As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Visão geral da estrutura de trabalho do
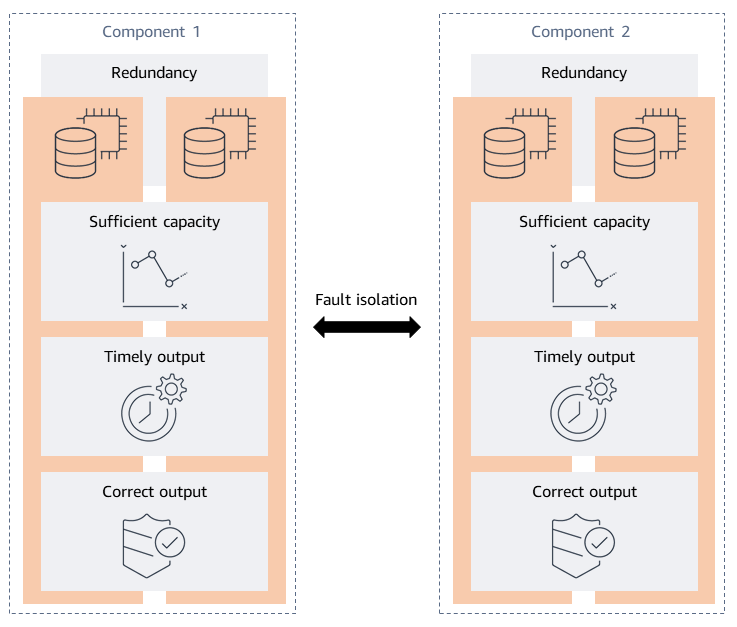
O framework de análise de resiliência foi desenvolvido identificando as propriedades de resiliência desejadas de uma workload. Propriedades desejadas são as condições que você espera que o sistema satisfaça. A resiliência é normalmente avaliada pela disponibilidade, portanto, cinco propriedades são as características de um sistema distribuído altamente disponível: redundância, capacidade suficiente, saída oportuna, saída correta e isolamento de falhas. Essas propriedades são mostradas no diagrama a seguir.
-
Redundância: a tolerância a falhas é obtida por meio de redundância que elimina pontos únicos de falha (SPOFs). A redundância pode abranger desde componentes sobressalentes em sua workload até réplicas completas de toda a pilha de aplicações. Ao considerar a redundância para suas aplicações, é importante levar em consideração o nível de redundância fornecido pela infraestrutura, pelos armazenamentos de dados e pelas dependências que você usa. Por exemplo, o Amazon DynamoDB e o Amazon Simple Storage Service (Amazon S3) fornecem redundância replicando dados em várias zonas de disponibilidade em uma AWS Lambda região e executam suas funções em vários nós de trabalho em várias zonas de disponibilidade. Para cada serviço que você usa, leve em consideração o que é fornecido pelo serviço e o que você precisa projetar.
-
Capacidade suficiente: sua workload requer recursos suficientes para funcionar conforme o esperado. Os recursos incluem memória, ciclos de CPU, threads, armazenamento, throughput, cotas de serviço e muitos outros.
-
Resultado oportuno: quando os clientes usam sua workload, eles esperam que ela desempenhe a função pretendida dentro de um período de tempo razoável. A menos que o serviço forneça um acordo de serviço (SLA) para latência, a expectativa deles geralmente se baseia em evidências empíricas, ou seja, em sua própria experiência. Essa experiência média do cliente geralmente é considerada a latência média (P50) em seu sistema. Se sua workload demorar mais do que o esperado, essa latência poderá afetar a experiência de seus clientes.
-
Saída correta: a saída correta do software da sua workload é necessária para que ela forneça a funcionalidade pretendida. Um resultado incorreto ou incompleto pode ser pior do que nenhuma resposta.
-
Isolamento de falhas: restringe o escopo do impacto a um contêiner de falhas pretendido quando ocorre uma falha. Ele garante que componentes específicos de sua workload falhem juntos, evitando que uma falha se espalhe em cascata para outros componentes não intencionais. Também ajuda a limitar o escopo do impacto da sua workload para os clientes. O isolamento de falhas é um pouco diferente das quatro propriedades anteriores, porque aceita que uma falha já ocorreu, mas deve ser contida. Você pode criar isolamento de falhas em sua infraestrutura, dependências e funções de software.
Quando uma propriedade desejada é violada, isso pode fazer com que uma workload fique indisponível, ou seja percebida com tal. Com base nessas propriedades de resiliência desejadas e em nossa experiência de trabalho com muitos clientes da AWS , identificamos cinco categorias comuns de falha: pontos únicos de falha, carga excessiva, latência excessiva, configurações incorretas e bugs e destino compartilhado, que abreviamos como SEEMS. Eles fornecem um método consistente para categorizar modos de falha em potencial, e eles estão descritos na tabela a seguir.
Categoria de falha |
Viola |
Definição |
|---|---|---|
Pontos únicos de falha (SPOFs) |
Redundância |
Uma falha em um único componente interrompe o sistema devido à falta de redundância do componente. |
Carga excessiva |
Capacidade suficiente |
Over-consumption de um recurso por meio de demanda ou tráfego excessivo impede que o recurso execute sua função esperada. Isso pode incluir atingir limites e cotas, o que causa limitação e rejeição de solicitações. |
Latência excessiva |
Saída oportuna |
A latência do processamento do sistema ou do tráfego de rede excede o tempo esperado, os objetivos de serviço (SLOs) ou os acordos de serviço (SLAs). |
Configuração incorreta e bugs |
Saída correta |
Bugs do software ou configuração incorreta do sistema levam a uma saída incorreta. |
Destino compartilhado |
Isolamento de falhas |
Uma falha causada por qualquer uma das categorias de falhas anteriores ultrapassa as delimitações de isolamento contra falhas pretendidas e causa um efeito cascata em outras partes do sistema ou outros clientes. |
