As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Componentes da arquitetura de um data warehouse do Amazon Redshift
É recomendável ter uma compreensão básica dos principais componentes da arquitetura em um data warehouse do Amazon Redshift. Esse conhecimento pode ajudar você a entender melhor como criar suas consultas e tabelas para obter uma performance ideal.
Um data warehouse no Amazon Redshift consiste nos seguintes componentes principais de arquitetura:
-
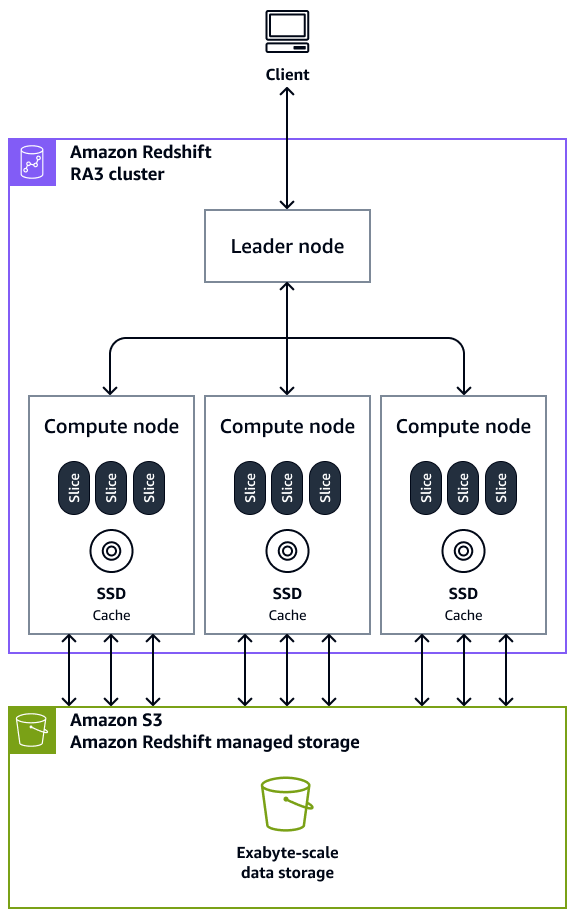
Clusters: um cluster, composto por um ou mais nós de computação, é o principal componente da infraestrutura de um data warehouse do Amazon Redshift. Os nós de computação são transparentes para aplicações externas, mas sua aplicação cliente interage diretamente somente com o nó líder. Um cluster típico tem dois ou mais nós de computação. Os nós de computação são coordenados por meio do nó líder.
-
Nó líder: um nó líder gerencia as comunicações dos programas clientes e de todos os nós de computação. Um nó líder também prepara os planos para executar uma consulta sempre que uma consulta for enviada a um cluster. Quando os planos estiverem prontos, o nó líder compila o código, distribui o código compilado para os nós de computação e, então, atribui fatias de dados a cada nó de computação para processar os resultados da consulta.
-
Nó de computação: um nó de computação executa uma consulta. O nó líder compila o código de elementos individuais do plano para executar a consulta e o atribui aos nós de computação individuais. Os nós de computação executam o código compilado e reenviam os resultados intermediários ao nó líder para agregação final. Cada nó de computação possui sua própria CPU, memória e armazenamento em disco anexado dedicados. À medida que o workload cresce, você pode aumentar a capacidade computacional e a capacidade de armazenamento de um cluster aumentando o número de nós, atualizando o tipo de nó ou ambos.
-
Fatia do nó: um nó de computação é dividido em unidades chamadas fatias. Cada fatia em um nó de computação recebe uma parte da memória do nó e do espaço em disco em que processa uma parte da workload atribuída ao nó. Assim, as fatias funcionam em paralelo para completar a operação. Os dados são distribuídos entre fatias com base no estilo de distribuição e na chave de distribuição de uma tabela específica. Uma distribuição uniforme dos dados possibilita que o Amazon Redshift atribua uniformemente workloads às fatias e maximize as vantagens do processamento paralelo. O número de fatias por nó de computação é decidido com base no tipo de nó. Para obter mais informações sobre isso, consulte Clusters e nós no Amazon Redshift na documentação do Amazon Redshift.
-
Processamento paralelo massivo (MPP): o Amazon Redshift usa a arquitetura MPP para processar dados rapidamente, até mesmo consultas complexas e grandes quantidades de dados. Vários nós de computação executam o mesmo código de consulta em partes dos dados para maximizar o processamento paralelo.
-
Aplicação cliente: o Amazon Redshift se integra a diversas ferramentas de carregamento de dados, extração, transformação e carregamento (ETL), business intelligence (BI), relatórios, mineração de dados e analytics. Todas as aplicações cliente se comunicam com o cluster somente por meio do nó líder.
O diagrama a seguir mostra como os componentes de arquitetura de um data warehouse do Amazon Redshift trabalham juntos para acelerar as consultas.
Há sete etapas do ciclo de vida de uma consulta:
-
Recebimento e análise de consultas:
-
O nó líder recebe a consulta e analisa o SQL.
-
O analisador produz uma árvore de consulta inicial, que representa a estrutura lógica da consulta original.
-
O Amazon Redshift insere essa árvore de consulta no otimizador de consultas.
-
-
Otimização de consultas:
-
O otimizador avalia a consulta e, se necessário, a reescreve para maximizar sua eficiência.
-
Esse processo de otimização pode envolver a criação de várias consultas relacionadas para substituir uma única consulta.
-
-
Geração de plano de consulta:
-
O otimizador gera um plano de consulta (ou vários planos, se necessário) para execução.
-
O plano de consulta especifica as opções de execução, como tipos de junção, ordem de junção, métodos de agregação e os requisitos de distribuição de dados.
-
-
Conversão do mecanismo de execução:
-
O mecanismo de execução converte o plano de consulta em etapas, segmentos e fluxos bem definidos:
-
Etapa: representa uma operação individual necessária durante a execução da consulta. As etapas podem ser combinadas para permitir que os nós de computação executem operações de consultas, junções ou outras operações de banco de dados.
-
Segmento: combina várias etapas que um único processo pode executar. É a menor unidade de compilação executável por uma fatia de nó de computação. (Uma fatia é a unidade de processamento paralelo no Amazon Redshift.)
-
Fluxo: uma coleção de segmentos distribuídos em fatias de nós de computação disponíveis.
-
-
O mecanismo de execução gera o código compilado com base nessas etapas, segmentos e fluxos. O código compilado é executado mais rapidamente que o código interpretado e consome menos capacidade computacional.
-
O nó líder transmite o código compilado para os nós de computação.
-
-
Execução paralela:
-
Esta etapa ocorre uma vez para cada fluxo.
-
As fatias do nó de computação executam os segmentos de consulta em paralelo.
-
Durante esse processo, o Amazon Redshift otimiza a comunicação de rede, o uso de memória e o gerenciamento de disco para passar resultados intermediários de uma etapa do plano de consulta para a próxima.
-
Essa otimização contribui para uma execução mais rápida da consulta.
-
-
Processamento de fluxo:
-
Esta etapa ocorre uma vez para cada fluxo.
-
O mecanismo cria segmentos executáveis para cada fluxo, para um processamento paralelo eficiente.
-
-
Classificação final e agregação:
-
O nó líder aborda qualquer classificação ou agregação final exigida pela consulta.
-
Uma vez concluída, o nó líder retorna os resultados para o cliente.
-
Para obter informações sobre os componentes de arquitetura, consulte Arquitetura de sistema do data warehouse na documentação do Amazon Redshift.
