As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Treinamento de ajuste de escala
As seções a seguir abordam cenários nos quais você pode querer ampliar o treinamento e como fazer isso usando AWS recursos. Talvez você queira escalar o treinamento em uma das seguintes situações:
-
Escalar de uma única GPU para várias GPUs
-
Escalabilidade de uma única instância para várias instâncias
-
Usar scripts de treinamento personalizados
Escalar de uma única GPU para várias GPUs
A quantidade de dados ou o tamanho do modelo usado em machine learning pode criar situações em que o tempo para treinar um modelo é mais longo do que você está disposto a esperar. Às vezes, o treinamento simplesmente não funciona porque o modelo ou os dados de treinamento são muito grandes. Uma solução é aumentar o número de GPUs utilizadas no treinamento. Em uma instância com várias GPUs, como uma instância p3.16xlarge que possui oito GPUs, os dados e o processamento são divididos entre as oito GPUs. Quando você utiliza bibliotecas de treinamento distribuído, isso pode resultar em um aumento quase linear na velocidade com que o modelo é treinado. Demora um pouco mais 1/8 do que demoraria p3.2xlarge com uma GPU.
| Tipo de instância | GPUs |
|---|---|
| p3.2xlarge | 1 |
| p3.8xlarge | 4 |
| p3.16xlarge | 8 |
| p3dn.24xlarge | 8 |
nota
Os tipos de instância ml usados pelo SageMaker treinamento têm o mesmo número de GPUs que os tipos de instância p3 correspondentes. Por exemplo, ml.p3.8xlarge tem o mesmo número de GPUs que p3.8xlarge - 4.
Escalabilidade de uma única instância para várias instâncias
Se quiser escalar ainda mais seu treinamento, você pode usar mais instâncias. No entanto, você deve escolher um tipo de instância maior antes de adicionar mais instâncias. Analise a tabela anterior para ver quantas GPUs existem em cada tipo de instância p3.
Se você passou de uma única GPU em uma instância p3.2xlarge para quatro GPUs em uma instância p3.8xlarge, mas decide que precisa de mais poder de processamento, pode obter melhor desempenho e custos mais baixos se escolher uma instância p3.16xlarge maior antes de tentar aumentar o número de instâncias. Dependendo das bibliotecas que você utiliza, manter seu treinamento em uma única instância pode oferecer melhor desempenho e custos mais baixos do que um cenário em que você utiliza várias instâncias.
Quando estiver pronto para escalar o número de instâncias, você pode fazer isso com a estimator função SageMaker AI Python SDK definindo seu. instance_count Por exemplo, você pode criar instance_type = p3.16xlarge e instance_count =
2. Em vez das oito GPUs em uma única p3.16xlarge, você tem 16 GPUs em duas instâncias idênticas. O gráfico a seguir mostra a escalabilidade e throughput começando com oito GPUs
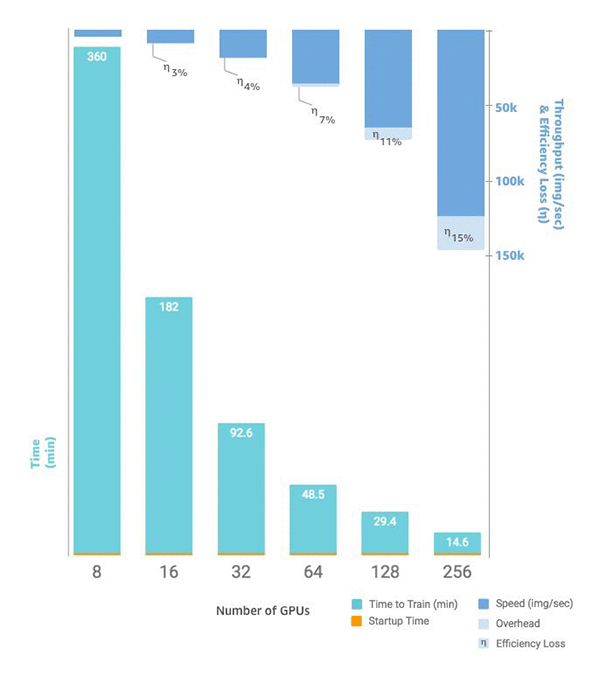
Scripts de treinamento personalizados
Embora a SageMaker IA simplifique a implantação e a escalabilidade do número de instâncias e GPUs, dependendo da estrutura de sua escolha, gerenciar os dados e os resultados pode ser muito desafiador, e é por isso que bibliotecas externas de suporte são frequentemente usadas. Essa forma mais básica de treinamento distribuído exige a modificação do seu script de treinamento para gerenciar a distribuição de dados.
SageMaker A IA também oferece suporte ao Horovod e às implementações de treinamento distribuído nativo de cada estrutura principal de aprendizado profundo. Se você optar por usar exemplos dessas estruturas, poderá seguir o guia de contêineres da SageMaker AI para Deep Learning Containers e vários exemplos de cadernos
