As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Reduzir a quantidade de dados verificados
Para começar, considere carregar somente os dados de que você precisa. Você pode melhorar a performance apenas reduzindo a quantidade de dados carregados em seu cluster do Spark para cada fonte de dados. Para avaliar se essa abordagem é apropriada, use as métricas a seguir.
Você pode verificar os bytes lidos do Amazon S3 em CloudWatchmétricas e mais detalhes na interface do usuário do Spark, conforme descrito na seção UI do Spark.
CloudWatch métricas
Você pode ver o tamanho aproximado de leitura do Amazon S3 no Movimentação de dados ETL (Bytes). Essa métrica mostra o número de bytes lidos no Amazon S3 por todos os executores desde o relatório anterior. Você pode usá-la para monitorar a movimentação de dados ETL do Amazon S3 e comparar as leituras com as taxas de ingestão de fontes de dados externas.
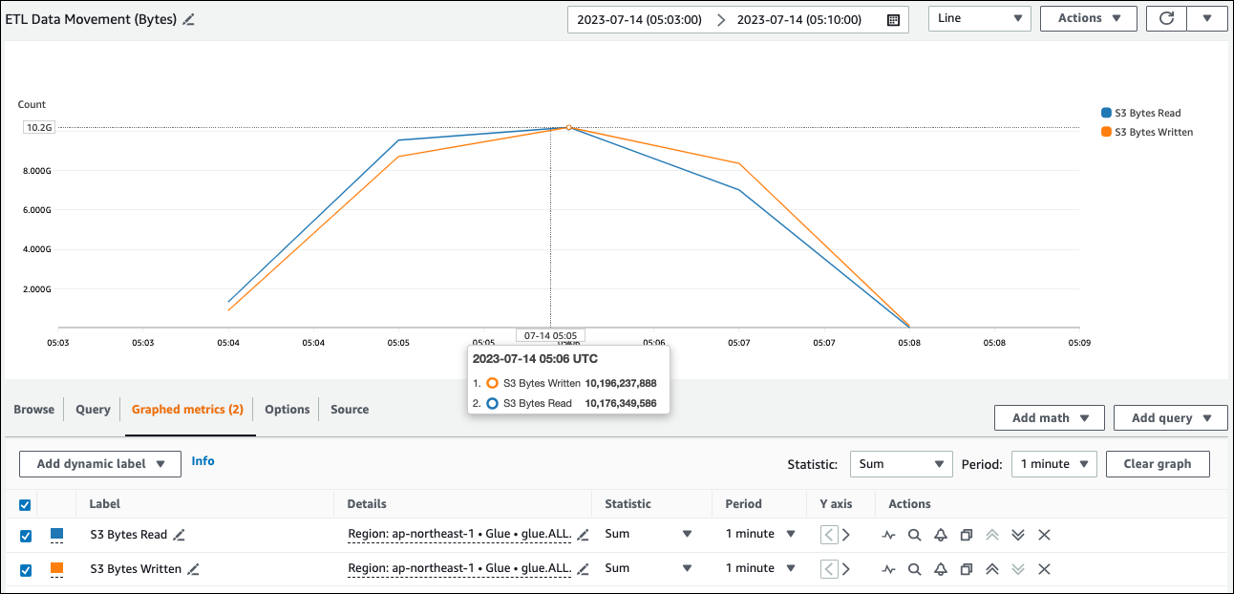
Se você observar um ponto de dados de Bytes lidos do S3 maior do que o esperado, considere as soluções a seguir.
Interface do usuário do Spark
Na guia Stage na interface do AWS Glue usuário do Spark, você pode ver o tamanho de entrada e saída. No exemplo a seguir, a etapa 2 lê a entrada de 47,4 GiB e a saída de 47,7 GiB, enquanto a etapa 5 lê a entrada de 61,2 MiB e a saída de 56,6 MiB.

Quando você usa o Spark SQL ou DataFrame as abordagens em seu AWS Glue trabalho, a DataFrame guia SQL/mostra mais estatísticas sobre esses estágios. Nesse caso, a etapa 2 mostra o número de arquivos lidos: 430, o tamanho dos arquivos lidos: 47,4 GiB e o número de linhas de saída: 160.796.570.
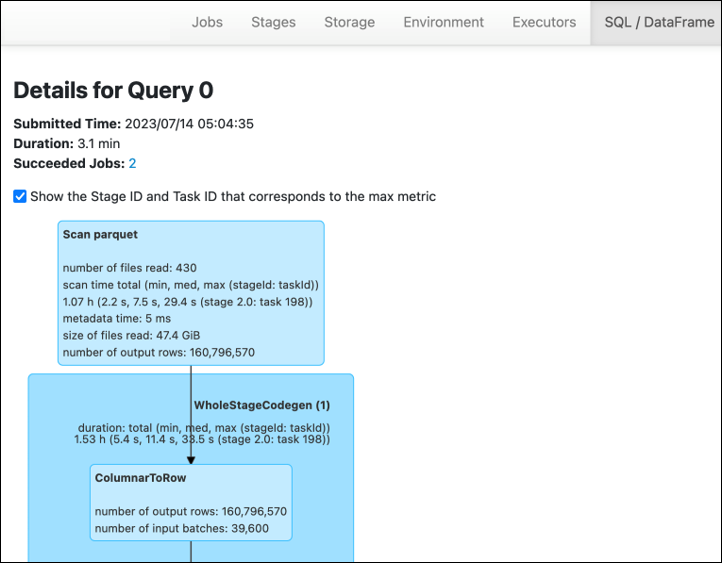
Se você observar que há uma diferença significativa no tamanho entre os dados que você está lendo e os dados que você está usando, tente as soluções a seguir.
Amazon S3
Para reduzir a quantidade de dados carregados em seu trabalho durante a leitura do Amazon S3, considere o tamanho do arquivo, a compactação, o formato do arquivo e o layout do arquivo (partições) do seu conjunto de dados. AWS Glue As tarefas do For Spark geralmente são usadas para ETL de dados brutos, mas para um processamento distribuído eficiente, você precisa inspecionar os recursos do formato da fonte de dados.
-
Tamanho do arquivo: recomendamos manter o tamanho do arquivo de entradas e saídas dentro de uma faixa moderada (por exemplo, 128 MB). Arquivos muito pequenos e muito grandes podem causar problemas.
Um grande número de arquivos pequenos causa os seguintes problemas:
-
Carga de rede pesada no Amazon S3 devido à I/O sobrecarga necessária para fazer solicitações (como
ListGet, ouHead) para muitos objetos (em comparação com alguns objetos que armazenam a mesma quantidade de dados). -
Carga pesada I/O e de processamento no driver Spark, que gerará muitas partições e tarefas e levará a um paralelismo excessivo.
Por outro lado, se o tipo de arquivo não for divisível (como gzip) e os arquivos forem muito grandes, a aplicação do Spark deverá esperar até que uma única tarefa termine de ler o arquivo todo.
Para reduzir o paralelismo excessivo que ocorre quando uma tarefa do Apache Spark é criada para cada arquivo pequeno, use o agrupamento de arquivos para. DynamicFrames Essa abordagem reduz a probabilidade de uma exceção de OOM do driver do Spark. Para configurar o agrupamento de arquivos, defina os parâmetros
groupFilesegroupSize. O exemplo de código a seguir usa a AWS Glue DynamicFrame API em um script ETL com esses parâmetros.dyf = glueContext.create_dynamic_frame_from_options("s3", {'paths': ["s3://input-s3-path/"], 'recurse':True, 'groupFiles': 'inPartition', 'groupSize': '1048576'}, format="json") -
-
Compactação: se seus objetos do S3 estiverem na casa das centenas de megabytes, considere compactá-los. Existem vários formatos de compressão, que podem ser amplamente classificados em dois tipos:
-
Formatos de compactação não divisíveis, como gzip, exigem que o arquivo todo seja descompactado por um operador.
-
Formatos de compactação divisíveis, como bzip2 ou LZO (indexado), permitem a descompactação parcial de um arquivo, que pode ser paralelizado.
Para o Spark (e outros mecanismos comuns de processamento distribuído), você dividirá seu arquivo de dados de origem em fragmentos que seu mecanismo possa processar paralelamente. Essas unidades geralmente são chamadas de splits. Depois que seus dados estiverem em um formato divisível, os AWS Glue leitores otimizados poderão recuperar divisões de um objeto do S3 fornecendo à
GetObjectAPI aRangeopção de recuperar somente blocos específicos. Considere o diagrama a seguir para ver como isso funcionaria na prática.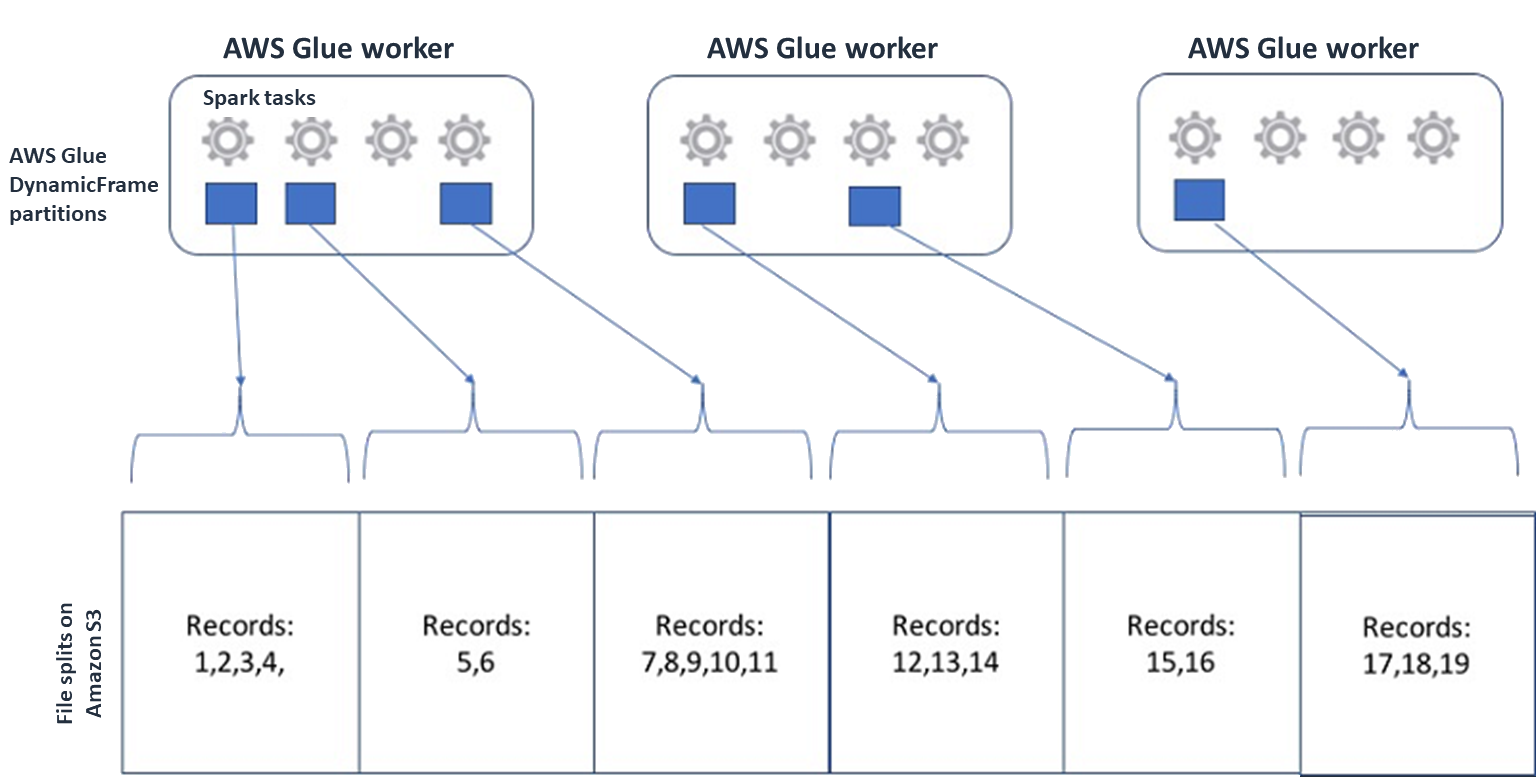
Os dados compactados podem acelerar significativamente sua aplicação, desde que os arquivos tenham um tamanho ideal ou sejam divisíveis. Os tamanhos de dados menores reduzem os dados verificados do Amazon S3 e o tráfego de rede do Amazon S3 para seu cluster do Spark. Por outro lado, é necessária mais CPU para compactar e descompactar dados. A quantidade de computação necessária é escalada com a taxa de compactação do seu algoritmo de compactação. Considere essa compensação ao escolher seu formato de compactação divisível.
nota
Embora os arquivos gzip geralmente não sejam divisíveis, você pode compactar blocos de parquet individuais com gzip, e esses blocos podem ser paralelizados.
-
-
Formato de arquivo: use um formato colunar. O Apache Parquet
e o Apache ORC são formatos de dados colunares conhecidos. O Parquet e o ORC armazenam dados de forma eficiente empregando compactação baseada em colunas, codificando e compactando cada coluna com base em seu tipo de dados. Para obter mais informações sobre codificações do Parquet, consulte Parquet encoding definitions . Os arquivos do Parquet também são divisíveis. Os formatos colunares agrupam valores por coluna e os armazenam juntos em blocos. Ao usar formatos colunares, você pode ignorar blocos de dados que correspondam às colunas que você não planeja usar. As aplicações do Spark podem recuperar somente as colunas de que você precisa. Geralmente, melhores taxas de compactação ou ignorar blocos de dados significa ler menos bytes do Amazon S3, o que resulta em uma melhor performance. Ambos os formatos também são compatíveis com as seguintes abordagens de pushdown para reduzir a E/S:
-
Pushdown de projeção: o pushdown de projeção é uma técnica para recuperar somente as colunas especificadas em sua aplicação. Você especifica colunas na sua aplicação do Spark, conforme mostrado nos seguintes exemplos:
-
DataFrame exemplo:
df.select("star_rating") -
Exemplo do Spark SQL:
spark.sql("select start_rating from <table>")
-
-
Pushdown de predicados: o pushdown de predicados é uma técnica para processar de forma eficiente as cláusulas
WHEREeGROUP BY. Ambos os formatos têm blocos de dados que representam os valores das colunas. Cada bloco contém estatísticas do bloco, como valores máximos e mínimos. O Spark pode usar essas estatísticas para determinar se o bloco deve ser lido ou ignorado, dependendo do valor do filtro usado na aplicação. Para usar esse recurso, adicione mais filtros nas condições, conforme mostrado nos seguintes exemplos:-
DataFrame exemplo:
df.select("star_rating").filter("star_rating < 2") -
Exemplo do Spark SQL:
spark.sql("select * from <table> where star_rating < 2")
-
-
-
Layout do arquivo: ao armazenar seus dados do S3 em objetos em caminhos diferentes com base em como os dados serão usados, você pode recuperar dados relevantes com eficiência. Para obter mais informações, consulte Organizar objetos usando prefixos na documentação do Amazon S3. O AWS Glue tem suporte para armazenamento de chaves e valores nos prefixos do Amazon S3 no formato
key=value, particionando seus dados pelo caminho do Amazon S3. Ao particionar seus dados, você pode restringir a quantidade de dados verificados por cada aplicação de analytics downstream, melhorando a performance e reduzindo o custo. Para obter mais informações, consulte Gerenciando partições para saída ETL em. AWS GlueO particionamento divide sua tabela em partes diferentes e mantém os dados relacionados em arquivos agrupados com base nos valores das colunas, como ano, mês e dia, conforme mostrado no exemplo a seguir.
# Partitioning by /YYYY/MM/DD s3://<YourBucket>/year=2023/month=03/day=31/0000.gz s3://<YourBucket>/year=2023/month=03/day=01/0000.gz s3://<YourBucket>/year=2023/month=03/day=02/0000.gz s3://<YourBucket>/year=2023/month=03/day=03/0000.gz ...Você pode definir partições para seu conjunto de dados modelando-o com uma tabela no AWS Glue Data Catalog. Você pode então restringir a quantidade de dados verificados usando o descarte de partições da seguinte forma:
-
Para AWS Glue DynamicFrame, defina
push_down_predicate(oucatalogPartitionPredicate).dyf = Glue_context.create_dynamic_frame.from_catalog( database=src_database_name, table_name=src_table_name, push_down_predicate = "year='2023' and month ='03'", ) -
Para o Spark DataFrame, defina um caminho fixo para remover partições.
df = spark.read.format("json").load("s3://<YourBucket>/year=2023/month=03/*/*.gz") -
Para o Spark SQL, você pode definir a cláusula where para descartar partições do Catálogo de Dados.
df = spark.sql("SELECT * FROM <Table> WHERE year= '2023' and month = '03'") -
Para particionar por data ao gravar seus dados com AWS Glue, você define partitionKeys DynamicFrame in ou partitionBy (
) com as informações de data DataFrame em suas colunas da seguinte forma. -
DynamicFrame
glue_context.write_dynamic_frame_from_options( frame= dyf, connection_type='s3',format='parquet' connection_options= { 'partitionKeys': ["year", "month", "day"], 'path': 's3://<YourBucket>/<Prefix>/' } ) -
DataFrame
df.write.mode('append')\ .partitionBy('year','month','day')\ .parquet('s3://<YourBucket>/<Prefix>/')
Isso pode melhorar a performance dos consumidores de seus dados de saída.
Se você não tiver acesso para alterar o pipeline que cria seu conjunto de dados de entrada, o particionamento não é uma opção. Em vez disso, você pode excluir caminhos do S3 desnecessários usando padrões globais. Defina exclusões ao ler. DynamicFrame Por exemplo, o código a seguir exclui dias nos meses 01 a 09, no ano de 2023.
dyf = glueContext.create_dynamic_frame.from_catalog( database=db, table_name=table, additional_options = { "exclusions":"[\"**year=2023/month=0[1-9]/**\"]" }, transformation_ctx='dyf' )Você também pode definir exclusões nas propriedades da tabela no Catálogo de Dados:
-
Chave:
exclusions -
Valor:
["**year=2023/month=0[1-9]/**"]
-
-
-
Muitas partições do Amazon S3: evite particionar seus dados do Amazon S3 em colunas que contenham uma grande variedade de valores, como uma coluna de ID com milhares de valores. Isso pode aumentar substancialmente o número de partições em seu bucket, porque o número de partições possíveis é o produto de todos os campos pelos quais você particionou. Muitas partições podem causar o seguinte:
-
Maior latência para recuperar metadados de partição do Catálogo de Dados
-
Maior número de arquivos pequenos, o que exige mais solicitações de API do Amazon S3 (
List,GeteHead)
Por exemplo, quando você define um tipo de data em
partitionByoupartitionKeys, o particionamento em nível de data comoyyyy/mm/ddé bom para muitos casos de uso. No entanto,yyyy/mm/dd/<ID>pode gerar tantas partições que isso afetaria negativamente a performance como um todo.Por outro lado, alguns casos de uso, como aplicações de processamento em tempo real, exigem muitas partições, como
yyyy/mm/dd/hh. Se seu caso de uso exigir partições substanciais, considere usar índices de partição do AWS Glue para reduzir a latência na recuperação de metadados de partições do Catálogo de Dados. -
Bancos de dados e JDBC
Para reduzir a verificação de dados ao recuperar informações de um banco de dados, você pode especificar um predicado where (ou cláusula) em uma consulta SQL. Os bancos de dados que não dispõem de uma interface SQL fornecerão seu próprio mecanismo de consulta ou filtragem.
Ao usar conexões do Java Database Connectivity (JDBC), forneça uma consulta de seleção com a cláusula where para os seguintes parâmetros:
-
Para DynamicFrame, use a opção SampleQuery. Ao usar
create_dynamic_frame.from_catalog, configure o argumentoadditional_optionscomo a seguir.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_catalog( database = db, table_name = table, additional_options={ "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True }, transformation_ctx = "datasource0" )Ao
using create_dynamic_frame.from_options, configure o argumentoconnection_optionscomo a seguir.query = "SELECT * FROM <TableName> where id = 'XX' AND" datasource0 = glueContext.create_dynamic_frame.from_options( connection_type = connection, connection_options={ "url": url, "user": user, "password": password, "dbtable": table, "sampleQuery": query, "hashexpression": key, "hashpartitions": 10, "enablePartitioningForSampleQuery": True } ) -
Para DataFrame, use a opção de consulta
. query = "SELECT * FROM <TableName> where id = 'XX'" jdbcDF = spark.read \ .format('jdbc') \ .option('url', url) \ .option('user', user) \ .option('password', pwd) \ .option('query', query) \ .load() -
Para o Amazon Redshift, use a AWS Glue versão 4.0 ou posterior para aproveitar o suporte a push down no conector Amazon Redshift Spark.
dyf = glueContext.create_dynamic_frame.from_catalog( database = "redshift-dc-database-name", table_name = "redshift-table-name", redshift_tmp_dir = args["temp-s3-dir"], additional_options = {"aws_iam_role": "arn:aws:iam::role-account-id:role/rs-role-name"} ) -
Para outros bancos de dados, consulte a documentação do banco de dados.
AWS Glue opções
-
Para evitar uma verificação completa de todas as execuções contínuas de trabalhos e processar somente os dados que não estavam presentes durante a última execução do trabalho, habilite os marcadores de tarefas.
-
Para limitar a quantidade de dados de entrada a serem processados, habilite a execução delimitada com marcadores de tarefas. Isso ajuda a reduzir a quantidade de dados verificados para cada execução de trabalho.
