As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Usando treinamento elástico na Amazon SageMaker HyperPod
O treinamento elástico é um novo SageMaker HyperPod recurso da Amazon que escala automaticamente as tarefas de treinamento com base na disponibilidade dos recursos computacionais e na prioridade da carga de trabalho. Os trabalhos de treinamento da Elastic podem começar com os recursos computacionais mínimos necessários para o treinamento do modelo e aumentar ou diminuir dinamicamente por meio de pontos de verificação e retomada automáticos em diferentes configurações de nós (tamanho mundial). O escalonamento é obtido ajustando automaticamente o número de réplicas paralelas de dados. Durante os períodos de alta utilização do cluster, os trabalhos elásticos de treinamento podem ser configurados para serem reduzidos automaticamente em resposta às solicitações de recursos de trabalhos de maior prioridade, liberando a computação para cargas de trabalho críticas. Quando os recursos são liberados fora dos períodos de pico, os trabalhos de treinamento elásticos aumentam automaticamente para acelerar o treinamento e, em seguida, diminuem quando cargas de trabalho de maior prioridade precisam de recursos novamente.
O treinamento elástico é construído com base no operador de HyperPod treinamento e integra os seguintes componentes:
-
Amazon SageMaker HyperPod Task Governance para enfileiramento, priorização e agendamento de trabalhos
-
PyTorch Ponto de verificação distribuído (DCP)
para gerenciamento escalável de estados e pontos de verificação, como o DCP
Estruturas suportadas
-
PyTorch com dados paralelos distribuídos (DDP) e dados paralelos totalmente fragmentados (FSDP)
-
PyTorch Ponto de verificação distribuído (DCP)
Pré-requisitos
SageMaker HyperPod Cluster EKS
Você deve ter um SageMaker HyperPod cluster em execução com a orquestração do Amazon EKS. Para obter informações sobre como criar um cluster HyperPod EKS, consulte:
SageMaker HyperPod Operador de treinamento
O Elastic Training é suportado no Training Operator v. 1.2 e superior.
Para instalar o operador de treinamento como complemento do EKS, consulte: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Recomendado) Instalar e configurar o Task Governance e o Kueue
Recomendamos instalar e configurar o Kueue por meio da Governança de HyperPod Tarefas para especificar as prioridades da carga de trabalho com treinamento elástico. O Kueue fornece um gerenciamento mais forte da carga de trabalho com filas, priorização, agendamento de grupos, rastreamento de recursos e preempção elegante, essenciais para operar em ambientes de treinamento com vários inquilinos.
-
O agendamento de grupos garante que todos os grupos necessários para um trabalho de treinamento comecem juntos. Isso evita situações em que alguns pods iniciam enquanto outros permanecem pendentes, o que pode causar desperdício de recursos.
-
A preempção suave permite que trabalhos elásticos de menor prioridade forneçam recursos para cargas de trabalho de maior prioridade. As tarefas elásticas podem ser reduzidas normalmente sem serem removidas à força, melhorando a estabilidade geral do cluster.
Recomendamos configurar os seguintes componentes do Kueue:
-
PriorityClasses para definir a importância relativa do trabalho
-
ClusterQueues para gerenciar o compartilhamento global de recursos e as cotas entre equipes ou cargas de trabalho
-
LocalQueues para rotear trabalhos de namespaces individuais para o apropriado ClusterQueue
Para configurações mais avançadas, você também pode incorporar:
-
Fair-share políticas para equilibrar o uso de recursos em várias equipes
-
Regras de preempção personalizadas para aplicar SLAs organizacionais ou controles de custos
Por favor, consulte:
(Recomendado) Configurar namespaces de usuário e cotas de recursos
Ao implantar esse recurso no Amazon EKS, recomendamos aplicar um conjunto de configurações básicas em nível de cluster para garantir isolamento, equidade de recursos e consistência operacional entre as equipes.
Configuração de namespace e acesso
Organize suas cargas de trabalho usando namespaces separados para cada equipe ou projeto. Isso permite que você aplique isolamento e governança refinados. Também recomendamos configurar o mapeamento RBAC AWS do IAM para o Kubernetes para associar usuários ou funções individuais do IAM aos namespaces correspondentes.
As principais práticas incluem:
-
Mapeie funções do IAM para contas de serviço do Kubernetes usando funções do IAM para contas de serviço (IRSA) quando as cargas de trabalho precisarem de permissões. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Aplique políticas de RBAC para restringir os usuários somente aos namespaces designados (por exemplo,
Role/RoleBindingem vez de permissões em todo o cluster).
Restrições de recursos e computação
Para evitar a contenção de recursos e garantir um agendamento justo entre as equipes, aplique cotas e limites no nível do namespace:
-
ResourceQuotas para limitar a contagem agregada de CPU, memória, armazenamento e objetos (pods, PVCs, serviços etc.).
-
LimitRanges para impor limites padrão e máximos de CPU e memória por pod ou por contêiner.
-
PodDisruptionBudgets (PDBs) conforme necessário para definir as expectativas de resiliência.
-
Opcional: restrições de Namespace-level filas (por exemplo, via Task Governance ou Kueue) para evitar que os usuários enviem trabalhos em excesso.
Essas restrições ajudam a manter a estabilidade do cluster e oferecem suporte ao agendamento previsível para cargas de trabalho de treinamento distribuídas.
Auto-scaling
SageMaker HyperPod no EKS oferece suporte ao escalonamento automático de clusters por meio do Karpenter. Quando o Karpenter ou um provisionador de recursos similar é usado junto com o treinamento elástico, o cluster e o trabalho de treinamento elástico podem ser ampliados automaticamente após o envio de um trabalho de treinamento elástico. Isso ocorre porque o operador de treinamento elástico adota uma abordagem gananciosa, sempre solicita mais do que os recursos computacionais disponíveis até atingir o limite máximo definido pelo trabalho. Isso ocorre porque o operador de treinamento elástico solicita continuamente recursos adicionais como parte da execução elástica do trabalho, o que pode acionar o provisionamento de nós. Provisionadores contínuos de recursos, como o Karpenter, atenderão às solicitações ampliando o cluster de computação.
Para manter esses aumentos de escala previsíveis e sob controle, recomendamos configurar o nível do namespace nos namespaces ResourceQuotas em que os trabalhos de treinamento elásticos são criados. ResourceQuotas ajudam a limitar o máximo de recursos que os trabalhos podem solicitar, evitando o crescimento ilimitado do cluster e, ao mesmo tempo, permitindo um comportamento elástico dentro de limites definidos.
Por exemplo, a ResourceQuota para 8 instâncias ml.p5.48xlarge terá o seguinte formato:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Crie um contêiner de treinamento
HyperPod o operador de treinamento trabalha com um PyTorch lançador personalizado fornecido por meio do pacote python do HyperPod Elastic Agent () https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun comando por hyperpodrun para iniciar o treinamento. Para obter mais detalhes, consulte:
Um exemplo de contêiner de treinamento:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Modificação do código de treinamento
SageMaker HyperPod fornece um conjunto de receitas que já estão configuradas para serem executadas com o Elastic Policy.
Para habilitar o treinamento elástico para scripts de PyTorch treinamento personalizados, você precisará fazer pequenas modificações em seu ciclo de treinamento. Este guia mostra as modificações necessárias para garantir que seu trabalho de treinamento responda aos eventos de escalabilidade elástica que ocorrem quando a disponibilidade dos recursos computacionais muda. Durante todos os eventos elásticos (por exemplo, os nós estão disponíveis ou os nós são preemptados), o trabalho de treinamento recebe um sinal de evento elástico que é usado para coordenar um desligamento normal salvando um ponto de verificação e retomando o treinamento reiniciando desse ponto de verificação salvo com uma nova configuração mundial. Para habilitar o treinamento elástico com scripts de treinamento personalizados, você precisa:
Detecte eventos de escalabilidade elástica
Em seu ciclo de treinamento, verifique se há eventos elásticos durante cada iteração:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Implemente o salvamento do ponto de verificação e o carregamento do ponto de verificação
Nota: Recomendamos usar o PyTorch Distributed Checkpoint (DCP) para salvar os estados do modelo e do otimizador, pois o DCP suporta a retomada a partir de um ponto de verificação com tamanhos de mundo diferentes. Outros formatos de ponto de verificação podem não suportar o carregamento de pontos de verificação em tamanhos de mundo diferentes. Nesse caso, você precisará implementar uma lógica personalizada para lidar com mudanças dinâmicas no tamanho do mundo.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Opcional) Use carregadores de dados com estado
Se você estiver treinando apenas para uma única época (ou seja, uma única passagem por todo o conjunto de dados), o modelo deverá ver cada amostra de dados exatamente uma vez. Se o trabalho de treinamento parar no meio da época e continuar com um tamanho de mundo diferente, as amostras de dados processadas anteriormente serão repetidas se o estado do carregador de dados não persistir. Um carregador de dados com estado evita isso salvando e restaurando a posição do carregador de dados, garantindo que as execuções retomadas continuem a partir do evento de escalonamento elástico sem reprocessar nenhuma amostra. Recomendamos o uso StatefulDataLoaderstate_dict() e load_state_dict() métodos, permitindo a verificação intermediária do processo de carregamento de dados. torch.utils.data.DataLoader
Envio de trabalhos de treinamento elástico
HyperPod operador de treinamento define um novo tipo de recurso -hyperpodpytorchjob. O treinamento elástico estende esse tipo de recurso e adiciona os campos destacados abaixo:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Uso do kubectl
Posteriormente, você pode iniciar o treinamento elástico com o comando a seguir.
kubectl apply -f elastic-training-job.yaml
Usando SageMaker receitas
Os trabalhos de treinamento da Elastic podem ser iniciados por meio de SageMaker HyperPod receitas
nota
Incluímos 46 receitas elásticas para trabalhos de SFO e DPO no Hyperpod Recipe. Os usuários podem iniciar esses trabalhos com uma alteração de linha em cima do script de inicialização estático existente:
++recipes.elastic_policy.is_elastic=true
Além das receitas estáticas, as receitas elásticas adicionam os seguintes campos para definir os comportamentos elásticos:
Política elástica
O elastic_policy campo define a configuração do nível de trabalho para o trabalho de treinamento elástico, ele tem as seguintes configurações:
-
is_elastic:bool- se esse trabalho for elástico -
min_nodes:int- o número mínimo de nós usados para treinamento elástico -
max_nodes:int- o número máximo de nós usados para treinamento elástico -
replica_increment_step:int- incremente a quantidade de pods em grupos de tamanho fixo. Esse campo é mutuamente exclusivo do que definiremos posteriormente.scale_config -
use_graceful_shutdown:bool- se usar o desligamento normal durante eventos de escalonamento, use como padrão.true -
scaling_timeout:int- o tempo de espera em segundos durante o evento de escalonamento antes do tempo limite -
graceful_shutdown_timeout:int- o tempo de espera para um desligamento normal
A seguir está um exemplo de definição desse campo, que você também pode encontrar no repositório Hyperpod Recipe na receita: recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Configuração de escala
O scale_config campo define as configurações principais em cada escala específica. É um dicionário de valores-chave, em que a chave é um número inteiro que representa a escala alvo e o valor é um subconjunto da receita básica. Em <key> grande escala, usamos o <value> para atualizar as configurações específicas na base/static receita. Veja a seguir um exemplo desse campo:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
A configuração acima define a configuração de treinamento nas escalas 2 e 3. Em ambos os casos, usamos a taxa de aprendizado4e-4, o tamanho do lote de128. Mas na escala 2, usamos a micro_train_batch_size de 8, enquanto na escala 3, usamos um tamanho de lote desigual, pois o tamanho do lote do trem não pode ser dividido uniformemente em 3 nós.
Tamanho de lote desigual
Esse é um campo para definir o comportamento de distribuição do lote quando o tamanho global do lote não pode ser dividido uniformemente pelo número de classificações. Não é específico para treinamento elástico, mas é um facilitador para uma maior granularidade de escalabilidade.
-
use_uneven_batch:bool- se usar distribuição desigual de lotes -
num_dp_groups_with_small_batch_size:int- na distribuição desigual de lotes, algumas classificações usam um tamanho de lote local menor, enquanto outras usam um tamanho de lote maior. O tamanho global do lote deve ser igual asmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- esse valor é o menor tamanho do lote local -
large_local_batch_size:int- esse valor é o maior tamanho do lote local
Monitore o treinamento no MLflow
Os trabalhos de receita do Hyperpod oferecem suporte à observabilidade por meio do MLflow. Os usuários podem especificar as configurações do MLflow na receita:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Essas configurações são mapeadas para a configuração correspondente do MLflow
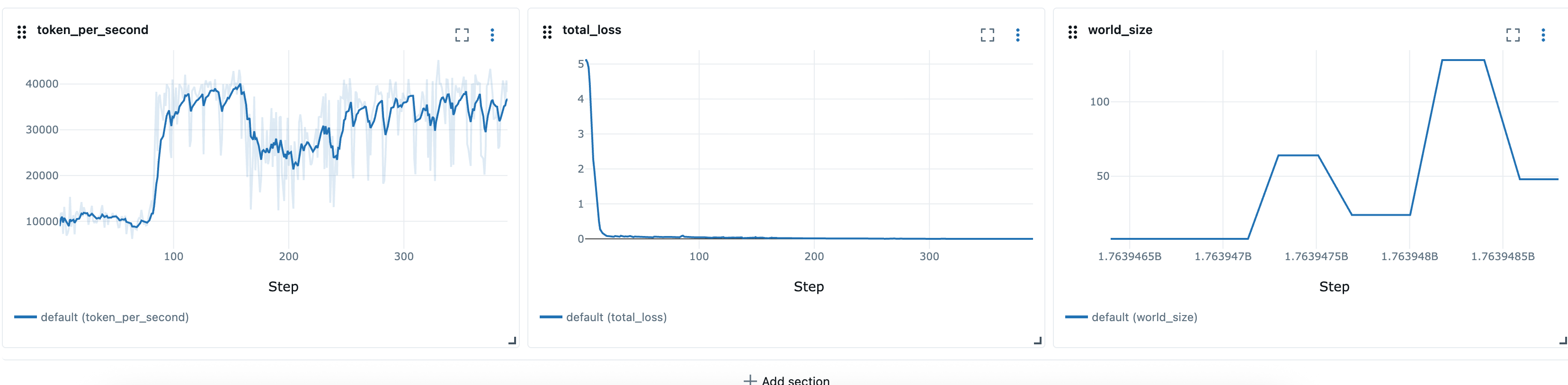
Depois de definir as receitas elásticas, podemos usar os scripts do lançador, como launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh para iniciar um trabalho de treinamento elástico. Isso é semelhante ao lançamento de um trabalho estático usando a receita do Hyperpod.
nota
O trabalho de treinamento elástico do suporte de receitas é retomado automaticamente a partir dos pontos de verificação mais recentes. No entanto, por padrão, cada reinicialização cria um novo diretório de treinamento. Para permitir a retomada correta do último ponto de verificação, precisamos garantir que o mesmo diretório de treinamento seja reutilizado. Isso pode ser feito definindo
recipes.training_config.training_args.override_training_dir=true
Use-case exemplos e limitações
Scale-up quando mais recursos estão disponíveis
Quando mais recursos se tornam disponíveis no cluster (por exemplo, outras cargas de trabalho são concluídas). Durante esse evento, o controlador de treinamento ampliará automaticamente o trabalho de treinamento. Esse comportamento é explicado abaixo.
Para simular uma situação em que mais recursos se tornam disponíveis, podemos enviar um trabalho de alta prioridade e, em seguida, liberar recursos de volta excluindo o trabalho de alta prioridade.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
Comportamento esperado:
-
O operador de treinamento cria uma carga de trabalho Kueue Quando um trabalho de treinamento elástico solicita uma mudança no tamanho do mundo, o operador de treinamento gera um objeto Kueue Workload adicional representando os novos requisitos de recursos.
-
Kueue admite a carga de trabalho Kueue avalia a solicitação com base nos recursos, prioridades e políticas de filas disponíveis. Uma vez aprovada, a carga horária é admitida.
-
O operador de treinamento cria os pods adicionais. Após a admissão, o operador lança os pods adicionais necessários para atingir o novo tamanho mundial.
-
Quando as novas cápsulas ficam prontas, o operador de treinamento envia um sinal especial de evento elástico para o script de treinamento.
-
O trabalho de treinamento executa um checkpoint, para se preparar para um desligamento normal. O processo de treinamento verifica periodicamente o sinal de evento elástico chamando a função elastic_event_detected (). Uma vez detectado, ele inicia um ponto de verificação. Depois que o ponto de verificação for concluído com sucesso, o processo de treinamento será encerrado de forma limpa.
-
O operador de treinamento reinicia o trabalho com o novo tamanho do mundo O operador espera que todos os processos saiam e reinicia o trabalho de treinamento usando o tamanho do mundo atualizado e o ponto de verificação mais recente.
Nota: Quando o Kueue não é usado, o operador de treinamento pula as duas primeiras etapas. Ele imediatamente tenta criar os pods adicionais necessários para o novo tamanho do mundo. Se recursos suficientes não estiverem disponíveis no cluster, esses pods permanecerão em um estado pendente até que a capacidade esteja disponível.

Preempção por trabalho de alta prioridade
Os trabalhos elásticos podem ser reduzidos automaticamente quando um trabalho de alta prioridade precisa de recursos. Para simular esse comportamento, você pode enviar um trabalho de treinamento elástico, que usa o número máximo de recursos disponíveis desde o início do treinamento, depois enviar um trabalho de alta prioridade e observar o comportamento de preempção.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
Quando um trabalho de alta prioridade precisa de recursos, a Kueue pode se antecipar às cargas de trabalho do Elastic Training de baixa prioridade (pode haver mais de um objeto de carga de trabalho associado ao trabalho do Elastic Training). O processo de preempção segue esta sequência:
-
Um trabalho de alta prioridade é enviado. O trabalho cria uma nova carga de trabalho Kueue, mas a carga de trabalho não pode ser admitida devido à insuficiência de recursos do cluster.
-
Kueue se antecipa a uma das cargas de trabalho do Elastic Training. Os trabalhos elásticos podem ter várias cargas de trabalho ativas (uma por configuração de tamanho mundial). O Kueue seleciona um para antecipar com base nas políticas de prioridade e fila.
-
O operador de treinamento envia um sinal de evento elástico. Depois que a preempção é acionada, o operador de treinamento notifica o processo de treinamento em execução para que ele pare normalmente.
-
O processo de treinamento realiza o checkpoint. O trabalho de treinamento verifica periodicamente os sinais elásticos de eventos. Quando detectado, ele inicia um ponto de verificação coordenado para preservar o progresso antes de ser desligado.
-
o operador de treinamento limpa cápsulas e cargas de trabalho. O operador aguarda a conclusão do ponto de verificação e, em seguida, exclui os módulos de treinamento que faziam parte da carga de trabalho antecipada. Ele também remove o objeto de carga de trabalho correspondente do Kueue.
-
A carga de trabalho de alta prioridade é admitida. Com os recursos liberados, Kueue admite o trabalho de alta prioridade, permitindo que ele inicie a execução.

A preempção pode fazer com que todo o trabalho de treinamento seja pausado, o que pode não ser desejável para todos os fluxos de trabalho. Para evitar a suspensão total do trabalho e, ao mesmo tempo, permitir o escalonamento elástico, os clientes podem configurar dois níveis de prioridade diferentes no mesmo trabalho de treinamento definindo duas seções: replicaSpec
-
Uma réplica primária (fixa) com prioridade normal ou alta
-
Contém o número mínimo necessário de réplicas necessárias para manter o trabalho de treinamento em execução.
-
Usa um valor superior PriorityClass, garantindo que essas réplicas nunca sejam substituídas.
-
Mantém o progresso da linha de base mesmo quando o cluster está sob pressão de recursos.
-
-
Um ReplicaSpec elástico (escalável) com menor prioridade
-
Contém as réplicas opcionais adicionais que fornecem computação extra durante o escalonamento elástico.
-
Usa um menor PriorityClass, permitindo que a Kueue antecipe essas réplicas quando trabalhos de maior prioridade precisarem de recursos.
-
Garante que somente a parte elástica seja recuperada, enquanto o treinamento básico continua ininterrupto.
-
Essa configuração permite a preempção parcial, em que somente a capacidade elástica é recuperada, mantendo a continuidade do treinamento e, ao mesmo tempo, apoiando o compartilhamento justo de recursos em ambientes multilocatários. Exemplo:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
Lidando com o despejo do pod, falhas do pod e degradação do hardware:
O operador HyperPod de treinamento inclui mecanismos integrados para recuperar o processo de treinamento quando ele é interrompido inesperadamente. As interrupções podem ocorrer por vários motivos, como falhas no código de treinamento, despejos de pods, falhas nos nós, degradação do hardware e outros problemas de tempo de execução.
Quando isso acontece, o operador tenta automaticamente recriar os pods afetados e retomar o treinamento a partir do ponto de verificação mais recente. Se a recuperação não for possível imediatamente, por exemplo, devido à capacidade ociosa insuficiente, o operador pode continuar progredindo reduzindo temporariamente o tamanho do mundo e reduzindo o trabalho de treinamento elástico.
Quando um trabalho de treinamento elástico falha ou perde réplicas, o sistema se comporta da seguinte maneira:
-
Fase de recuperação (usando nós sobressalentes) O Training Controller
faultyScaleDownTimeoutInSecondsespera até que os recursos estejam disponíveis e tenta recuperar as réplicas com falha reimplantando os pods na capacidade disponível. -
Diminuição elástica Se a recuperação não for possível dentro da janela de tempo limite, o operador de treinamento reduz o trabalho para um tamanho mundial menor (se a política elástica do trabalho permitir). Em seguida, o treinamento é retomado com menos réplicas.
-
Aumento de escala elástico Quando recursos adicionais são disponibilizados novamente, o operador escala automaticamente o trabalho de treinamento de volta ao tamanho mundial preferido.
Esse mecanismo garante que o treinamento possa continuar com o mínimo de tempo de inatividade, mesmo sob pressão de recursos ou falhas parciais na infraestrutura, enquanto ainda aproveita o escalonamento elástico.
Use treinamento elástico com outros HyperPod recursos
Atualmente, o treinamento elástico não oferece suporte a recursos de treinamento sem ponto de verificação, pontos de verificação HyperPod gerenciados em camadas ou instâncias spot.
nota
Coletamos determinadas métricas operacionais rotineiras agregadas e anônimas para fornecer disponibilidade de serviços essenciais. A criação dessas métricas é totalmente automatizada e não envolve a revisão humana da carga de trabalho de treinamento do modelo subjacente. Essas métricas estão relacionadas a um trabalho e às operações de escalabilidade, ao gerenciamento de recursos e à funcionalidade essencial do serviço.
