As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Resultados da recomendação
Cada resultado do trabalho do recomendador de inferência incluiInstanceType, InitialInstanceCount e EnvironmentParameters que são parâmetros variáveis de ambiente ajustados para seu contêiner para melhorar sua latência e throughput. Os resultados também incluem métricas de desempenho e custo como MaxInvocations, ModelLatency, CostPerHour, CostPerInference, CpuUtilization e MemoryUtilization.
Na tabela abaixo, fornecemos uma descrição dessas métricas. Essas métricas podem ajudá-lo a restringir sua busca pela melhor configuração de endpoint adequada ao seu caso de uso. Por exemplo, se sua motivação é o desempenho geral do preço com ênfase na throughput, você deve se concentrar em CostPerInference.
| Métrica | Description | Caso de uso |
|---|---|---|
|
|
O intervalo de tempo gasto por um modelo para responder conforme visualizado pela SageMaker IA. Esse intervalo inclui os tempos de comunicação locais necessários para enviar a solicitação e buscar a resposta do contêiner de um modelo, bem como o tempo gasto para concluir a inferência no contêiner. Unidade: milissegundos |
Workloads sigilosos à latência, como veiculação de anúncios e diagnóstico médico |
|
|
O número máximo de solicitações Unidades: nenhuma |
Throughput-focused cargas de trabalho, como processamento de vídeo ou inferência em lote |
|
|
O custo estimado por hora para seu endpoint em tempo real. Unidades: dólares norte-americanos |
Workloads econômicas sem prazos de latência |
|
|
O custo estimado por chamada de inferência para seu endpoint em tempo real. Unidades: dólares norte-americanos |
Maximizar o desempenho geral de preços com foco na produtividade |
|
|
A utilização de CPU esperada no máximo de invocações por minuto para a instância do endpoint. Unidades: percentual |
Entenda a integridade da instância durante a análise comparativa, tendo visibilidade da utilização da CPU principal da instância |
|
|
A utilização da memória esperada no máximo de invocações por minuto para a instância do endpoint. Unidades: percentual |
Entenda a integridade da instância durante a análise comparativa, tendo visibilidade da utilização da memória principal da instância |
Em alguns casos, talvez você queira explorar outras métricas do SageMaker AI Endpoint Invocation, como. CPUUtilization Cada resultado do trabalho do recomendador de inferência inclui os nomes dos endpoints gerados durante o teste de carga. Você pode usar CloudWatch para revisar os registros desses endpoints mesmo depois de serem excluídos.
A imagem a seguir é um exemplo de CloudWatch métricas e gráficos que você pode analisar para um único endpoint a partir do resultado da recomendação. O resultado dessa recomendação é de um trabalho padrão. A maneira de interpretar os valores escalares dos resultados da recomendação é que eles se baseiem no momento em que o gráfico de invocações começa a se nivelar. Por exemplo, o ModelLatency valor relatado está no início do platô ao redor03:00:31.
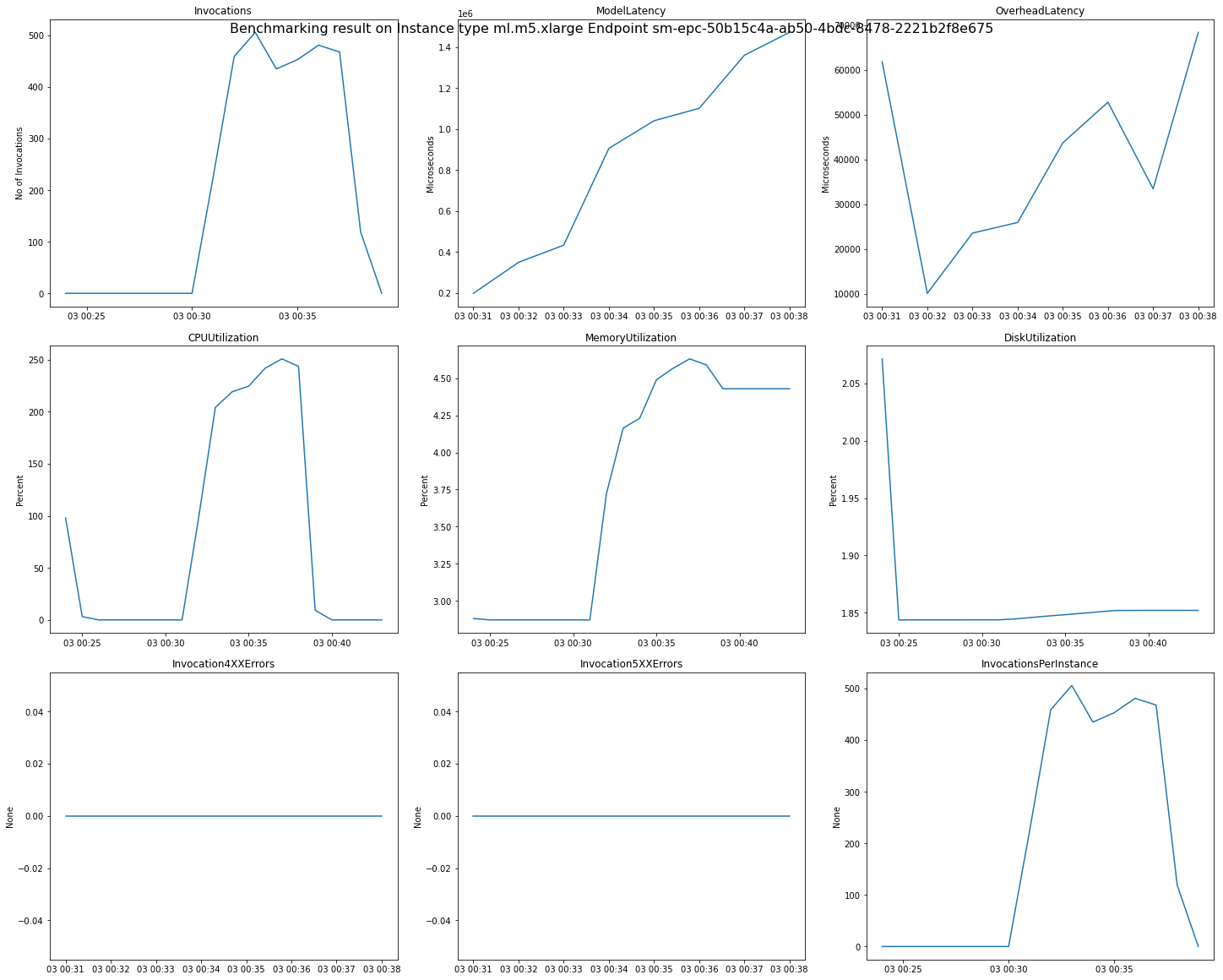
Para obter descrições completas das CloudWatch métricas usadas nos gráficos anteriores, consulte Métricas do SageMaker AI Endpoint Invocation.
Você também pode ver métricas de desempenho semelhantes às ClientInvocations NumberOfUsers publicadas pelo recomendador de inferência no /aws/sagemaker/InferenceRecommendationsJobs namespace. Para obter uma lista completa de métricas e descrições publicadas pelo recomendador de inferência, consulte SageMaker Métricas de empregos do Inference Recommender.
Consulte o notebook Amazon SageMaker Inference Recommender - CloudWatch Metrics
