As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Introdução ao paralelismo de modelos
O paralelismo de modelos é um método de treinamento distribuído no qual o modelo de aprendizado profundo é particionado em vários dispositivos, dentro de ou entre instâncias. Esta página de introdução fornece uma visão geral de alto nível sobre o paralelismo de modelos, uma descrição de como ele pode ajudar a superar os problemas que surgem ao treinar modelos de DL que normalmente são muito grandes e exemplos do que a biblioteca paralela de modelos oferece para ajudar a gerenciar estratégias SageMaker paralelas de modelos, bem como o consumo de memória.
O que é paralelismo de modelos?
Aumentar o tamanho dos modelos de aprendizado profundo (camadas e parâmetros) gera maior precisão para tarefas complexas, como visão computacional e processamento de linguagem natural. No entanto, há um limite para o tamanho máximo do modelo que você pode colocar na memória de uma única GPU. Ao treinar modelos de DL, as limitações de memória da GPU podem ser gargalos das seguintes maneiras:
-
Limitam o tamanho do modelo que você pode treinar, já que a área ocupada pela memória de um modelo é escalada proporcionalmente ao número de parâmetros.
-
Limitam o tamanho do lote por GPU durante o treinamento, reduzindo a utilização da GPU e a eficiência do treinamento.
Para superar as limitações associadas ao treinamento de um modelo em uma única GPU, SageMaker fornece a biblioteca paralela de modelos para ajudar a distribuir e treinar modelos de DL de forma eficiente em vários nós de computação. Além disso, com a biblioteca, você pode obter o treinamento distribuído mais otimizado usando EFA-supported dispositivos que aprimoram o desempenho da comunicação entre nós com baixa latência, alto rendimento e desvio do sistema operacional.
Estime os requisitos de memória antes de usar o paralelismo do modelo
Antes de usar a biblioteca paralela de SageMaker modelos, considere o seguinte para ter uma ideia dos requisitos de memória para treinar grandes modelos de DL.
Para um trabalho de treinamento que usa os otimizadores AMP (FP16) e Adam, a memória necessária de GPU por parâmetro é de cerca de 20 bytes, que podemos dividir da seguinte forma:
-
Um parâmetro FP16 ~ 2 bytes
-
Um gradiente FP16 ~ 2 bytes
-
Um estado de otimizador FP32 de ~ 8 bytes com base nos otimizadores Adam
-
Uma cópia FP32 do parâmetro ~ 4 bytes [necessária para a operação
optimizer apply(OA)] -
Uma cópia FP32 do gradiente ~ 4 bytes [necessária para a operação (OA)]
Mesmo para um modelo DL relativamente pequeno com 10 bilhões de parâmetros, ele pode exigir pelo menos 200 GB de memória, o que é muito maior do que a memória típica da GPU (por exemplo, NVIDIA A100 com 40GB/80GB memória e V100 com 16/32 GB) disponível em uma única GPU. Observe que, além dos requisitos de memória para os estados do modelo e do otimizador, há outros consumidores de memória, como ativações geradas na passagem direta. A memória necessária pode ser muito superior a 200 GB.
Para treinamento distribuído, recomendamos que você use instâncias P3 e P4 do Amazon EC2 que tenham GPUs NVIDIA V100 e A100 Tensor Core, respectivamente. Para obter mais detalhes sobre especificações como núcleos de CPU, RAM, volume de armazenamento anexado e largura de banda de rede, consulte a seção Computação acelerada na página Tipos de instância do Amazon EC2
Mesmo com as instâncias de computação acelerada, é óbvio que modelos com cerca de 10 bilhões de parâmetros, como T5, Megatron-LM e modelos ainda maiores, com centenas de bilhões de parâmetros, como, GPT-3 não cabem em réplicas de modelos em cada dispositivo de GPU.
Como a biblioteca emprega técnicas de paralelismo de modelos e economia de memória
A biblioteca consiste em vários tipos de atributos de paralelismo de modelos e atributos de economia de memória, como fragmentação de estado do otimizador, ponto de verificação de ativação e descarregamento de ativação. Todas essas técnicas podem ser combinadas para treinar com eficiência modelos grandes que consistem em centenas de bilhões de parâmetros.
Tópicos
Paralelismo de dados fragmentados (disponível para) PyTorch
O paralelismo de dados fragmentados é uma técnica de treinamento distribuído que economiza memória e divide o estado de um modelo (parâmetros do modelo, gradientes e estados do otimizador) em GPUs dentro de um grupo paralelo de dados.
Você pode aplicar paralelismo de dados fragmentados ao seu modelo como uma estratégia independente. Além disso, se estiver usando as instâncias de GPU de melhor desempenho equipadas com GPUs NVIDIA A100 Tensor Core ml.p4d.24xlarge, você pode aproveitar a velocidade de treinamento aprimorada da AllGather operação oferecida por SMDDP Collectives.
Para se aprofundar no paralelismo de dados fragmentados e aprender como configurá-lo ou usar uma combinação de paralelismo de dados fragmentados com outras técnicas, como paralelismo de tensores e treinamento de FP16, consulte Paralelismo de dados compartilhados.
Paralelismo de tubulação (disponível para e) PyTorch TensorFlow
O paralelismo do pipeline particiona o conjunto de camadas ou operações no conjunto de dispositivos, deixando cada operação intacta. Quando você especifica um valor para o número de partições do modelo (pipeline_parallel_degree), o número total de GPUs (processes_per_host) deve ser divisível pelo número das partições do modelo. Para configurar isso corretamente, é preciso especificar os valores corretos para os parâmetros pipeline_parallel_degree e processes_per_host. A matemática simples é a seguinte:
(pipeline_parallel_degree) x (data_parallel_degree) = processes_per_host
A biblioteca se encarrega de calcular o número de réplicas do modelo (também chamado data_parallel_degree) de acordo com os dois parâmetros de entrada que você fornece.
Por exemplo, se você definir "pipeline_parallel_degree": 2 e "processes_per_host": 8 usar uma instância de ML com oito operadores de GPU como, por exemplo, ml.p3.16xlarge, a biblioteca configura automaticamente o modelo distribuído entre as GPUs e o paralelismo de dados em quatro vias. A imagem a seguir ilustra como um modelo é distribuído entre as oito GPUs, alcançando o paralelismo de dados em quatro vias e o paralelismo bidirecional do pipeline. Cada réplica do modelo, na qual a definimos como um grupo paralelo de pipeline e a rotulamos como PP_GROUP, é particionada em duas GPUs. Cada partição do modelo é atribuída a quatro GPUs, onde as quatro réplicas de partição estão em um grupo paralelo de dados e são rotuladas como DP_GROUP. Sem paralelismo de tensores, o grupo paralelo do pipeline é essencialmente o grupo paralelo do modelo.

Para se aprofundar no paralelismo do pipeline, consulte Principais características da biblioteca de SageMaker paralelismo de modelos.
Para começar a executar seu modelo usando o paralelismo de pipeline, consulte Run a Distributed SageMaker Training Job with the SageMaker Model Parallel Library.
Paralelismo de tensores (disponível para) PyTorch
O paralelismo de tensores divide camadas individuais ou nn.Modules, entre dispositivos, para ser executado em paralelo. A figura a seguir mostra o exemplo mais simples de como a biblioteca divide um modelo com quatro camadas para obter o paralelismo de tensores bidirecionais ("tensor_parallel_degree": 2). As camadas de cada réplica do modelo são divididas ao meio e distribuídas em duas GPUs. Nesse caso de exemplo, a configuração paralela do modelo também inclui "pipeline_parallel_degree": 1 and "ddp": True (usa o PyTorch DistributedDataParallel pacote em segundo plano), então o grau de paralelismo de dados se torna oito. A biblioteca gerencia a comunicação entre as réplicas do modelo distribuído por tensor.
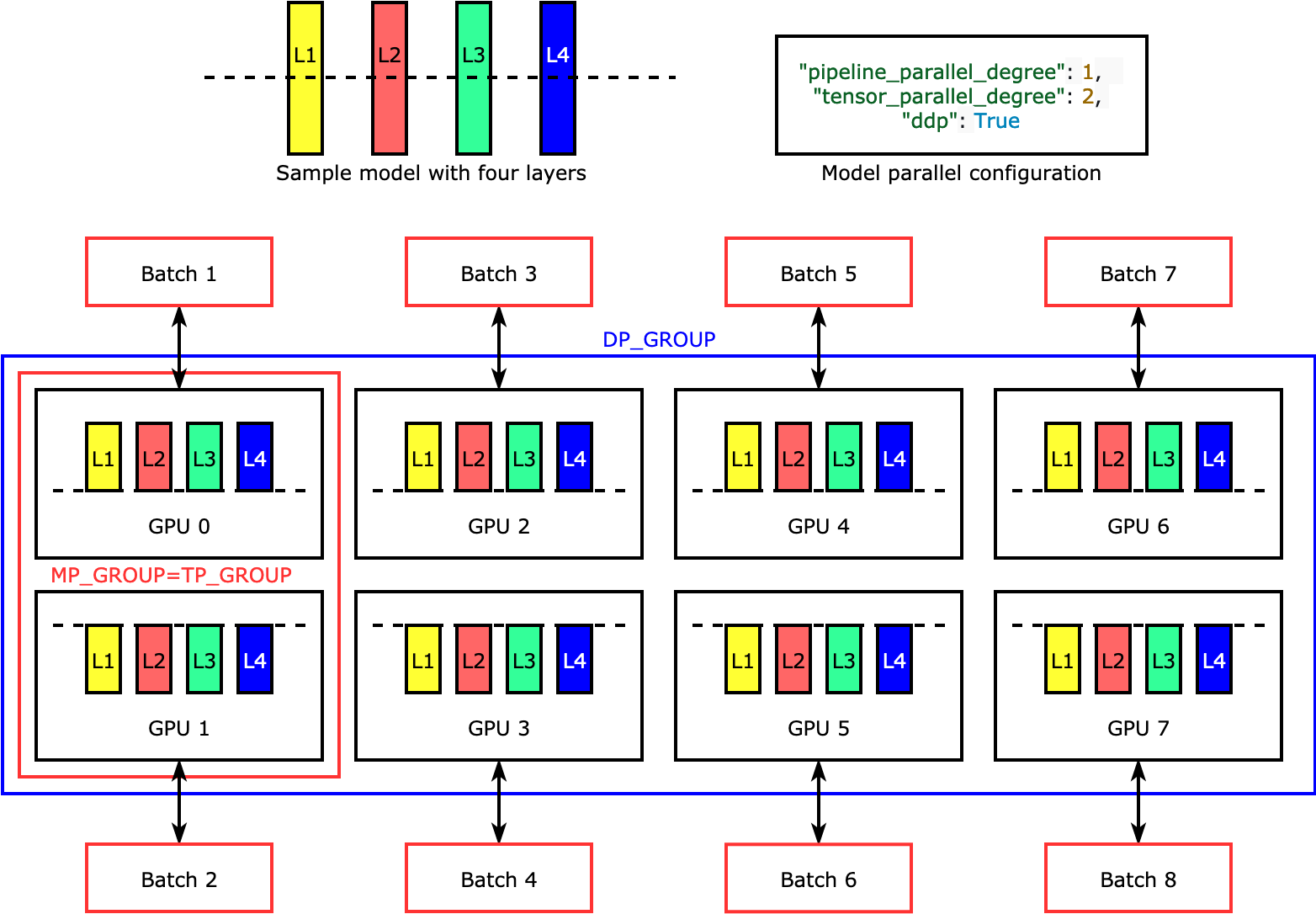
A utilidade desse atributo está no fato de que você pode selecionar camadas específicas ou um subconjunto de camadas para aplicar o paralelismo de tensores. Para se aprofundar no paralelismo de tensores e em outros recursos de economia de memória e aprender como definir uma combinação de paralelismo de pipeline e tensor PyTorch, consulte. Paralelismo de tensores
Fragmentação de estado do otimizador (disponível para) PyTorch
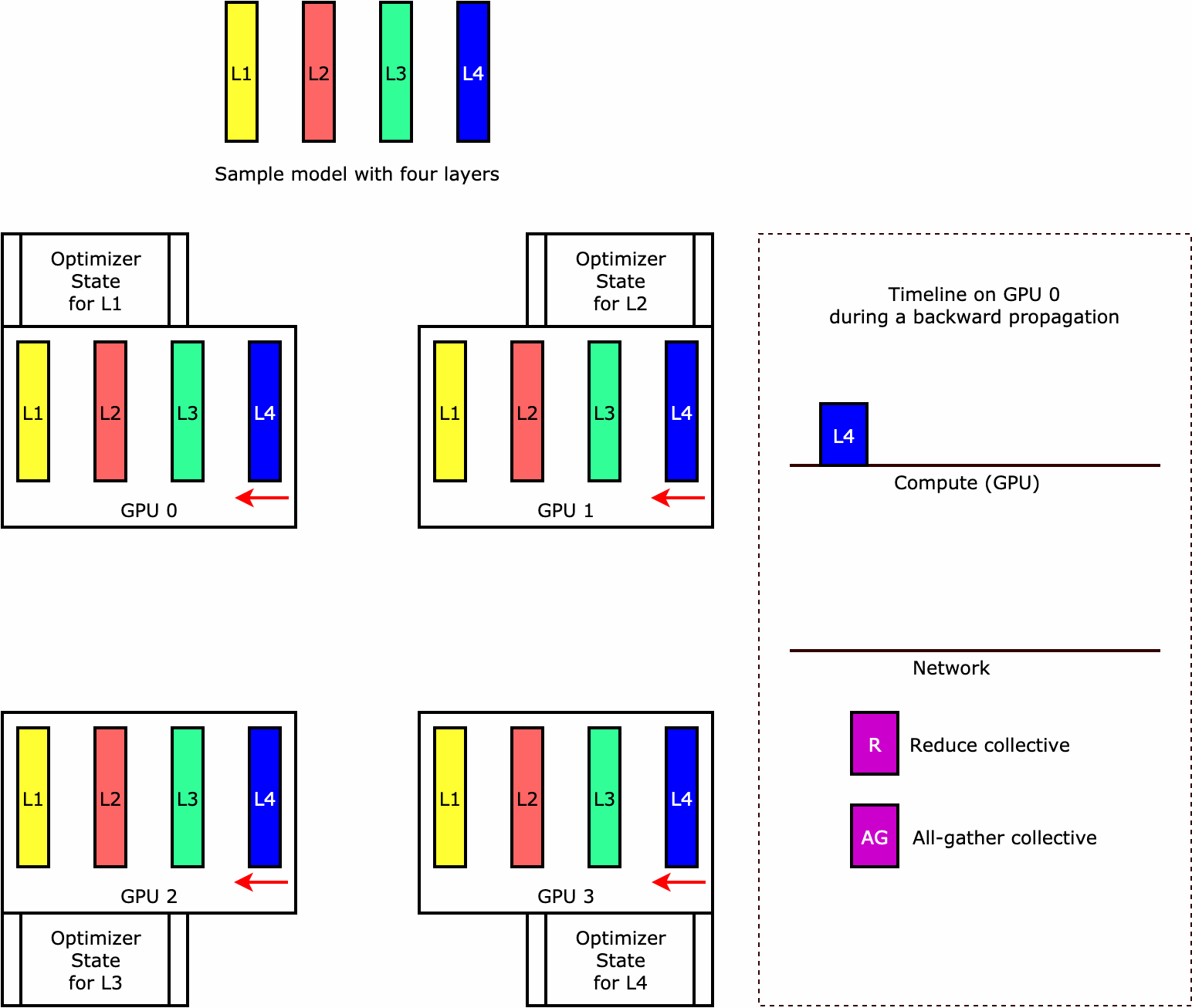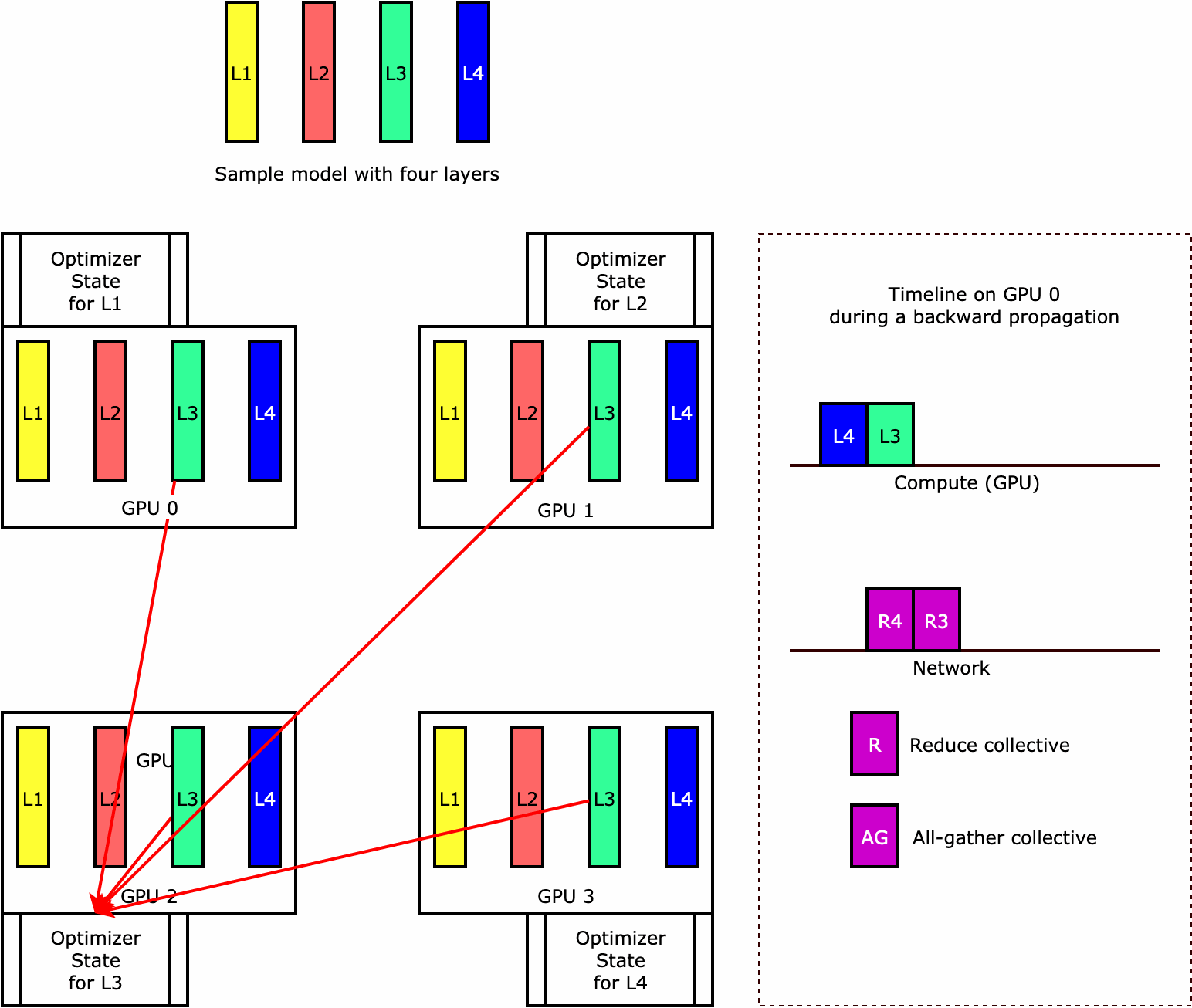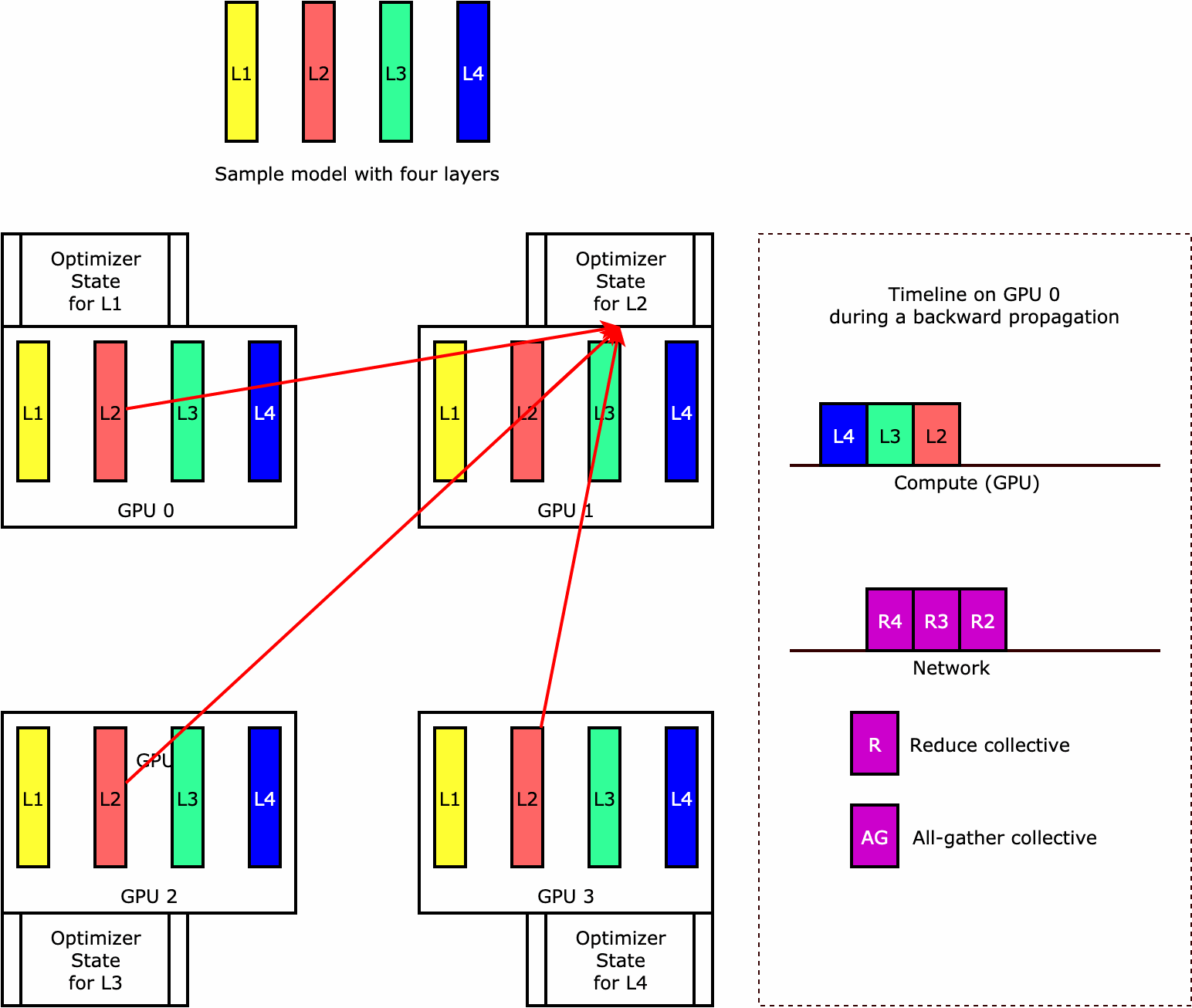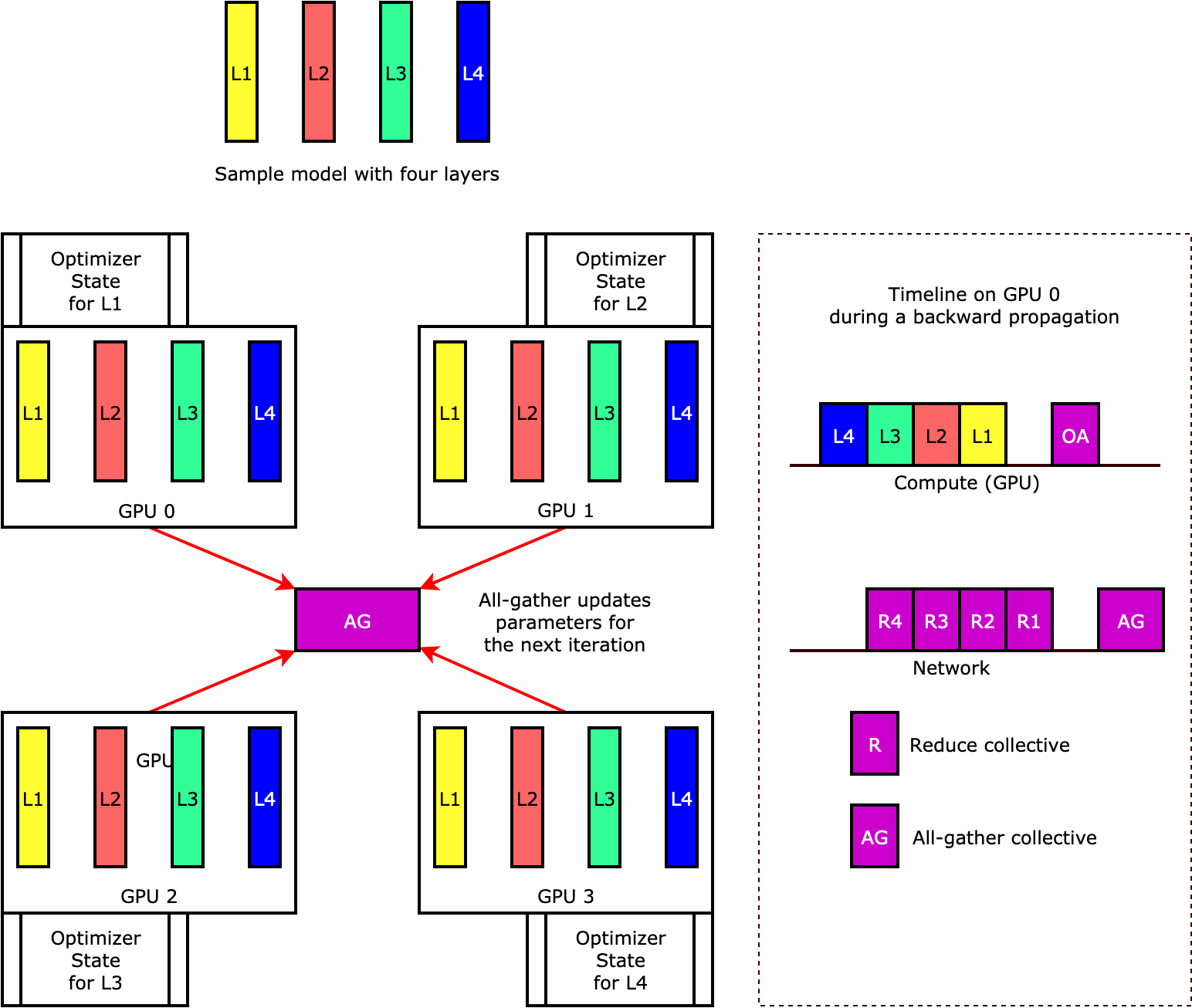
Para entender como a biblioteca executa a fragmentação de estado do otimizador, considere um modelo de exemplo simples com quatro camadas. A ideia principal para otimizar a fragmentação de estado é que você não precisa replicar o estado do otimizador em todas as suas GPUs. Em vez disso, uma única réplica do estado do otimizador é fragmentada em classificações paralelas de dados, sem redundância entre dispositivos. Por exemplo, a GPU 0 mantém o estado do otimizador para a camada um, a próxima GPU 1 mantém o estado do otimizador para a L2 e assim por diante. A figura animada a seguir mostra uma propagação inversa com a técnica de fragmentação de estado do otimizador. No final da propagação reversa, há tempo de computação e rede para a operação optimizer apply (OA) atualizar os estados do otimizador e a operação all-gather (AG) para atualizar os parâmetros do modelo para a próxima iteração. Mais importante ainda, a operação reduce pode se sobrepor à computação na GPU 0, resultando em uma propagação retroativa mais rápida e eficiente em termos de memória. Na implantação atual, as operações AG e OA não se sobrepõem a compute. Isso pode resultar em uma computação estendida durante a operação do AG, portanto, pode haver uma compensação.
Para obter mais informações sobre como usar esse atributo, consulte Fragmentação do estado do otimizador.
Ativação, descarregamento e ponto de verificação (disponível para) PyTorch
Para economizar memória da GPU, a biblioteca oferece apoio ao ponto de verificação de ativação para evitar o armazenamento de ativações internas na memória da GPU para módulos especificados pelo usuário durante a passagem direta. A biblioteca recalcula essas ativações durante a retropassagem. Além disso, o atributo de descarregamento de ativação descarrega as ativações armazenadas na memória da CPU e retorna à GPU durante a retropassagem para reduzir ainda mais o espaço ocupado pela memória de ativação. Para mais informações sobre como usar esses atributo, consulte Ponto de verificação de ativação e Descarregamento de ativação.
Escolhendo as técnicas certas para seu modelo
Para obter mais informações sobre como escolher as técnicas e configurações corretas, consulte Melhores práticas paralelas do modelo SageMaker distribuído e dicas e armadilhas de configuração.
