As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Buckets do Amazon S3
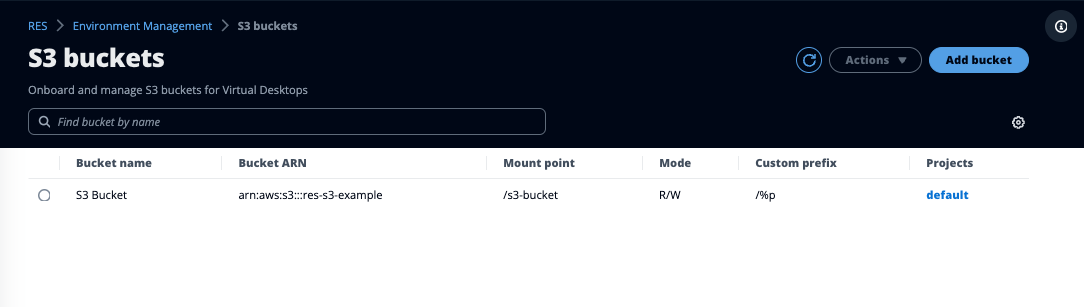
O Research and Engineering Studio (RES) suporta a montagem de buckets do Amazon S3 em instâncias de infraestrutura de desktop virtual (VDI) Linux. Os administradores do RES podem integrar buckets do S3 ao RES, anexá-los aos projetos, editar suas configurações e remover buckets na guia buckets do S3 em Gerenciamento do ambiente.
O painel de buckets do S3 fornece uma lista dos buckets do S3 integrados disponíveis para você. No painel de buckets do S3, você pode:
-
Use Adicionar bucket para integrar um bucket S3 ao RES.
-
Selecione um bucket do S3 e use o menu Ações para:
-
Editar um bucket
-
Remova um balde
-
-
Use o campo de pesquisa para pesquisar pelo nome do bucket e encontrar buckets S3 integrados.
As seções a seguir descrevem como gerenciar buckets do Amazon S3 em seus projetos RES.
Tópicos
