As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Etapas de preparação de dados
A experiência de preparação de dados do Amazon Quick Sight oferece onze tipos poderosos de etapas que permitem transformar seus dados sistematicamente. Cada etapa serve a uma finalidade específica no fluxo de trabalho de preparação de dados.
As etapas podem ser configuradas por meio de uma interface intuitiva no painel Configuração, com feedback imediato visível no painel Visualizar. As etapas podem ser combinadas sequencialmente para criar transformações de dados sofisticadas sem exigir experiência em SQL.
Cada etapa pode receber a entrada de uma tabela física ou a saída de uma etapa anterior. A maioria das etapas aceita uma única entrada, com as etapas Append e Join sendo as exceções — elas exigem exatamente duas entradas.
Input
A etapa de entrada inicia seu fluxo de trabalho de preparação de dados no Quick Sight, permitindo que você selecione e importe dados de várias fontes para transformação nas etapas subsequentes.
Opções de entrada
-
Adicionar conjunto de dados
Aproveite os conjuntos de dados existentes do Quick Sight como fontes de entrada, com base em dados que já foram preparados e otimizados por sua equipe.
-
Adicionar fonte de dados
Conecte-se diretamente a bancos de dados como Amazon Redshift, Athena, RDS ou outras fontes compatíveis selecionando objetos de banco de dados específicos e fornecendo parâmetros de conexão.
-
Adicionar upload de arquivo
Importe dados diretamente de arquivos locais em formatos como CSV, TSV, Excel ou JSON.
Configuração
A etapa de entrada não requer configuração. O painel de visualização exibe os dados importados junto com as informações da fonte, incluindo detalhes da conexão, nome da tabela e metadados da coluna.
Observações de uso
-
Várias etapas de entrada podem existir em um único fluxo de trabalho.
-
Você pode adicionar etapas de entrada em qualquer ponto do seu fluxo de trabalho.
Adicionar colunas calculadas
A etapa Adicionar colunas calculadas permite criar novas colunas usando expressões em nível de linha que realizam cálculos em colunas existentes. Você pode criar novas colunas usando funções e operadores escalares (nível de linha) e aplicar cálculos em nível de linha que façam referência a colunas existentes.
Configuração
Para configurar a etapa Adicionar colunas calculadas, no painel Configuração:
-
Dê um nome à sua nova coluna calculada.
-
Salve seu cálculo.
-
Visualize os resultados da expressão.
-
Adicione mais colunas calculadas conforme necessário.
Observações de uso
-
Somente cálculos escalares (em nível de linha) são suportados nesta etapa.
-
No SPICE, as colunas calculadas são materializadas e funcionam como colunas padrão nas etapas subsequentes.
Alterar tipo de dados
O Quick Sight simplifica o gerenciamento de tipos de dados ao oferecer suporte a quatro tipos de dados abstratos: date decimalinteger,, e. string Esses tipos abstratos eliminam a complexidade mapeando automaticamente vários tipos de dados de origem para seus equivalentes do Quick Sight. Por exemplo,tinyint,smallint,integer, e bigint são todos mapeados parainteger, enquanto datedatetime, e timestamp são mapeados para. date
Essa abstração significa que você só precisa entender os quatro tipos de dados do Quick Sight, pois o Quick Sight lida automaticamente com todas as conversões e cálculos de tipos de dados subjacentes ao interagir com diferentes fontes de dados.
Configuração
Para configurar a etapa Alterar tipo de dados, no painel Configuração:
-
Selecione uma coluna para converter.
-
Escolha o tipo de dados de destino (
stringinteger,decimal, oudate). -
Para conversões de data, especifique as configurações de formato e visualize os resultados com base nos formatos de entrada. Veja os formatos de data compatíveis no Quick Sight.
-
Adicione colunas adicionais para converter conforme necessário.
Observações de uso
-
Converta os tipos de dados de várias colunas em uma única etapa para maior eficiência.
-
Ao usar o SPICE, todas as alterações de tipo de dados são materializadas nos dados importados.
Renomear colunas
A etapa Renomear colunas permite que você modifique os nomes das colunas para que sejam mais descritivos, fáceis de usar e consistentes com as convenções de nomenclatura da sua organização.
Configuração
Para configurar a etapa Renomear colunas, no painel Configuração:
-
Selecione uma coluna para nomear.
-
Insira um novo nome para a coluna selecionada.
-
Adicione mais colunas para renomear conforme necessário.
Observações de uso
-
Todos os nomes das colunas devem ser exclusivos em seu conjunto de dados.
Selecionar colunas
A etapa Selecionar colunas permite que você simplifique seu conjunto de dados incluindo, excluindo e reordenando colunas. Isso ajuda a otimizar sua estrutura de dados removendo colunas desnecessárias e organizando as restantes em uma sequência lógica para análise.
Configuração
Para configurar a etapa Selecionar colunas, no painel Configuração:
-
Escolha colunas específicas para incluir em sua saída.
-
Selecione as colunas em sua ordem preferida para estabelecer a sequência.
-
Use Selecionar tudo para incluir as colunas restantes na ordem original.
-
Exclua colunas indesejadas deixando-as desmarcadas.
Características principais
-
As colunas de saída aparecem na ordem de seleção.
-
Selecionar Tudo preserva a sequência de colunas original.
Observações de uso
-
As colunas não selecionadas são removidas das etapas subsequentes.
-
Otimize o tamanho do conjunto de dados removendo colunas desnecessárias.
Anexar
A etapa Anexar combina verticalmente duas tabelas, semelhante a uma operação SQL UNION ALL. O Quick Sight combina automaticamente as colunas por nome em vez de sequência, permitindo a consolidação eficiente de dados mesmo quando as tabelas têm ordens de colunas diferentes ou números variáveis de colunas.
Configuração
Para configurar a etapa Anexar, no painel Configuração:
-
Selecione duas tabelas de entrada para anexar.
-
Revise a sequência da coluna de saída.
-
Examine quais colunas estão presentes nas duas tabelas versus nas tabelas individuais.
Recursos principais
-
Combina as colunas por nome em vez de sequência.
-
Retém todas as linhas das duas tabelas, incluindo duplicatas.
-
Suporta tabelas com diferentes números de colunas.
-
Segue a sequência de colunas da Tabela 1 para colunas correspondentes e, em seguida, adiciona colunas exclusivas da Tabela 2.
-
Mostra indicadores de origem claros para todas as colunas
Observações de uso
-
Use primeiro a etapa Renomear ao acrescentar colunas com nomes diferentes.
-
Cada etapa de Anexação combina exatamente duas tabelas; use etapas adicionais de Acrescentar para obter mais tabelas.
Ingressar
A etapa Unir combina horizontalmente os dados de duas tabelas com base nos valores correspondentes em colunas especificadas. O Quick Sight suporta os tipos de junção externa esquerda, externa direita, externa completa e interna, fornecendo opções flexíveis para suas necessidades analíticas. A etapa inclui a resolução inteligente de conflitos de colunas que processa automaticamente nomes de colunas duplicados. Embora as uniões automáticas não estejam disponíveis como um tipo específico de associação, você pode obter resultados semelhantes usando a divergência do fluxo de trabalho.
Configuração
Para configurar a etapa de junção, no painel Configuração:
-
Selecione duas tabelas de entrada para unir.
-
Escolha seu tipo de junção (Externa Esquerda, Externa Direita, Externa Completa ou Interna).
-
Especifique as chaves de junção de cada tabela.
-
Analise os conflitos de nomes de colunas resolvidos automaticamente.
Recursos principais
-
Suporta vários tipos de junção para diferentes necessidades analíticas.
-
Resolve automaticamente nomes de colunas duplicados.
-
Aceita colunas calculadas como chaves de junção.
Observações de uso
-
As chaves de junção devem ter tipos de dados compatíveis; use a etapa Alterar tipo de dados, se necessário.
-
Cada etapa de junção combina exatamente duas tabelas; use etapas de junção adicionais para obter mais tabelas.
-
Crie uma etapa de renomeação após a união para personalizar cabeçalhos de coluna resolvidos automaticamente.
Agregar
A etapa Agregar permite resumir os dados agrupando colunas e aplicando operações de agregação. Essa transformação poderosa condensa dados detalhados em resumos significativos com base nas dimensões especificadas. O Quick Sight simplifica operações SQL complexas por meio de uma interface intuitiva, oferecendo funções de agregação abrangentes, incluindo operações avançadas de string, como e. ListAgg ListAgg distinct
Configuração
Para configurar a etapa de agregação, no painel Configuração:
-
Selecione as colunas pelas quais agrupar.
-
Escolha funções de agregação para colunas de medida.
-
Personalize os nomes das colunas de saída.
-
Para
ListAggeListAgg distinct:-
Selecione a coluna a ser agregada.
-
Escolha um separador (vírgula, traço, ponto e vírgula ou linha vertical).
-
-
Visualize os dados resumidos.
Funções suportadas por tipo de dados
| Tipo de dado | Funções compatíveis |
|---|---|
|
Numérico |
|
|
Data |
|
|
String |
|
Recursos principais
-
Aplica funções de agregação diferentes às colunas na mesma etapa.
-
O agrupamento por sem funções de agregação atua como SQL SELECT DISTINCT.
-
ListAggconcatena todos os valores;ListAgg distinctinclui somente valores exclusivos. -
ListAggas funções mantêm a ordem de classificação crescente por padrão.
Observações de uso
-
A agregação reduz significativamente a contagem de linhas em seu conjunto de dados.
-
ListAggeListAgg distinctapoiamdatevalores, mas nãodatetime. -
Use separadores para personalizar a saída de concatenação de strings.
Filtro
A etapa Filtrar permite que você restrinja seu conjunto de dados incluindo somente linhas que atendam a critérios específicos. Você pode aplicar várias condições de filtro em uma única etapa, todas combinadas por meio da AND lógica para ajudar a concentrar sua análise em dados relevantes.
Configuração
Para configurar a etapa Filtro, no painel Configuração:
-
Selecione uma coluna para filtrar.
-
Escolha um operador de comparação.
-
Especifique os valores do filtro com base no tipo de dados da coluna.
-
Adicione condições de filtro adicionais em diferentes colunas, se necessário.
nota
-
Filtros de string com “está em” ou “não está em”: insira vários valores (um por linha).
-
Filtros numéricos e de data: insira valores únicos (exceto “entre”, que requer dois valores).
Operadores compatíveis por tipo de dados
| Tipo de dado | Operadores com suporte |
|---|---|
|
Número inteiro e decimal |
É igual, não é igual Maior que, Menor que É maior ou igual a, É menor ou igual a Está entre |
|
Data |
Depois, antes Está entre É depois ou igual a, É antes ou igual a |
|
String |
É igual, não é igual Começa com, termina com Contém, não contém Está dentro, não está dentro |
Observações de uso
-
Aplique várias condições de filtro em uma única etapa.
-
Combine condições em diferentes tipos de dados.
-
Visualize os resultados filtrados em tempo real.
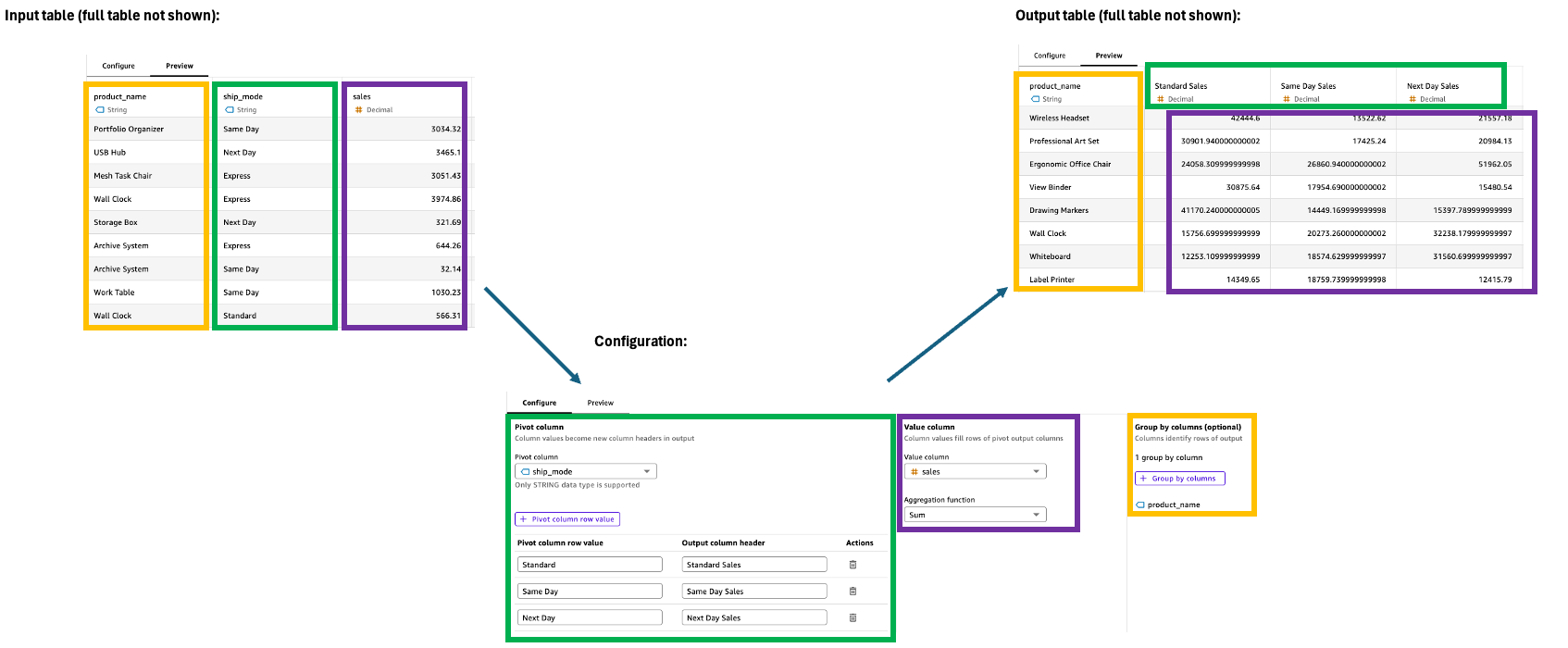
Pivot
A etapa Pivot transforma valores de linha em colunas exclusivas, convertendo dados de um formato longo em um formato amplo para facilitar a comparação e a análise. Essa transformação requer especificações para filtragem, agregação e agrupamento de valores para gerenciar as colunas de saída com eficiência.
Configuração
Para configurar a etapa do Pivot, use o seguinte no painel Configuração:
-
Coluna dinâmica: selecione a coluna cujos valores se tornarão cabeçalhos de coluna (por exemplo, Categoria).
-
Valor da linha da coluna dinâmica: filtre valores específicos a serem incluídos (por exemplo, tecnologia, material de escritório).
-
Cabeçalho da coluna de saída: personalize novos cabeçalhos de coluna (o padrão é dinamizar os valores da coluna).
-
Coluna de valor: selecione a coluna a ser agregada (por exemplo, Vendas).
-
Função de agregação: escolha o método de agregação (por exemplo, soma).
-
Agrupar por: especifique as colunas de organização (por exemplo, Segmento).
Operadores compatíveis por tipo de dados
| Tipo de dado | Operadores com suporte |
|---|---|
|
Número inteiro e decimal |
|
|
Data |
|
|
String |
|
Observações de uso
-
Cada coluna dinâmica contém valores agregados da coluna de valor.
-
Personalize os cabeçalhos das colunas para maior clareza.
-
Visualize os resultados da transformação em tempo real.
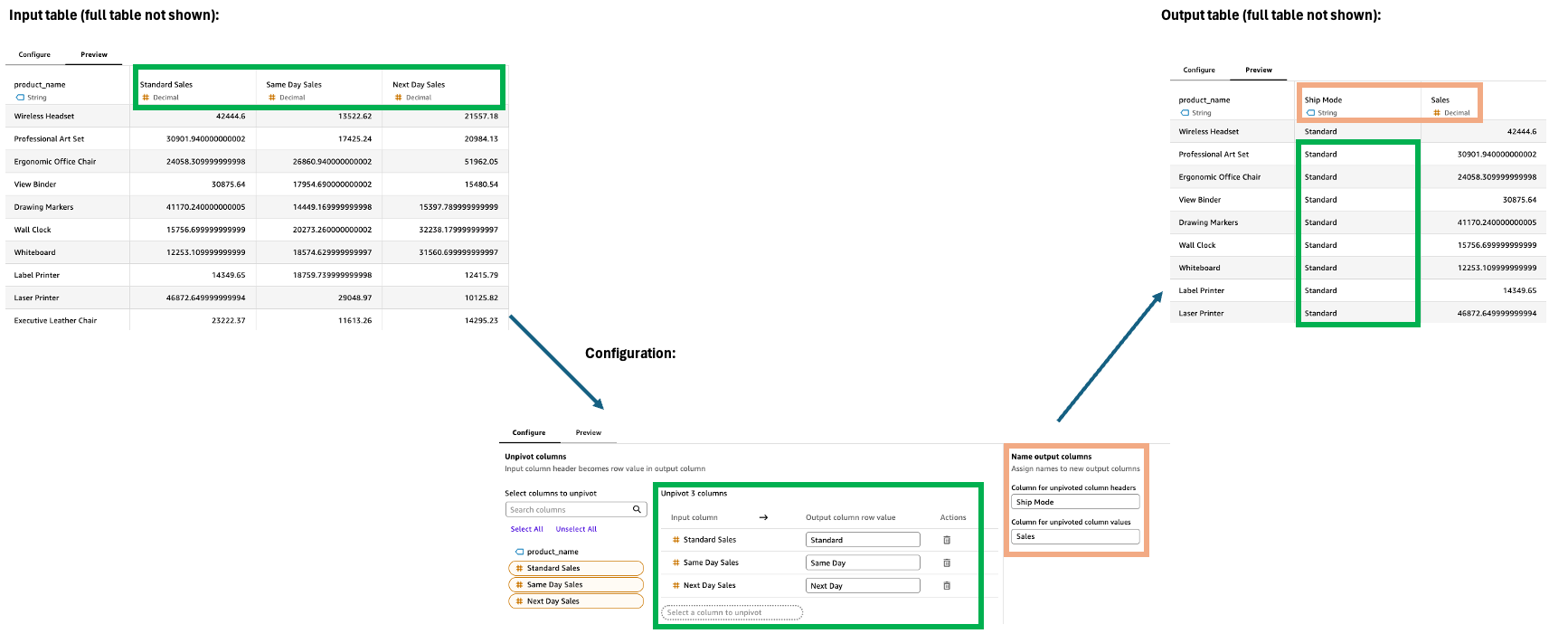
Unpivot
A etapa Unpivot transforma colunas em linhas, convertendo dados amplos em um formato maior e mais estreito. Essa transformação ajuda a organizar os dados espalhados por várias colunas em um formato mais estruturado para facilitar a análise e a visualização.
Configuração
Para configurar a etapa Unpivot, no painel Configuração:
-
Selecione as colunas para desdobrar em linhas.
-
Defina os valores da linha da coluna de saída. O padrão é o nome original da coluna. Alguns exemplos incluem tecnologia, material de escritório e móveis.
-
Nomeie as duas novas colunas de saída.
-
Cabeçalho de coluna não dinâmico: o nome dos nomes das colunas anteriores (por exemplo, Categoria)
-
Valores de coluna não dinâmicos: o nome dos valores não dinâmicos (por exemplo, Vendas)
-
Recursos principais
-
Retém todas as colunas não dinâmicas na saída.
-
Cria duas novas colunas automaticamente: uma para nomes de colunas anteriores e outra para seus valores correspondentes.
-
Transforma dados amplos em formato longo.
Observações de uso
-
Todas as colunas não dinâmicas devem ter tipos de dados compatíveis.
-
A contagem de linhas normalmente aumenta depois de não girar.
-
Visualize as alterações em tempo real antes de aplicá-las.
