As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Principais tópicos no Apache Spark
Esta seção explica os conceitos básicos do Apache Spark e os principais tópicos AWS Glue para ajuste do desempenho do Apache Spark. É importante entender esses conceitos e tópicos antes de analisar estratégias de ajuste no mundo real.
Arquitetura
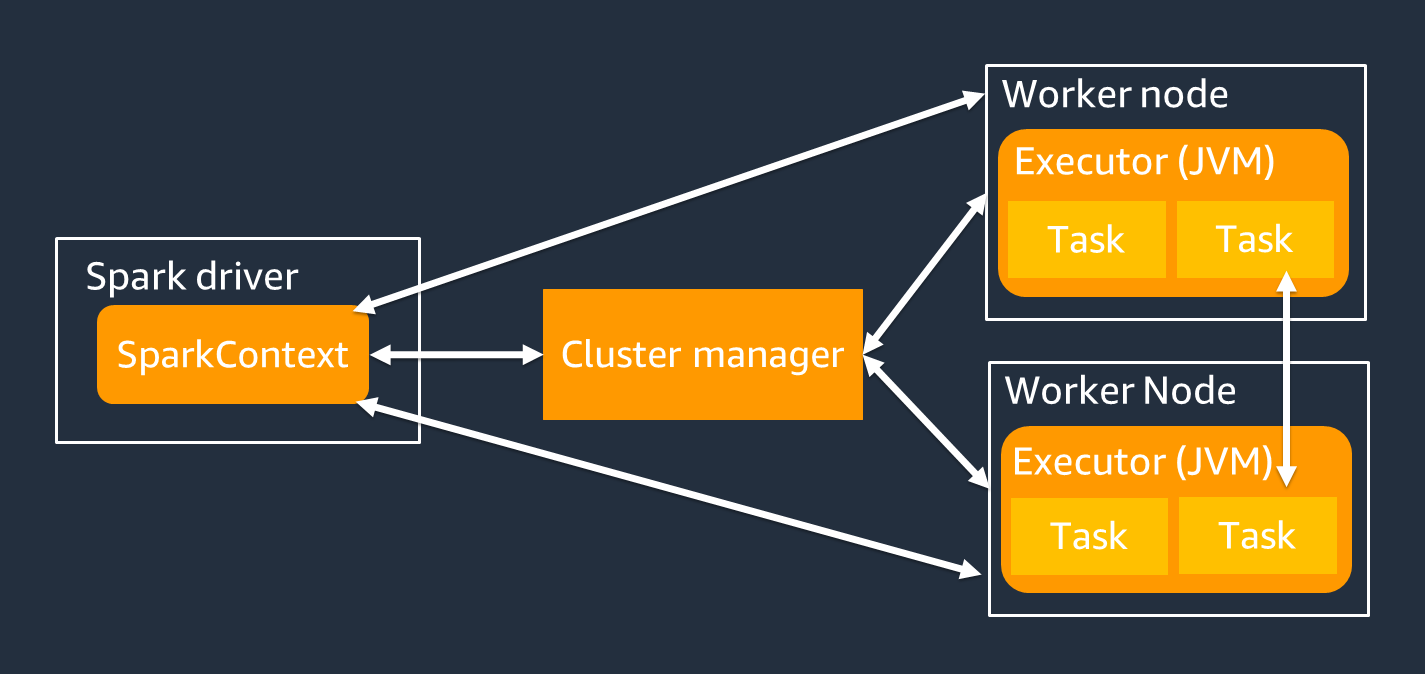
O driver do Spark é o principal responsável por dividir sua aplicação do Spark em tarefas que podem ser realizadas por operadores individuais. O driver do Spark tem as seguintes responsabilidades:
-
Executar
main()em seu código -
Gerar planos de execução
-
Provisionar executores do Spark em conjunto com o gerenciador de clusters, que gerencia os recursos no cluster
-
Agendar e solicitar tarefas para os executores do Spark
-
Gerenciar o progresso e a recuperação de tarefas
Você usa um objeto SparkContext para interagir com o driver do Spark na execução do seu trabalho.
Um executor do Spark é um operador para armazenar dados e executar tarefas que são passadas pelo driver do Spark. O número de executores do Spark aumentará e diminuirá com o tamanho do seu cluster.
nota
Um executor do Spark tem vários slots para que várias tarefas sejam processadas paralelamente. Por padrão, o Spark é compatível com uma tarefa para cada núcleo de CPU virtual (vCPU). Por exemplo, se um executor tiver quatro núcleos de CPU, ele poderá executar quatro tarefas simultâneas.
Conjunto de dados distribuído resiliente
O Spark realiza o trabalho complexo de armazenar e rastrear grandes conjuntos de dados nos executores do Spark. Ao escrever código para trabalhos do Spark, você não precisa pensar nos detalhes do armazenamento. O Spark fornece a abstração resiliente de conjunto de dados distribuído (RDD), que é uma coleção de elementos que podem ser operados paralelamente e particionados nos executores do Spark do cluster.
A figura a seguir mostra a diferença em como armazenar dados na memória quando um script Python é executado em seu ambiente típico e quando executado na estrutura Spark (). PySpark
![Python val [1,2,3 N], Apache Spark rdd = sc.parallelize[1,2,3 N].](images/store-data-memory.png)
-
Python: escrever
val = [1,2,3...N]em um script Python mantém os dados na memória na única máquina em que o código está sendo executado. -
PySpark— O Spark fornece a estrutura de dados RDD para carregar e processar dados distribuídos pela memória em vários executores do Spark. Você pode gerar um RDD com código como
rdd = sc.parallelize[1,2,3...N], e o Spark pode distribuir e armazenar dados automaticamente na memória em vários executores do Spark.Em muitos AWS Glue trabalhos, você usa RDDs por meio do AWS Glue DynamicFramesDataFramesSpark. Estas são as abstrações que permitem definir o esquema de dados em um RDD e realizar tarefas de alto nível com as informações adicionais. Como elas usam RDDs internamente, os dados são distribuídos de forma transparente e carregados em vários nós no seguinte código:
-
DynamicFrame
dyf= glueContext.create_dynamic_frame.from_options( 's3', {"paths": [ "s3://<YourBucket>/<Prefix>/"]}, format="parquet", transformation_ctx="dyf" ) -
DataFrame
df = spark.read.format("parquet") .load("s3://<YourBucket>/<Prefix>")
-
Um RDD tem os seguintes recursos:
-
Os RDDs consistem em dados divididos em várias partes chamadas partições. Cada executor do Spark armazena uma ou mais partições na memória, e os dados são distribuídos em vários executores.
-
Os RDDs são imutáveis, o que significa que não podem ser alterados após serem criados. Para alterar a DataFrame, você pode usar transformações, que são definidas na seção a seguir.
-
Os RDDs replicam dados nos nós disponíveis para que possam se recuperar automaticamente de falhas nos nós.
Avaliação lenta
Os RDDs são compatíveis com dois tipos de operações: transformações, que criam um novo conjunto de dados de um existente, e ações, que retornam um valor ao programa do driver após executar um cálculo no conjunto de dados.
-
Transformações: como os RDDs são imutáveis, você só pode alterá-los usando uma transformação.
Por exemplo,
mapé uma transformação que passa cada elemento do conjunto de dados por meio de uma função e retorna um novo RDD representando os resultados. Observe que o métodomapnão retorna uma saída. O Spark armazena a transformação abstrata para o futuro, em vez de permitir que você interaja com o resultado. O Spark não atuará nas transformações até que você chame uma ação. -
Ações: usando transformações, você cria seu plano lógico de transformação. Para iniciar o cálculo, você executa uma ação como
write,count,showoucollect.Todas as transformações no Spark são lentas, pois não computam seus resultados imediatamente. Em vez disso, o Spark se lembra de uma série de transformações aplicadas a alguns conjuntos de dados básicos, como objetos do Amazon Simple Storage Service (Amazon S3). As transformações são calculadas somente quando uma ação exige que um resultado seja retornado ao driver. Esse design permite que o Spark seja executado com mais eficiência. Por exemplo, considere a situação em que um conjunto de dados criado por meio da transformação
mapé consumido somente por uma transformação que reduz substancialmente o número de linhas, comoreduce. Você pode então passar o conjunto de dados menor que passou por ambas as transformações para o driver, em vez de passar o conjunto de dados mapeado maior.
Terminologia das aplicações do Spark
Esta seção aborda a terminologia das aplicações do Spark. O driver do Spark cria um plano de execução e controla o comportamento das aplicações em várias abstrações. Os termos a seguir são importantes para o desenvolvimento, a depuração e o ajuste de performance com a interface do usuário do Spark.
-
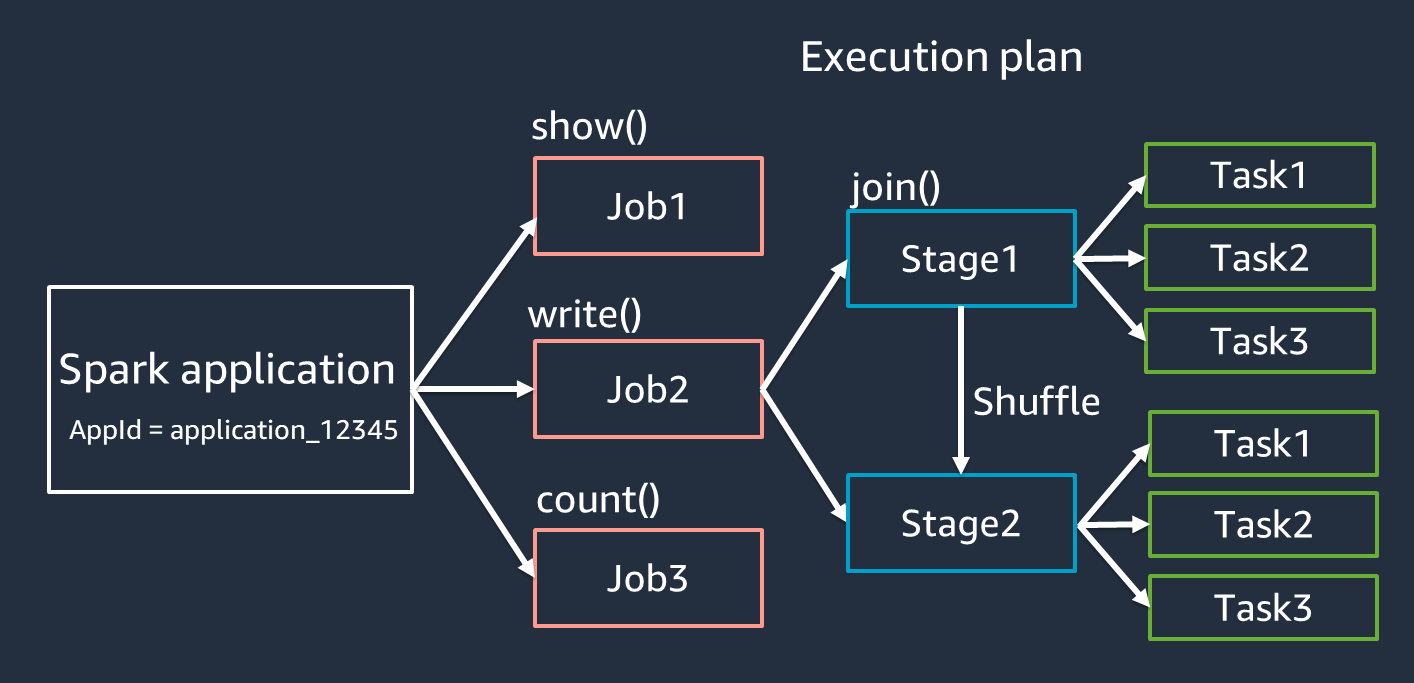
Aplicação: baseada em uma sessão do Spark (contexto do Spark). Identificada por um ID exclusivo, como
<application_XXX>. -
Trabalhos: baseados nas ações criadas para um RDD. Um trabalho consiste em uma ou mais etapas.
-
Etapas: baseadas nos shuffles criados para um RDD. Uma etapa consiste em uma ou mais tarefas. O shuffle é o mecanismo do Spark para redistribuir dados para que sejam agrupados de forma diferente nas partições do RDD. Certas transformações, como
join(), exigem um shuffle. As operações de shuffle são analisadas mais detalhadamente na prática de ajuste Otimizar as operações de shuffle. -
Tarefas: uma tarefa é a unidade mínima de processamento programada pelo Spark. As tarefas são criadas para cada partição do RDD, e o número de tarefas é o número máximo de execuções simultâneas na etapa.
nota
As tarefas são a coisa mais importante a se considerar ao otimizar o paralelismo. O número de tarefas aumenta com o número do RDD
Paralelismo
O Spark paraleliza tarefas para carregar e transformar dados.
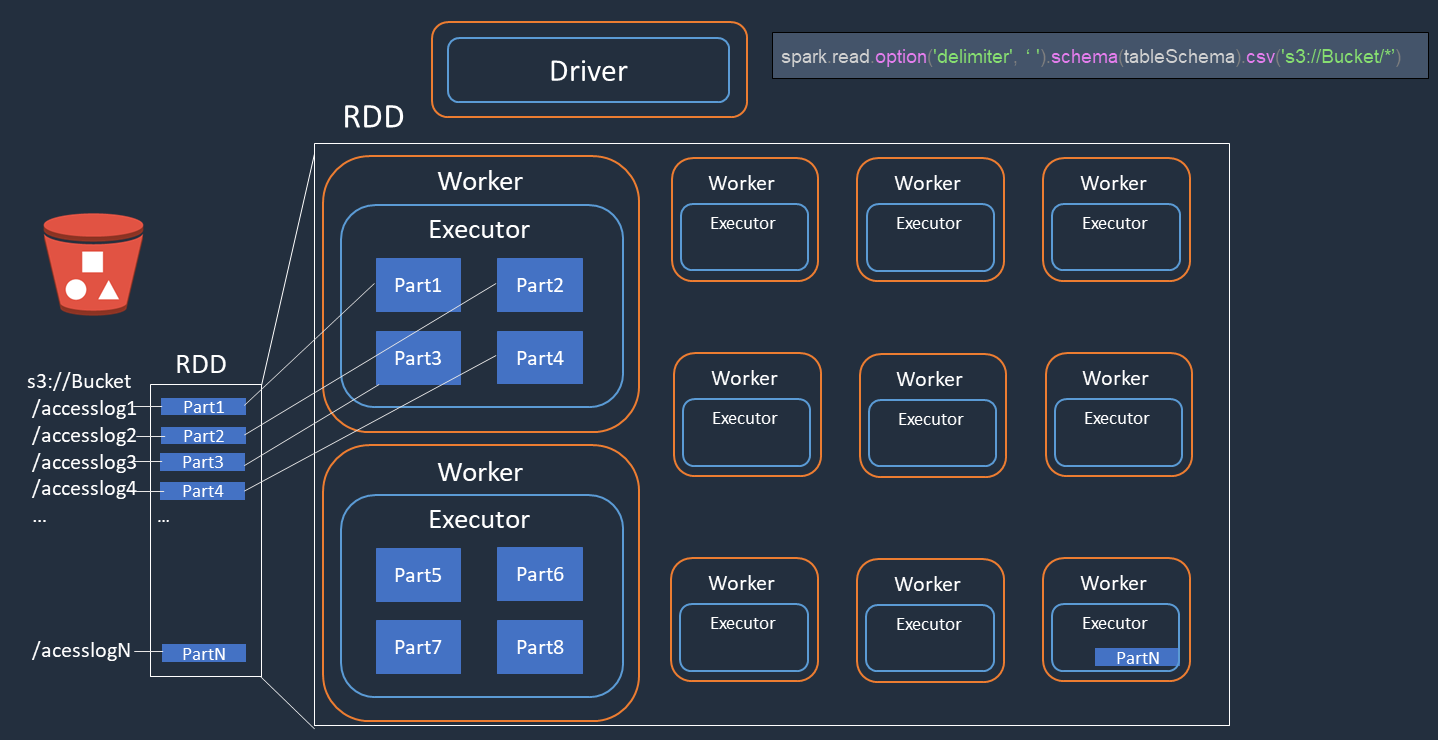
Considere um exemplo em que você executa o processamento distribuído de arquivos de logs de acesso (denominados accesslog1 ... accesslogN) no Amazon S3. O diagrama a seguir mostra o fluxo de processamento distribuído.
-
O driver do Spark cria um plano de execução para processamento distribuído nos vários executores do Spark.
-
O driver do Spark atribui tarefas a cada executor com base no plano de execução. Por padrão, o driver do Spark cria partições do RDD (cada uma correspondendo a uma tarefa do Spark) para cada objeto do S3 (
Part1 ... N). Em seguida, o driver do Spark atribui tarefas a cada executor. -
Cada tarefa do Spark baixa seu objeto do S3 atribuído e o armazena na memória na partição do RDD. Dessa forma, vários executores do Spark baixam e processam paralelamente a tarefa atribuída.
Para obter mais detalhes sobre o número inicial de partições e a otimização, consulte a seção Paralelizar tarefas.
Otimizador Catalyst
Internamente, o Spark usa um mecanismo chamado Otimizador Catalyst
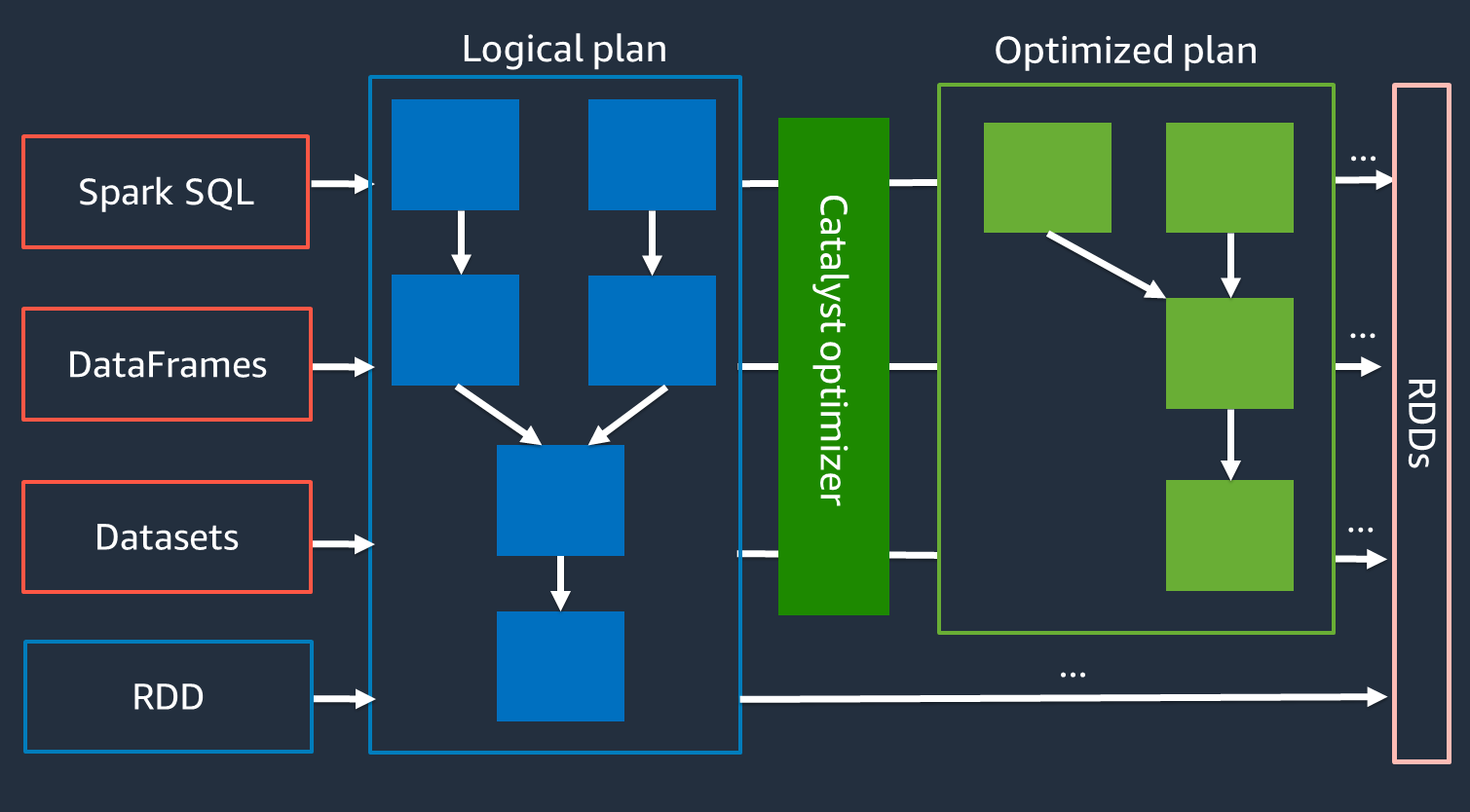
Como o otimizador Catalyst não funciona diretamente com a API RDD, as APIs de alto nível geralmente são mais rápidas do que a API RDD de baixo nível. Para junções complexas, o otimizador Catalyst pode melhorar significativamente a performance otimizando o plano de execução do trabalho. Você pode ver o plano otimizado do seu trabalho do Spark na guia SQL da interface do usuário do Spark.
Execução Adaptativa de Consultas
O otimizador Catalyst executa a otimização do runtime por meio de um processo chamado Execução Adaptativa de Consultas. A Execução Adaptativa de Consultas usa estatísticas de runtime para otimizar novamente o plano de execução das consultas enquanto seu trabalho está em execução. A Execução Adaptativa de Consultas oferece várias soluções para os desafios de performance, incluindo a aglutinação de partições pós-shuffle, a conversão da junção sort-merge em junção broadcast e a otimização da junção skew, conforme descrito nas seções a seguir.
A Execução Adaptativa de Consultas está disponível na AWS Glue versão 3.0 e posterior e está ativada por padrão na AWS Glue versão 4.0 (Spark 3.3.0) e versões posteriores. A Execução Adaptativa de Consultas pode ser ativada e desativada usando spark.conf.set("spark.sql.adaptive.enabled",
"true") em seu código.
Aglutinação de partições pós-shuffle
Esse recurso reduz as partições do RDD (aglutina) após cada shuffle com base nas estatísticas de saída de map. Isso simplifica o ajuste do número de partições de shuffle ao executar consultas. Você não precisa definir um número de partições de shuffle para o seu conjunto de dados. O Spark pode escolher o número adequado de partições de shuffle no runtime depois que você tiver uma quantidade inicial adequada de partições de shuffle.
A aglutinação de partições pós-shuffle é habilitada quando spark.sql.adaptive.enabled e spark.sql.adaptive.coalescePartitions.enabled estão definidas como true. Para obter mais informações, consulte a documentação do Apache Spark
Conversão da junção soft-merge em junção broadcast
Esse recurso reconhece quando você está juntando dois conjuntos de dados de tamanhos substancialmente diferentes e adota um algoritmo de junção mais eficiente com base nessas informações. Para obter mais detalhes, consulte a documentação do Apache Spark
Otimização de junções skew
A distorção de dados é um dos gargalos mais comuns dos trabalhos do Spark. É uma situação em que os dados são distorcidos para partições específicas do RDD (e, consequentemente, tarefas específicas), o que atrasa o tempo geral de processamento da aplicação. Isso geralmente pode ocasionar o downgrade da performance das operações de junção. O recurso de otimização de junções skew manipula dinamicamente a distorção nas junções sort-merge dividindo (e replicando, se necessário) tarefas distorcidas em tarefas de tamanho aproximadamente uniforme.
Esse recurso é habilitado quando spark.sql.adaptive.skewJoin.enabled está definido como true. Para obter mais detalhes, consulte a documentação do Apache Spark
