O Amazon Redshift não permitirá mais a criação de UDFs do Python a partir do Patch 198. As UDFs do Python existentes continuarão a funcionar normalmente até 30 de junho de 2026. Para ter mais informações, consulte a [publicação de blog ](https://aws.amazon.com/blogs/big-data/amazon-redshift-python-user-defined-functions-will-reach-end-of-support-after-june-30-2026/).
# Visualizar dados de performance do cluster
Ao usar métricas de cluster no Amazon Redshift, você pode fazer as seguintes tarefas de performance comuns:
+ Determine se as métricas de cluster são anormais em um período especificado e, em caso afirmativo, identifique as consultas responsáveis pela ocorrência de performance.
+ Verifique se as consultas históricas ou atuais estão afetando a performance do cluster. Se identificar uma consulta problemática, você poderá visualizar detalhes sobre ela, incluindo a performance do cluster durante a execução da consulta. Você pode usar essas informações para diagnosticar o motivo da lentidão da consulta e ver o que pode ser feito para melhorar a performance dela.
**Para visualizar os dados de performance**
1. Faça login no Console de gerenciamento da AWS e abra o console do Amazon Redshift em [https://console.aws.amazon.com/redshiftv2/](https://console.aws.amazon.com/redshiftv2/).
1. No menu de navegação, escolha **Clusters** e, em seguida, o nome de um cluster na lista para abrir os detalhes. Os detalhes do cluster são exibidos, podendo incluir as guias **Performance do cluster**, **Monitoramento de consultas**, **Bancos de dados**, **Unidades de compartilhamento de dados**, **Programações**, **Manutenção** e **Propriedades**.
1. Escolha a guia **Cluster performance (Performance do cluster)** para obter informações que incluem o seguinte:
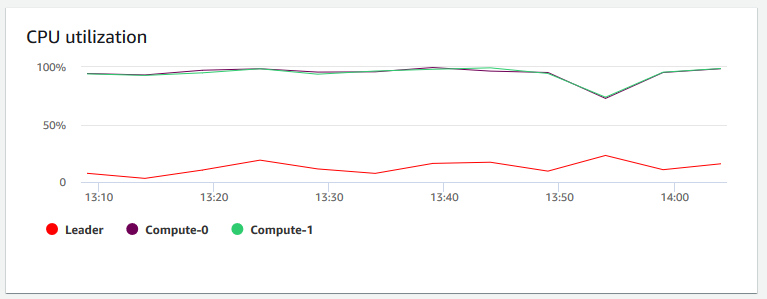
+ **Utilização da CPU**
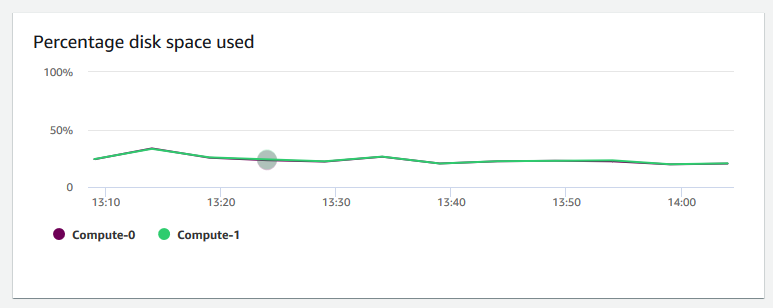
+ **Percentage disk space used (Porcentagem utilizada de espaço em disco**
+ **Conexões de banco de dados**
+ **Status de integridade**
+ **Query duration (Duração de consultas**
+ **Query throughput (Taxa de transferência de consultas**
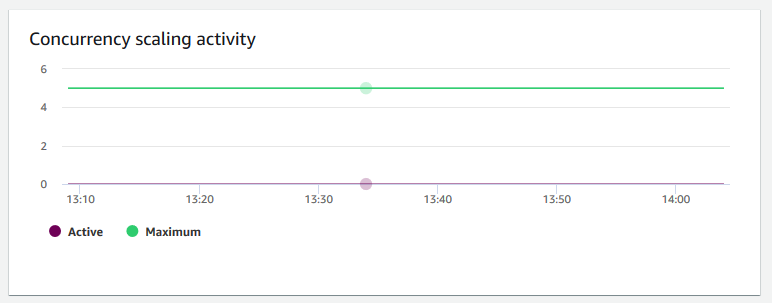
+ **Ação de escalabilidade da simultaneidade**
Muitas métricas novas estão disponíveis. Para ver as métricas disponíveis e escolher quais são exibidas, escolha o ícone **Preferences (Preferências)**
## Gráficos de performance de cluster
Os exemplos a seguir mostram alguns dos gráficos exibidos no novo console do Amazon Redshift.
+ **Utilização da CPU** – Mostra a porcentagem de utilização da CPU para todos os nós (líder e computação). Para localizar um horário em que o uso do cluster seja mais baixo antes de agendar a migração do cluster ou outras operações que consomem recursos, monitore este gráfico para ver a utilização da CPU por nó individual ou por todos os nós.
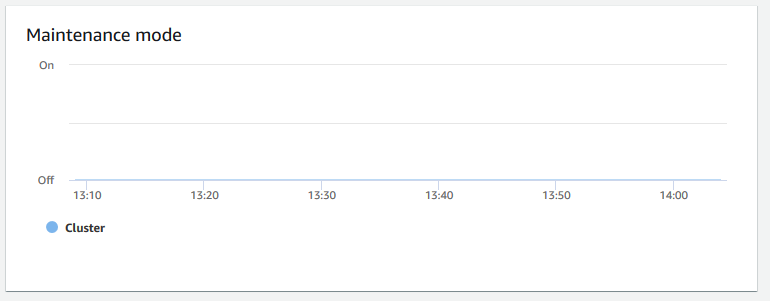
+ **Modo de manutenção** – Mostra se o cluster está no modo de manutenção em um horário escolhido usando os indicadores `On` e `Off`. É possível ver a hora em que o cluster está passando por manutenção. Depois, é possível correlacionar esse tempo com as operações realizadas no cluster para estimar seus tempos de inatividade futuros para eventos recorrentes.
+ **Porcentagem de espaço em disco usado** – Mostra a porcentagem de uso de espaço em disco por cada nó de computação, e não para o cluster como um todo. É possível explorar esse gráfico para monitorar a utilização do disco. Operações de manutenção, como VACUUM e COPY, usam espaço de armazenamento temporário intermediário para suas operações de classificação, portanto, é esperado um pico no uso do disco.
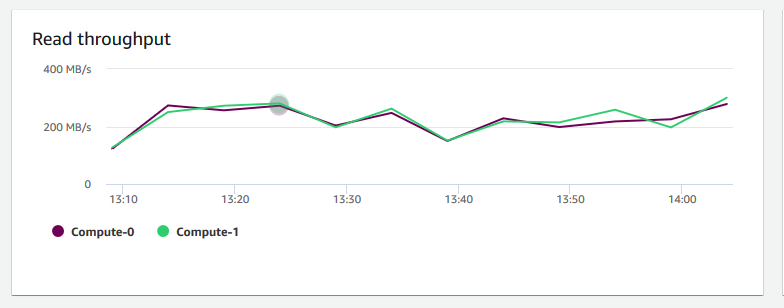
+ **Taxa de transferência de leitura** – Mostra o número médio de megabytes lidos do disco por segundo. É possível avaliar esse gráfico para monitorar o aspecto físico correspondente do cluster. Essa taxa de transferência não inclui o tráfego de rede entre instâncias no cluster e o seu volume.
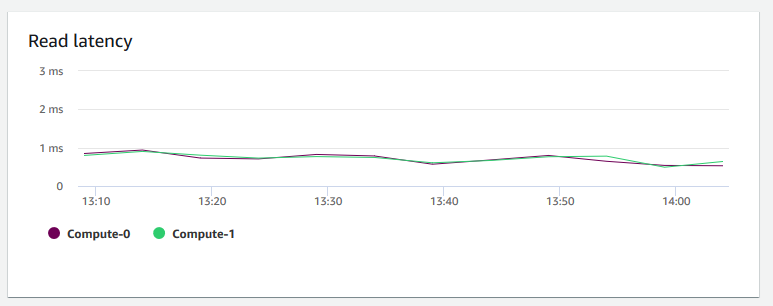
+ **Latência de leitura** – Mostra a quantidade média de tempo gasto para operações de E/S de leitura de disco por milissegundo. É possível visualizar os tempos de resposta dos dados a serem retornados. Quando a latência é alta, isso significa que o remetente gasta mais tempo ocioso (não enviando novos pacotes), o que reduz a rapidez com que a taxa de transferência aumenta.
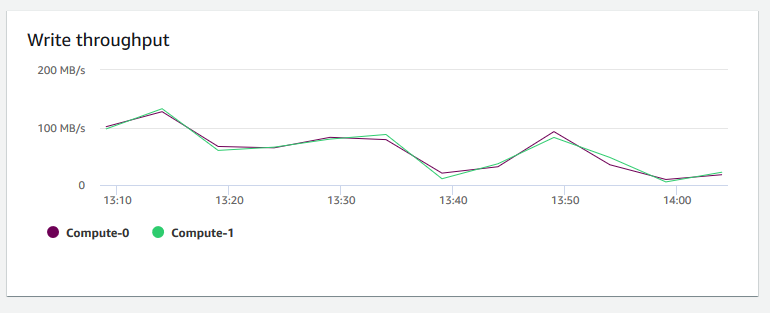
+ **Taxa de transferência de gravação** – Mostra o número médio de megabytes gravados no disco por segundo. É possível avaliar essa métrica para monitorar o aspecto físico correspondente do cluster. Essa taxa de transferência não inclui o tráfego de rede entre instâncias no cluster e o seu volume.
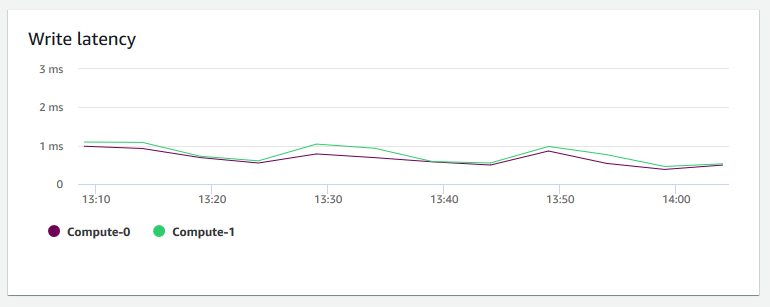
+ **Latência de gravação** – Mostra o tempo médio em milissegundos gasto para operações de E/S de gravação de disco. É possível avaliar o tempo para que a confirmação de gravação seja retornada. Quando a latência é alta, isso significa que o remetente gasta mais tempo ocioso (não enviando novos pacotes), o que reduz a rapidez com que a taxa de transferência aumenta.
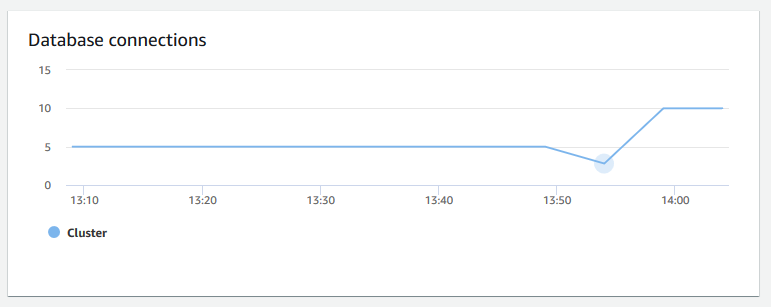
+ **Conexões de banco de dados** – Mostra o número de conexões de banco de dados a um cluster. É possível usar esse gráfico para ver quantas conexões são estabelecidas com o banco de dados e encontrar um horário em que o uso do cluster é menor.
+ **Contagem total de tabelas** – Mostra o número de tabelas de usuário abertas em um determinado momento dentro de um cluster. É possível monitorar a performance do cluster quando a contagem de tabelas abertas é alta.

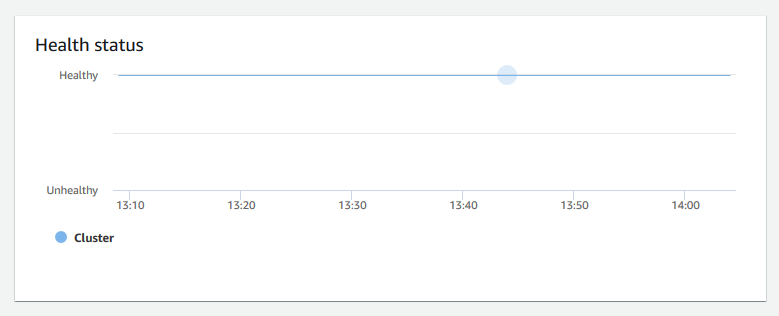
+ **Status de integridade** – Indica a integridade do cluster como `Healthy` ou `Unhealthy`. Se o cluster puder se conectar ao banco de dados e executar uma consulta simples com êxito, o cluster será considerado íntegro. Caso contrário, o cluster está com problemas. Um status não saudável pode ocorrer quando o banco de dados do cluster está sob carga extremamente pesada ou se houver um problema de configuração com um banco de dados no cluster.
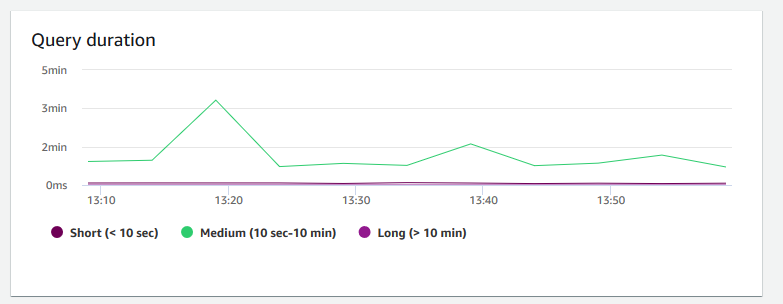
+ **Duração de consultas** – Mostra a quantidade média de tempo para concluir uma consulta em microssegundos. É possível comparar os dados nesse gráfico para medir a performance de E/S dentro do cluster e ajustar suas consultas mais demoradas, se necessário.
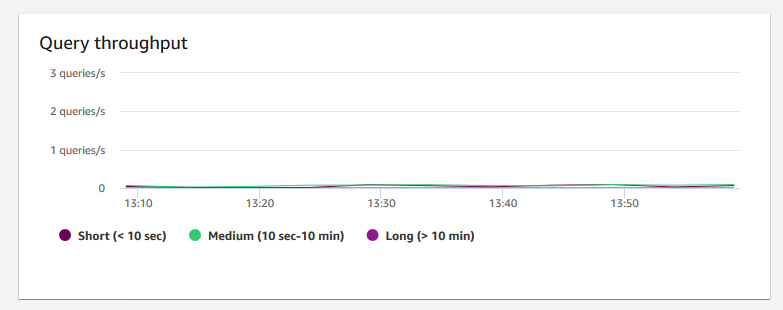
+ **Taxa de transferência de consultas** – Mostra o número médio de consultas concluídas por segundo. É possível analisar dados nesse gráfico para medir a performance do banco de dados e caracterizar a capacidade do sistema de oferecer suporte a um workload multiusuário de forma equilibrada.
+ **Duração de consultas por fila WLM** – Mostra a quantidade média de tempo para concluir uma consulta em microssegundos. É possível comparar os dados nesse gráfico para medir a performance de E/S por fila de WLM e ajustar suas consultas mais demoradas, se necessário.
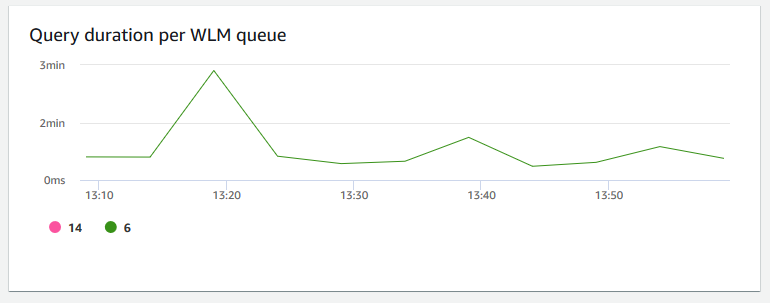
+ **Taxa de transferência de consulta por fila WLM** – Mostra o número médio de consultas concluídas por segundo. É possível analisar dados nesse gráfico para medir a performance do banco de dados por fila do WLM.
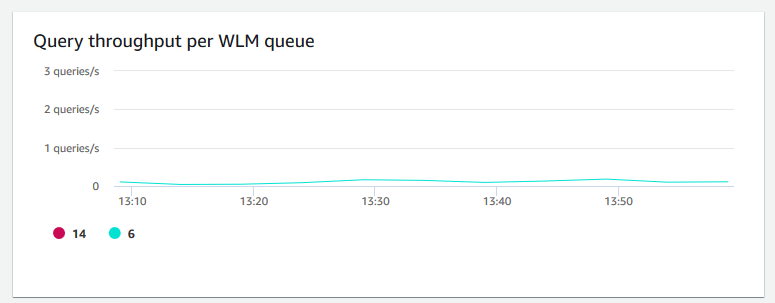
+ **Atividade de escalabilidade de simultaneidade** – Mostra o número de clusters de escalabilidade de simultaneidade ativos. Quando a escalabilidade de simultaneidade está habilitado, o Amazon Redshift adiciona automaticamente capacidade de cluster adicional quando você precisa para processar um aumento nas consultas de leitura simultâneas.