As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Análise das compensações e dos riscos
As arquiteturas resilientes devem usar alguns mecanismos bem testados, simples e confiáveis para responder às falhas. Para alcançar os mais altos níveis de resiliência, as workloads devem detectar e se recuperar automaticamente do maior número possível de modos de falha. Fazer isso requer um grande investimento na realização de análises de resiliência. Isso significa que alcançar níveis mais altos de resiliência envolve fazer compensações. No entanto, à medida que você continua fazendo compensações, você atinge um ponto de retornos decrescentes em relação aos seus objetivos de resiliência. Confira as compensações mais comuns:
-
Custo: componentes redundantes, observabilidade aprimorada, ferramentas adicionais ou maior utilização de recursos resultarão em maiores custos.
-
Complexidade do sistema: detectar e responder aos modos de falha, incluindo as soluções de mitigação, e a possibilidade de não usar serviços gerenciados resultam em maior complexidade do sistema.
-
Esforço de engenharia: são necessárias horas adicionais da equipe de desenvolvimento para criar soluções que detectem e respondam aos modos de falha.
-
Sobrecarga operacional: monitorar e operar um sistema que lida com mais modos de falha pode aumentar a sobrecarga operacional, especialmente quando você não pode usar serviços gerenciados para mitigar modos de falha específicos.
-
Latência e consistência: a criação de sistemas distribuídos que favoreçam a disponibilidade exige compensações entre consistência e latência, conforme descrito no teorema PACELC
.
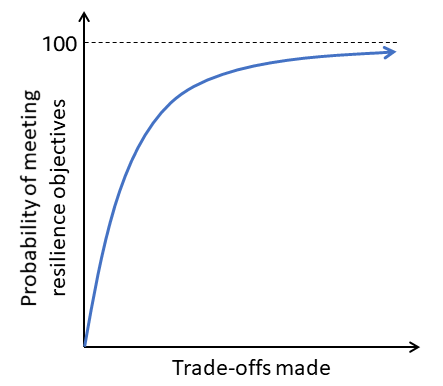
Ao considerar as mitigações para os modos de falha identificados na história do usuário, considere as compensações que você precisa fazer. Assim como acontece com a segurança, a resiliência é um problema de otimização. Você precisa decidir se deseja evitar, mitigar, transferir ou aceitar os riscos apresentados pela falha identificada. Alguns modos de falha podem ser evitados, enquanto outros podem ser aceitos e, alguns, transferidos. Você pode optar por mitigar muitos dos modos de falha identificados. Para determinar qual abordagem adotar, realize uma avaliação fazendo duas perguntas: qual é a probabilidade de que a falha ocorra? Qual será o impacto na workload se ela ocorrer?
A probabilidade define o quão provável é que um evento ocorra. Por exemplo, se a história do usuário tiver um componente que opera em uma única instância do Amazon Elastic Compute Cloud (Amazon EC2), o componente poderá ser interrompido em algum momento durante a operação do sistema, talvez devido a procedimentos de aplicação de patches ou a erros do sistema operacional. Como alternativa, um banco de dados gerenciado pelo Amazon Relational Database Service (Amazon RDS) que sincroniza dados entre suas instâncias primária e secundária tem baixa plausibilidade de ficar completamente indisponível.
O impacto é uma estimativa dos danos que um evento pode causar. Ele deve ser avaliado tanto do ponto de vista financeiro quanto da reputação, e é relativo ao valor das histórias de usuário que ele impacta. Por exemplo, um banco de dados sobrecarregado pode ter um impacto significativo na capacidade de um sistema de comércio eletrônico de aceitar novos pedidos. No entanto, a perda de uma única instância de uma frota de 20 instâncias sob o controle de um balanceador de carga provavelmente teria muito pouco impacto.
Você pode comparar as respostas a essas perguntas com o custo das compensações que você precisa fazer para mitigar o risco. Quando você considera essas informações tendo em vista seu limite de risco e seus objetivos de resiliência, elas fundamentam sua decisão sobre quais modos de falha você planeja mitigar ativamente.
