As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Entenda as opções para implantar modelos e obter inferências na Amazon AI SageMaker
Para ajudar você a começar a usar a inferência de SageMaker IA, consulte as seções a seguir, que explicam suas opções para implantar seu modelo em SageMaker IA e obter inferências. A seção Opções de inferência na Amazon AI SageMaker pode ajudá-lo a determinar qual atributo é mais adequado ao seu caso de uso para inferência.
Você pode consultar a Recursos seção para obter mais informações sobre solução de problemas e referência, blogs e exemplos para ajudar você a começar, além de informações comuns FAQs.
Tópicos
Antes de começar
Esses tópicos pressupõem que você tenha criado e treinado um ou mais modelos de machine learning e esteja pronto para implantá-los. Você não precisa treinar seu modelo em SageMaker IA para implantá-lo em SageMaker IA e obter inferências. Se você não tem seu próprio modelo, também pode usar os algoritmos integrados da SageMaker IA ou modelos pré-treinados.
Se você é iniciante na SageMaker IA e ainda não escolheu um modelo para implantar, siga as etapas do tutorial Get Started with Amazon SageMaker AI. Use o tutorial para se familiarizar com a forma como a SageMaker IA gerencia o processo de ciência de dados e como ela lida com a implantação do modelo. Para obter mais informações sobre treinar um modelo, consulte Treinar modelos.
Para informações adicionais, referência e exemplos, consulte o Recursos.
Etapas para a implantação do modelo
Para endpoints de inferência, o fluxo de trabalho geral consiste no seguinte:
Crie um modelo no SageMaker AI Inference apontando para artefatos de modelo armazenados no Amazon S3 e uma imagem de contêiner.
Selecionar uma opção de inferência. Para obter mais informações, consulte Opções de inferência na Amazon AI SageMaker.
Crie uma configuração de endpoint de inferência de SageMaker IA escolhendo o tipo de instância e o número de instâncias que você precisa por trás do endpoint. Você pode usar o Amazon SageMaker Inference Recommender para obter recomendações para tipos de instância. Para Inferência Serverless, você só precisa fornecer a configuração de memória necessária com base no tamanho do seu modelo.
Crie um endpoint de inferência de SageMaker IA.
Invocar seu endpoint para receber uma inferência como resposta.
O diagrama a seguir mostra o fluxo de trabalho anterior.
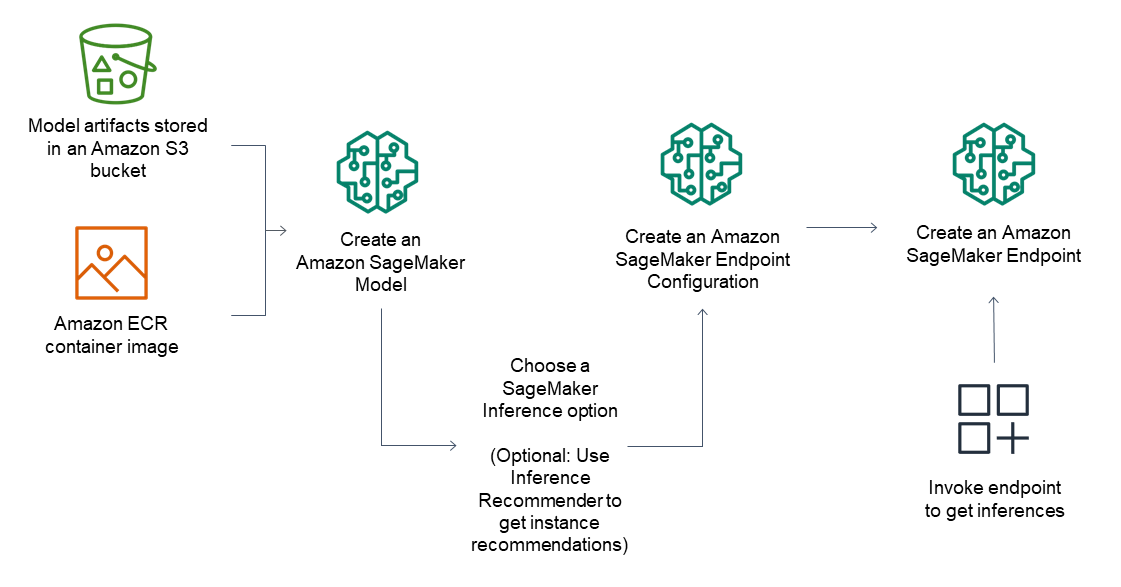
Você pode realizar essas ações usando o AWS console, o AWS SDKs, o SDK do SageMaker Python ou o. CloudFormation AWS CLI
Para inferência em lote com transformação em lote, aponte para os artefatos do modelo e os dados de entrada e crie um trabalho de inferência em lote. Em vez de hospedar um endpoint para inferência, a SageMaker IA envia suas inferências para um local Amazon S3 de sua escolha.
