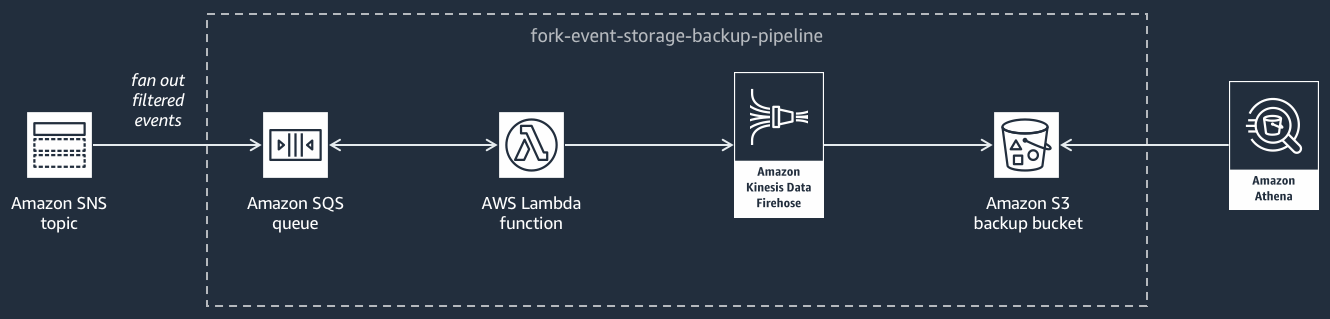
Para ajustar o comportamento de seu fluxo do Firehose, configure-o para armazenar em buffer, transformar e compactar seus eventos antes de carregá-los no bucket. À medida que os eventos forem carregados, use o Amazon Athena para consultar o bucket usando consultas SQL padrão. Você também pode configurar o pipeline para reutilizar um bucket do Simple Storage Service (Amazon S3) existente ou criar um novo.
O pipeline de pesquisa e análise de eventos
O diagrama a seguir mostra o pipeline de pesquisa e análise de eventos
Esse pipeline é composto por uma fila do Amazon SQS que armazena em buffer os eventos entregues pelo tópico do Amazon SNS, AWS Lambda uma função que pesquisa eventos da fila e os envia para um stream, um domínio do Amazon Service que indexa os eventos carregados pelo stream do Firehose e um bucket do OpenSearch Amazon S3 que armazena os eventos sem saída que não podem ser indexados no domínio de pesquisa.
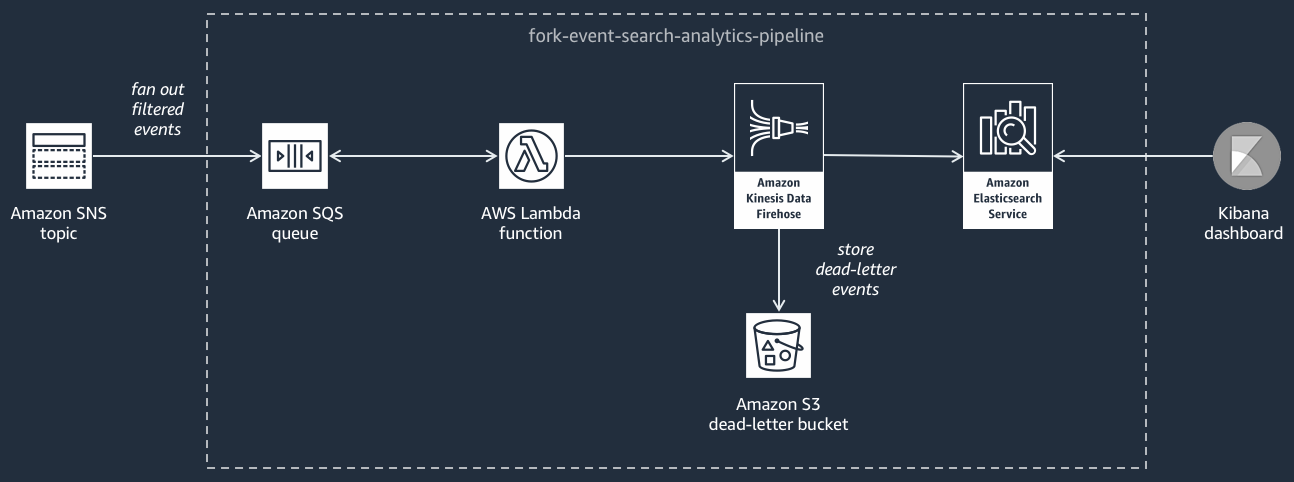
Para ajustar o fluxo do Firehose em termos de armazenamento de eventos em buffer, transformação e compactação, você pode configurar esse pipeline.
Você também pode configurar se o pipeline deve reutilizar um OpenSearch domínio existente no seu Conta da AWS ou criar um novo para você. À medida que os eventos forem indexados no domínio de pesquisa, use o Kibana para executar a análise de seus eventos e atualizar os painéis visuais em tempo real.
O pipeline de reprodução de eventos
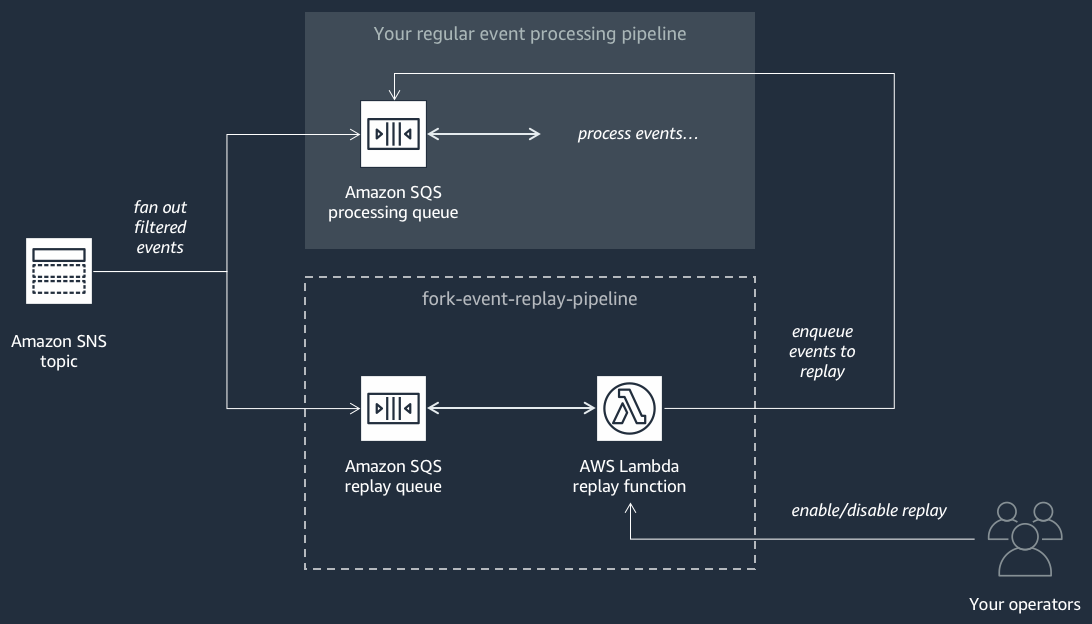
O diagrama a seguir mostra o pipeline de reprodução de eventos
Esse pipeline é composto por uma fila do Amazon SQS que armazena em buffer os eventos entregues pelo tópico do Amazon SNS e AWS Lambda uma função que pesquisa eventos da fila e os redireciona para seu pipeline regular de processamento de eventos, que também está inscrito em seu tópico.
nota
Por padrão, a função de reprodução está desabilitada e não redireciona seus eventos. Se precisar reprocessar os eventos, você deve habilitar a fila de reprodução do Amazon SQS como uma origem de eventos para a função de reprodução do AWS Lambda .
Implantação de tubulações AWS Event Fork
O pacote AWS Event Fork Pipelines
Em um cenário de produção, recomendamos incorporar o AWS Event Fork Pipelines ao modelo geral de SAM do AWS seu aplicativo. O recurso de aplicativo aninhado permite que você faça isso adicionando o recurso AWS::Serverless::Application ao seu modelo AWS SAM, referenciando o AWS SAR ApplicationId e o SemanticVersion do aplicativo aninhado.
Por exemplo, você pode usar o Event Storage and Backup Pipeline como um aplicativo aninhado adicionando o seguinte trecho de YAML à Resources seção do seu modelo do SAM. AWS
Backup:
Type: AWS::Serverless::Application
Properties:
Location:
ApplicationId: arn:aws:serverlessrepo:us-east-2:123456789012:applications/fork-event-storage-backup-pipeline
SemanticVersion: 1.0.0
Parameters:
#The ARN of the Amazon SNS topic whose messages should be backed up to the Amazon S3 bucket.
TopicArn: !Ref MySNSTopicAo especificar valores de parâmetros, você pode usar funções AWS CloudFormation intrínsecas para referenciar outros recursos em seu modelo. Por exemplo, no trecho YAML acima, o TopicArn parâmetro faz referência ao AWS::SNS::Topic recursoMySNSTopic, definido em outra parte do modelo. AWS SAM Para obter mais informações, consulte o Referência à função intrínseca no Guia do usuário do usuário do AWS CloudFormation .
nota
A página do AWS Lambda console do seu aplicativo AWS SAR inclui o botão Copiar como recurso do SAM, que copia o YAML necessário para aninhar um aplicativo AWS SAR na área de transferência.
