As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Visão geral da solução
Uma estrutura de ML escalável
Em uma empresa com milhões de clientes espalhados por várias linhas de negócios, os fluxos de trabalho de ML exigem a integração de dados pertencentes e gerenciados por equipes isoladas usando ferramentas diferentes para gerar valor comercial. Os bancos estão comprometidos com a proteção dos dados de seus clientes. Da mesma forma, a infraestrutura usada para o desenvolvimento de modelos de ML também está sujeita a altos padrões de segurança. Essa segurança adicional aumenta a complexidade e afeta o tempo de valorização dos novos modelos de ML. Em uma estrutura de ML escalável, é possível usar um conjunto de ferramentas modernizado e padronizado para reduzir o esforço necessário para combinar diferentes ferramentas e simplificar o processo do desenvolvimento à produção de novos modelos de ML.
Tradicionalmente, o gerenciamento e o suporte das atividades de ciência de dados no setor de serviços financeiros são controlados por uma equipe de plataforma central que reúne requisitos, provisiona recursos e mantém a infraestrutura para equipes de dados em toda a organização. Para escalar rapidamente o uso de ML em equipes federadas em toda a organização, é possível usar uma estrutura de ML escalável para fornecer recursos de autoatendimento para desenvolvedores de novos modelos e pipelines. Isso permite que esses desenvolvedores implantem uma infraestrutura moderna, pré-aprovada, padronizada e segura. Em última análise, esses recursos de autoatendimento reduzem a dependência da sua organização de equipes de plataformas centralizadas e aceleram a geração de valor para o desenvolvimento de modelos de ML.
A estrutura de ML escalável permite que os consumidores de dados (por exemplo, cientistas de dados ou engenheiros de ML) liberem valor comercial, o que oferece a eles a capacidade de fazer o seguinte:
Procurar e descobrir dados pré-aprovados que são necessários para o treinamento de modelos
Obter acesso a dados pré-aprovados de forma rápida e fácil
Usar dados pré-aprovados para provar a viabilidade do modelo
Lançar o modelo comprovado para produção para utilização por outras pessoas
O diagrama a seguir destaca o fluxo ponta a ponta da estrutura e a rota simplificada para os casos de uso de ML.
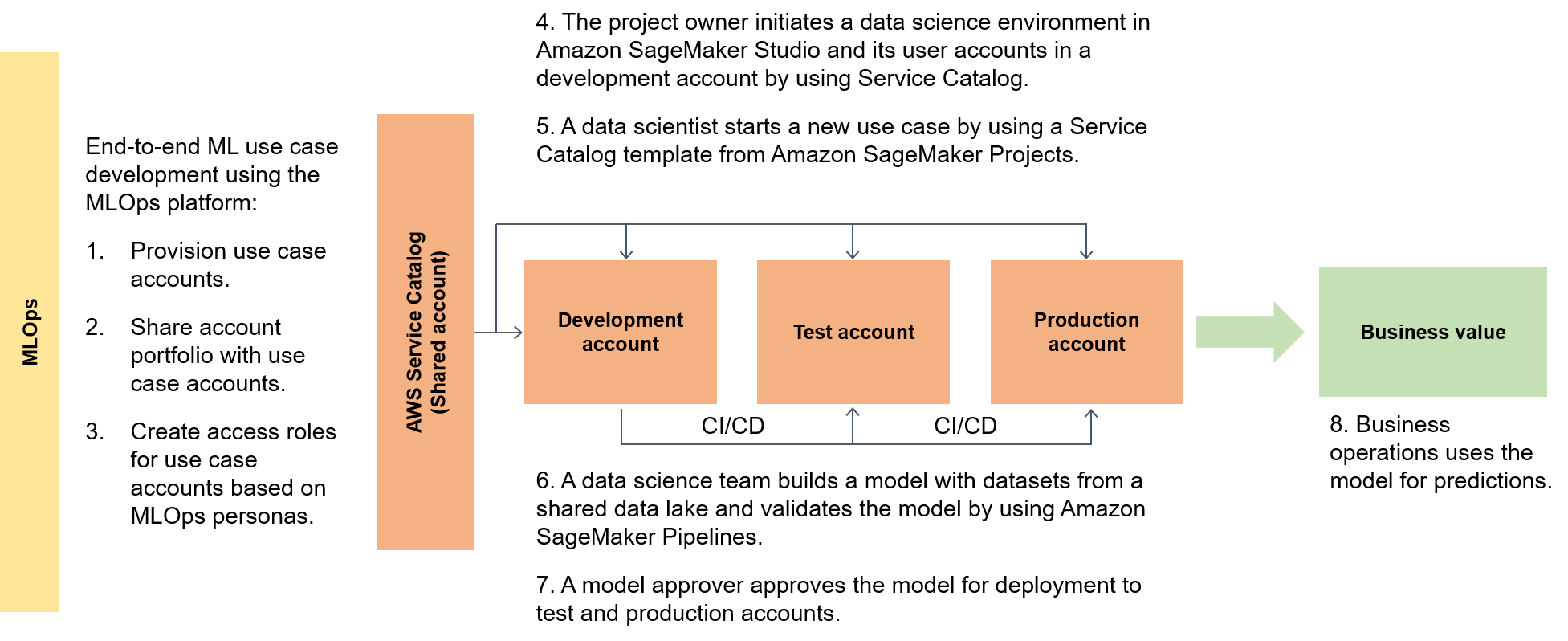
Em um contexto mais amplo, os consumidores de dados usam um acelerador com tecnologia sem servidor chamado data.all para obter dados em vários data lakes e, em seguida, usam os dados para treinar seus modelos, conforme ilustrado no diagrama a seguir.

Em um nível inferior, a estrutura escalável de ML contém o seguinte:
Self-service implantação de infraestrutura — reduza sua dependência de equipes centralizadas.
Sistema central de gerenciamento de pacotes Python: disponibilize pacotes Python pré-aprovados para desenvolvimento de modelos.
CI/CD pipelines para desenvolvimento e promoção de modelos — Reduza o tempo de vida incluindo integração contínua e pipelines contínuos (CI/CD) como parte de sua infraestrutura como modelos de código (IaC).
Capacidades de teste de modelos: aproveite as funcionalidades de teste de unidades, teste de modelos, teste de integração e teste ponta a ponta que estão disponíveis automaticamente para novos modelos.
Desacoplamento e orquestração de modelos — Evite computação desnecessária e torne suas implantações mais robustas desacoplando as etapas do modelo de acordo com os requisitos de recursos computacionais e orquestrando as diferentes etapas usando o Amazon AI Pipelines. SageMaker
Padronização de código — Melhore a qualidade do seu código usando a integração de CI/CD pipeline para validar os padrões do Python Enhancement Proposal
(PEP 8). Quick-start modelos genéricos de ML — Obtenha modelos do Service Catalog que instanciam seus ambientes de modelagem de ML (desenvolvimento, pré-produção e produção) e pipelines associados com o clique de um botão usando SageMaker projetos de IA para implantação.
Monitoramento da qualidade de dados e modelos — Certifique-se de que seus modelos atendam aos requisitos operacionais e dentro do seu nível de tolerância ao risco usando o Amazon SageMaker AI Model Monitor para monitorar automaticamente a variação na qualidade de seus dados e modelos.
Monitoramento de tendências: permita que os proprietários do seu modelo tomem decisões justas e equitativas verificando automaticamente os desequilíbrios de dados e se as mudanças no mundo introduziram algum viés em seu modelo.
Um hub central para metadados
Data.all
SageMaker validação
Para provar as capacidades da SageMaker IA em uma variedade de arquiteturas de processamento de dados e ML, a equipe que implementa os recursos seleciona, junto com a equipe de liderança bancária, casos de uso de complexidade variável de diferentes divisões de clientes bancários. Os dados do caso de uso são ofuscados e disponibilizados em um bucket de dados local do Amazon Simple Storage Service (Amazon S3) na conta
Quando a migração do modelo do ambiente de treinamento original para uma arquitetura de SageMaker IA estiver concluída, seu data lake hospedado na nuvem disponibilizará os dados para serem lidos pelos modelos de produção. As previsões geradas pelos modelos de produção são então gravadas de volta no data lake.
Depois que os casos de uso candidatos forem migrados, a estrutura escalável de ML usará uma linha de base inicial para as métricas de destino. É possível comparar a linha de base com os horários anteriores de provedores on-premises ou de outros provedores de nuvem como evidência das melhorias de tempo possibilitadas pela estrutura escalável de ML.
