As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimizar funções definidas pelo usuário
User-defined funções (UDFs) e, PySpark muitas vezesRDD.map, degradam significativamente o desempenho. Isso se deve à sobrecarga necessária para representar com precisão seu código Python na implementação subjacente do Scala do Spark.
O diagrama a seguir mostra a arquitetura dos PySpark trabalhos. Quando você usa PySpark, o driver do Spark usa a biblioteca Py4j para chamar métodos Java do Python. Ao chamar o Spark SQL ou funções DataFrame integradas, há pouca diferença de desempenho entre Python e Scala porque as funções são executadas na JVM de cada executor usando um plano de execução otimizado.
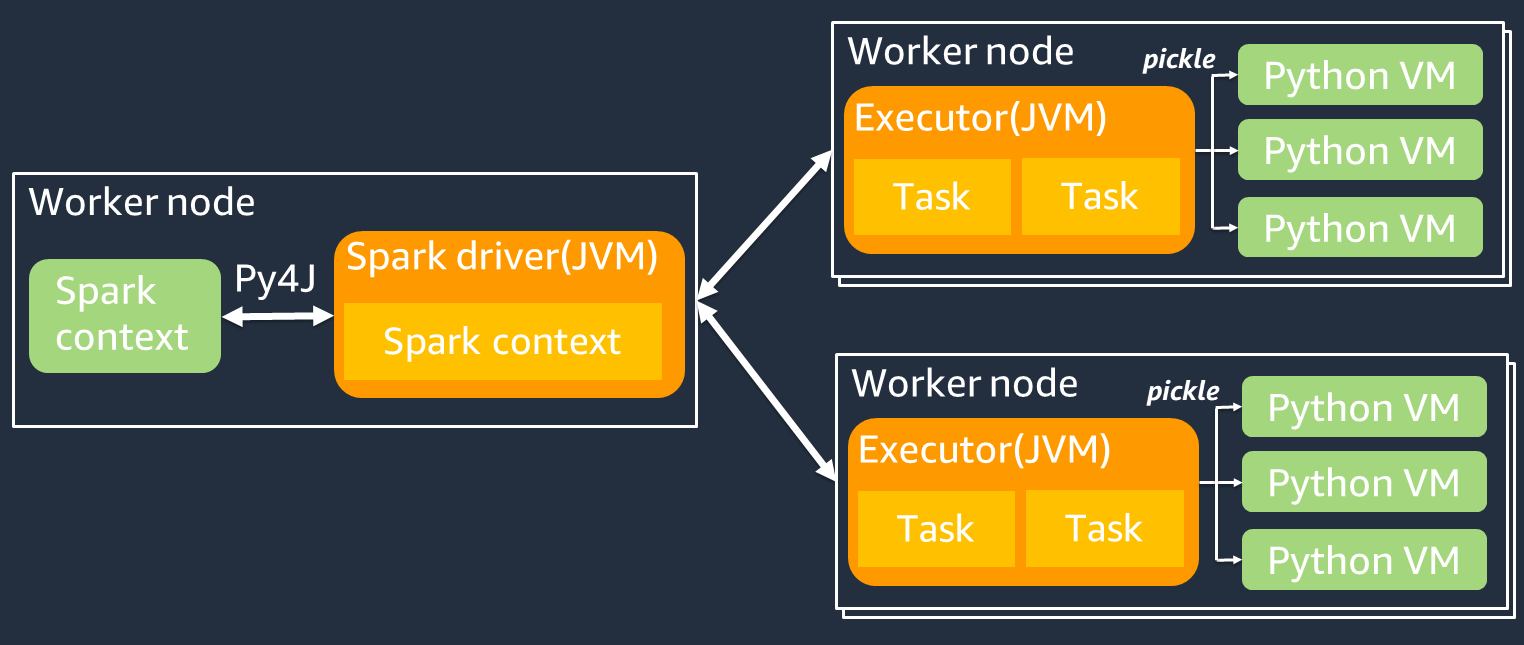
Se você usar sua própria lógica do Python, como usar map/ mapPartitions/ udf, a tarefa será executada em um ambiente de runtime do Python. O gerenciamento de dois ambientes gera um custo de sobrecarga. Além disso, seus dados na memória devem ser transformados para serem usados pelas funções integradas do ambiente de runtime da JVM. O Pickle é um formato de serialização usado por padrão para a troca entre os runtimes da JVM e do Python. No entanto, o custo da serialização e desserialização é muito alto, então as UDFs escritas em Java ou Scala são mais rápidas do que as UDFs em Python.
Para evitar a sobrecarga de serialização e desserialização PySpark, considere o seguinte:
-
Use as funções integradas do Spark SQL — Considere substituir sua própria UDF ou função de mapa pelo Spark SQL ou DataFrame por funções integradas. Ao executar o Spark SQL ou funções DataFrame integradas, há pouca diferença de desempenho entre o Python e o Scala porque as tarefas são gerenciadas na JVM de cada executor.
-
Implemente UDFs em Scala ou Java: considere usar uma UDF escrita em Java ou Scala, porque elas são executadas na JVM.
-
Use Arrow-based UDFs do Apache para cargas de trabalho vetorizadas — Considere usar UDFs. Arrow-based Esse recurso também é conhecido como UDF Vetorizada (Pandas UDF). O Apache Arrow
é um formato de dados em memória independente de linguagem que AWS Glue pode ser usado para transferir dados com eficiência entre processos JVM e Python. Atualmente, isso é mais benéfico para usuários de Python que trabalham com Pandas ou dados. NumPy A seta é um formato colunar (vetorizado). Seu uso não é automático e pode exigir algumas pequenas alterações na configuração ou no código para aproveitar ao máximo e garantir a compatibilidade. Para obter mais detalhes e limitações, consulte Apache Arrow em PySpark
. O exemplo a seguir compara uma UDF incremental básica no Python padrão, como uma UDF Vetorizada, e no Spark SQL.
UDF Python padrão
O tempo do exemplo é 3,20 (seg.).
Código de exemplo
# DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # UDF Example def plus(a,b): return a+b spark.udf.register("plus",plus) df.selectExpr("count(plus(a,b))").collect()
Plano de execução
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#124)]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#580] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#124)]) +- Project [pythonUDF0#124] +- BatchEvalPython [plus(a#116L, b#117L)], [pythonUDF0#124] +- Project [id#114L AS a#116L, id#114L AS b#117L] +- Range (0, 10000000, step=1, splits=16)
UDF Vetorizada
O tempo do exemplo é 0,59 (seg.).
A UDF Vetorizada é cinco vezes mais rápida do que o exemplo anterior da UDF. Ao verificar Physical Plan, você pode ver ArrowEvalPython, o que mostra que essa aplicação é vetorizada pelo Apache Arrow. Para habilitar a UDF Vetorizada, você deve especificar spark.sql.execution.arrow.pyspark.enabled = true em seu código.
Código de exemplo
# Vectorized UDF from pyspark.sql.types import LongType from pyspark.sql.functions import count, pandas_udf # Enable Apache Arrow Support spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true") # DataSet df = spark.range(10000000).selectExpr("id AS a","id AS b") # Annotate pandas_udf to use Vectorized UDF @pandas_udf(LongType()) def pandas_plus(a,b): return a+b spark.udf.register("pandas_plus",pandas_plus) df.selectExpr("count(pandas_plus(a,b))").collect()
Plano de execução
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- HashAggregate(keys=[], functions=[count(pythonUDF0#1082L)], output=[count(pandas_plus(a, b))#1080L]) +- Exchange SinglePartition, ENSURE_REQUIREMENTS, [id=#5985] +- HashAggregate(keys=[], functions=[partial_count(pythonUDF0#1082L)], output=[count#1084L]) +- Project [pythonUDF0#1082L] +- ArrowEvalPython [pandas_plus(a#1074L, b#1075L)], [pythonUDF0#1082L], 200 +- Project [id#1072L AS a#1074L, id#1072L AS b#1075L] +- Range (0, 10000000, step=1, splits=16)
Spark SQL
O tempo do exemplo é 0,087 (seg.).
O Spark SQL é muito mais rápido do que a UDF Vetorizada, porque as tarefas são executadas na JVM de cada executor sem um runtime do Python. Se você puder substituir sua UDF por uma função integrada, recomendamos que o faça.
Código de exemplo
df.createOrReplaceTempView("test") spark.sql("select count(a+b) from test").collect()
Uso de pandas para big data
Se você já está familiarizado com pandas
