As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Otimize o desempenho do seu aplicativo modernizado AWS Blu Age
Vishal Jaswani, Manish Roy e Himanshu Sah, Amazon Web Services
Resumo
Os aplicativos de mainframe que são modernizados com o AWS Blu Age exigem testes de equivalência funcional e de desempenho antes de serem implantados na produção. Nos testes de performance, as aplicações modernizadas podem funcionar mais lentamente do que os sistemas legados, especialmente em trabalhos em lotes complexos. Essa disparidade existe porque as aplicações de mainframe são monolíticas, enquanto as aplicações modernas usam arquiteturas de várias camadas. Esse padrão apresenta técnicas de otimização para resolver essas lacunas de desempenho em aplicativos que são modernizados usando a refatoração automatizada com o Blu Age. AWS
O padrão usa a estrutura de modernização AWS Blu Age com recursos nativos de Java e ajuste de banco de dados para identificar e resolver gargalos de desempenho. O padrão descreve como você pode usar a criação de perfil e o monitoramento para identificar problemas de desempenho com métricas como tempos de execução de SQL, utilização de memória e I/O padrões. Em seguida, explica como você pode aplicar otimizações direcionadas, incluindo reestruturação de consultas de banco de dados, armazenamento em cache e refinamento da lógica de negócios.
As melhorias nos tempos de processamento em lote e na utilização dos recursos do sistema ajudam você a igualar os níveis de performance do mainframe em seus sistemas modernizados. Essa abordagem mantém a equivalência funcional durante a transição para arquiteturas modernas baseadas em nuvem.
Para usar este padrão, configure seu sistema e identifique hotspots de performance seguindo as instruções na seção Épicos e aplique as técnicas de otimização abordadas em detalhes na seção Arquitetura.
Pré-requisitos e limitações
Pré-requisitos
Um aplicativo modernizado da AWS Blu Age
Privilégios administrativos para instalar o cliente do banco de dados e as ferramentas de criação de perfil
AWS Certificação Blu Age Level 3
Compreensão de nível intermediário da estrutura AWS Blu Age, estrutura de código gerada e programação Java
Limitações
As seguintes capacidades e recursos de otimização estão fora do escopo desse padrão:
Otimização da latência de rede entre os níveis de aplicações
Otimizações em nível de infraestrutura por meio de tipos de instância do Amazon Elastic Compute Cloud (Amazon) e otimização de armazenamento EC2
Teste simultâneo de carga de usuário e teste de estresse
Versões do produto
JProfiler versão 13.0 ou posterior (recomendamos a versão mais recente)
pgAdmin versão 8.14 ou posterior
Arquitetura
Esse padrão configura um ambiente de criação de perfil para um aplicativo AWS Blu Age usando ferramentas como o JProfiler pGADmin. Ele suporta otimização por meio do DAOManager and SQLExecution Builder APIs fornecido pela AWS Blu Age.
O restante desta seção fornece informações detalhadas e exemplos para identificar hotspots de performance e estratégias de otimização para suas aplicações modernizadas. As etapas na seção Épicos remetem a essas informações para obter mais orientações.
Identificação de hotspots de performance em aplicações de mainframe modernizadas
Em aplicações de mainframe modernizadas, os hotspots de performance são áreas específicas no código que causam lentidão ou ineficiências significativas. Esses hotspots geralmente são causados pelas diferenças arquitetônicas entre o mainframe e as aplicações modernizadas. Para identificar esses gargalos de desempenho e otimizar o desempenho do seu aplicativo modernizado, você pode usar três técnicas: registro em log de SQL, um EXPLAIN plano de consulta e análise. JProfiler
Técnica de identificação de hotspots: registro em log em SQL
Os aplicativos Java modernos, incluindo aqueles que foram modernizados com o uso do AWS Blu Age, têm recursos integrados para registrar consultas SQL. Você pode habilitar registradores específicos em projetos do AWS Blu Age para rastrear e analisar as instruções SQL executadas pelo seu aplicativo. Essa técnica é particularmente útil para identificar padrões ineficientes de acesso ao banco de dados, como consultas individuais excessivas ou chamadas de banco de dados mal estruturadas, que podem ser otimizados por meio de lotes ou refinamento de consultas.
Para implementar o registro de SQL em seu aplicativo modernizado AWS Blu Age, defina o nível de registro DEBUG para instruções SQL no application.properties arquivo para capturar detalhes da execução da consulta:
level.org.springframework.beans.factory.support.DefaultListableBeanFactory : WARN level.com.netfective.bluage.gapwalk.runtime.sort.internal: WARN level.org.springframework.jdbc.core.StatementCreatorUtils: DEBUG level.com.netfective.bluage.gapwalk.rt.blu4iv.dao: DEBUG level.com.fiserv.signature: DEBUG level.com.netfective.bluage.gapwalk.database.support.central: DEBUG level.com.netfective.bluage.gapwalk.rt.db.configuration.DatabaseConfiguration: DEBUG level.com.netfective.bluage.gapwalk.rt.db.DatabaseInteractionLoggerUtils: DEBUG level.com.netfective.bluage.gapwalk.database.support.AbstractDatabaseSupport: DEBUG level.com.netfective.bluage.gapwalk.rt: DEBUG
Monitore consultas de alta frequência e de baixa performance usando os dados registrados para identificar alvos de otimização. Concentre-se nas consultas em processos em lote, pois elas geralmente têm o maior impacto na performance.
Técnica de identificação de hotspots: plano de consulta EXPLAIN
Esse método usa os recursos de planejamento de consultas dos sistemas de gerenciamento de banco de dados relacional. Você pode usar comandos como EXPLAIN no PostgreSQL ou no MySQL, ou EXPLAIN PLAN no Oracle, para examinar como seu banco de dados pretende executar uma determinada consulta. A saída desses comandos fornece informações valiosas sobre a estratégia de execução da consulta, incluindo se os índices serão usados ou se as varreduras completas da tabela serão realizadas. Essas informações são essenciais para otimizar a performance da consulta, especialmente nos casos em que a indexação adequada pode reduzir significativamente o tempo de execução.
Extraia as consultas SQL mais repetitivas dos registros da aplicação e analise o caminho de execução das consultas de baixa performance usando o comando EXPLAIN específico do seu banco de dados. Veja a seguir um exemplo para um banco de dados PostgreSQL.
Consulta:
SELECT * FROM tenk1 WHERE unique1 < 100;
Comando da EXPLAIN:
EXPLAIN SELECT * FROM tenk1 where unique1 < 100;
Saída:
Bitmap Heap Scan on tenk1 (cost=5.06..224.98 rows=100 width=244) Recheck Cond: (unique1 < 100) -> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=100 width=0) Index Cond: (unique1 < 100)
A saída EXPLAIN pode ser interpretada da seguinte forma:
Leia o plano
EXPLAINdas operações mais internas às mais externas (de baixo para cima).Procure os termos-chave. Por exemplo,
Seq Scanindica a varredura completa da tabela eIndex Scanmostra o uso do índice.Verifique os valores de custo: o primeiro número é o custo inicial e o segundo número é o custo total.
Veja o valor
rowsdo número estimado de linhas de saída.
Neste exemplo, o mecanismo de consulta usa uma varredura de índice para encontrar as linhas correspondentes e, em seguida, busca somente essas linhas (Bitmap Heap Scan). Isso é mais eficiente do que escanear a tabela inteira, apesar do custo mais alto do acesso individual às linhas.
As operações de varredura de tabela na saída de um plano EXPLAIN indicam um índice ausente. A otimização requer a criação de um índice apropriado.
Técnica de identificação de pontos de acesso: análise JProfiler
JProfiler é uma ferramenta abrangente de criação de perfil Java que ajuda você a resolver gargalos de desempenho identificando chamadas lentas de banco de dados e chamadas com uso intenso de CPU. Essa ferramenta é particularmente eficaz na identificação de consultas SQL lentas e no uso ineficiente da memória.
Exemplo de análise para consulta:
select evt. com.netfective.bluage.gapwalk.rt.blu4iv.dao.Blu4ivTableManager.queryNonTrasactional
A visualização JProfiler Hot Spots fornece as seguintes informações:
Coluna Tempo
Mostra a duração total da execução (por exemplo, 329 segundos)
Exibe a porcentagem do tempo total de aplicação (por exemplo, 58,7%)
Ajuda a identificar as operações mais demoradas
Coluna Tempo médio
Mostra a duração por execução (por exemplo, 2.692 microssegundos)
Indica a performance individual da operação
Ajuda a identificar operações individuais lentas
Coluna Eventos
Mostra a contagem de execuções (por exemplo, 122.387 vezes)
Indica frequência de operação
Ajuda a identificar métodos chamados com frequência
Para os resultados do exemplo:
Alta frequência: 122.387 execuções indicam potencial de otimização
Preocupação com a performance: 2.692 microssegundos por tempo médio sugerem ineficiência
Impacto crítico: 58,7% do tempo total indica um grande gargalo
JProfiler pode analisar o comportamento do tempo de execução do seu aplicativo para revelar pontos de acesso que podem não ser aparentes por meio da análise estática de código ou do registro em SQL. Essas métricas ajudam você a identificar as operações que precisam de otimização e determinar a estratégia de otimização que seria mais eficaz. Para obter mais informações sobre JProfiler recursos, consulte a JProfiler documentação
Ao usar essas três técnicas (registro de SQL, EXPLAIN plano de consulta e JProfiler) em combinação, você pode obter uma visão holística das características de desempenho do seu aplicativo. Ao identificar e abordar os hotspots mais críticos de performance, você pode preencher a lacuna de performance entre sua aplicação de mainframe original e seu sistema modernizado baseado em nuvem.
Depois de identificar os hotspots de performance da sua aplicação, você pode aplicar estratégias de otimização, que são explicadas na próxima seção.
Estratégias de otimização para modernização do mainframe
Esta seção descreve as principais estratégias para otimizar aplicações que foram modernizadas por meio de sistemas de mainframe. Ele se concentra em três estratégias: usar as existentes APIs, implementar um cache eficaz e otimizar a lógica de negócios.
Estratégia de otimização: usando a existente APIs
AWS O Blu Age fornece várias interfaces DAO poderosas APIs que você pode usar para otimizar o desempenho. Duas interfaces principais — DAOManager e o SQLExecution Builder — oferecem recursos para aprimorar o desempenho do aplicativo.
DAOManager
DAOManager serve como interface principal para operações de banco de dados em aplicativos modernizados. Ela oferece vários métodos para aprimorar as operações no banco de dados e melhorar a performance da aplicação, principalmente para operações simples de criação, leitura, atualização e exclusão (CRUD) e processamento em lote.
Use SetMaxResults. Na DAOManager API, você pode usar o SetMaxResultsmétodo para especificar o número máximo de registros a serem recuperados em uma única operação de banco de dados. Por padrão, DAOManager recupera somente 10 registros por vez, o que pode levar a várias chamadas de banco de dados ao processar grandes conjuntos de dados. Use essa otimização quanda sua aplicação precisar processar um grande número de registros e estiver fazendo várias chamadas ao banco de dados para recuperá-los. Isso é particularmente útil em cenários de processamento em lote em que você está iterando em um grande conjunto de dados. No exemplo a seguir, o código à esquerda (antes da otimização) usa o valor padrão de recuperação de dados de dez registros. O código à direita (após a otimização) é configurado setMaxResultspara recuperar 100.000 registros por vez.

nota
Escolha lotes maiores com cuidado e verifique o tamanho do objeto, pois essa otimização aumenta o espaço ocupado pela memória.
SetOnGreatorOrEqual Substitua por SetOnEqual. Essa otimização envolve a alteração do método usado para definir a condição de recuperação de registros. O SetOnGreatorOrEqualmétodo recupera registros maiores ou iguais a um valor especificado, enquanto SetOnEqualrecupera somente registros que correspondam exatamente ao valor especificado.
Use SetOnEqualconforme ilustrado no exemplo de código a seguir, quando você sabe que precisa de correspondências exatas e atualmente está usando o SetOnGreatorOrEqualmétodo seguido por readNextEqual(). Essa otimização reduz a recuperação desnecessária de dados.

Use operações de gravação e atualização em lote. Você pode usar operações em lote para agrupar várias operações de gravação ou atualização em uma única transação de banco de dados. Isso reduz o número de chamadas ao banco de dados e pode melhorar significativamente a performance de operações que envolvem vários registros.
No exemplo a seguir, o código à esquerda executa operações de gravação em um loop, o que diminui a performance da aplicação. Você pode otimizar esse código usando uma operação de gravação em lote: durante cada iteração do loop
WHILE, você adiciona registros a um lote até que o tamanho do lote atinja um tamanho predeterminado de cem. Em seguida, você pode liberar o lote quando ele atingir o tamanho do lote predeterminado e, em seguida, liberar todos os registros restantes para o banco de dados. Isso é particularmente útil em cenários em que você processa grandes conjuntos de dados que exigem atualizações.
Adicione índices. Adicionar índices é uma otimização em nível de banco de dados que pode melhorar significativamente a performance da consulta. Um índice permite que o banco de dados localize rapidamente linhas com um valor de coluna específico sem escanear a tabela inteira. Use a indexação em colunas que são frequentemente usadas em cláusulas
WHERE, condiçõesJOINou declaraçõesORDER BY. Isso é particularmente importante para tabelas grandes ou quando a recuperação rápida de dados é crucial.
SQLExecutionConstrutor
SQLExecutionO Builder é uma API flexível que você pode usar para controlar as consultas SQL que serão executadas, buscar somente determinadas colunas, usando e INSERT usando nomes SELECT de tabelas dinâmicas. No exemplo a seguir, o SQLExecutor Builder usa uma consulta personalizada que você define.

Escolhendo entre um DAOManager e o SQLExecution Builder
A escolha entre elas APIs depende do seu caso de uso específico:
Use DAOManager quando quiser que o AWS Blu Age Runtime gere as consultas SQL em vez de escrevê-las você mesmo.
Escolha o SQLExecution Builder quando precisar escrever consultas SQL para aproveitar os recursos específicos do banco de dados ou escrever consultas SQL ideais.
Estratégia de otimização: armazenamento em cache
Em aplicações modernizadas, a implementação de estratégias eficazes de armazenamento em cache pode reduzir significativamente as chamadas ao banco de dados e melhorar os tempos de resposta. Isso ajuda a preencher a lacuna de performance entre os ambientes de mainframe e nuvem.
Em aplicativos AWS Blu Age, implementações simples de cache usam estruturas de dados internas, como mapas de hash ou listas de matrizes, para que você não precise configurar uma solução de cache externa que exija custo e reestruturação de código. Essa abordagem é particularmente eficaz para dados que são acessados com frequência, mas alterados com pouca frequência. Ao implementar o armazenamento em cache, considere as restrições de memória e os padrões de atualização para garantir que os dados em cache permaneçam consistentes e forneçam benefícios reais de performance.
A chave para o sucesso do armazenamento em cache é identificar os dados certos para armazenar em cache. No exemplo a seguir, o código à esquerda sempre lê os dados da tabela, enquanto o código à direita lê os dados da tabela quando o mapa de hash local não tem um valor para uma determinada chave. cacheMap é um objeto de mapa de hash criado no contexto do programa e limpo no método de limpeza do contexto do programa.
Armazenamento em cache com DAOManager:
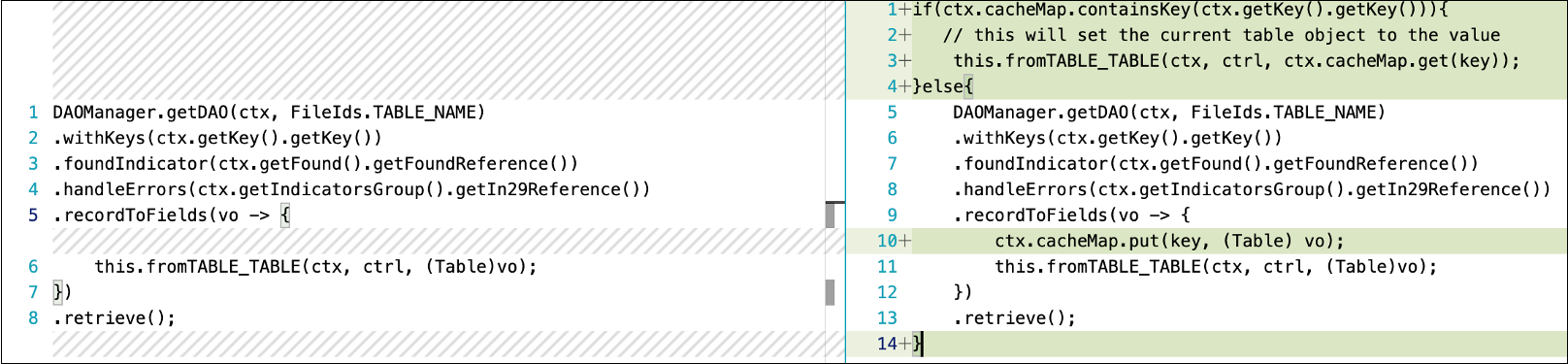
Armazenamento em cache com o SQLExecution Builder:

Estratégia de otimização: otimização da lógica de negócios
A otimização da lógica de negócios se concentra na reestruturação do código gerado automaticamente pelo AWS Blu Age para melhor se alinhar aos recursos da arquitetura moderna. Isso se torna necessário quando o código gerado mantém a mesma estrutura lógica do código antigo do mainframe, o que pode não ser ideal para sistemas modernos. O objetivo é melhorar a performance e, ao mesmo tempo, manter a equivalência funcional com a aplicação original.
Essa abordagem de otimização vai além de simples ajustes de API e estratégias de armazenamento em cache. Ela envolve mudanças na forma como a aplicação processa os dados e interage com o banco de dados. As otimizações comuns incluem evitar operações de leitura desnecessárias para atualizações simples, remover chamadas redundantes ao banco de dados e reestruturar os padrões de acesso aos dados para melhor se alinharem à arquitetura moderna de aplicações. Veja a seguir alguns exemplos:
Atualizar dados diretamente no banco de dados. Reestruture sua lógica de negócios usando atualizações diretas de SQL em vez de várias DAOManager operações com loops. Por exemplo, o código a seguir (lado esquerdo) faz várias chamadas ao banco de dados e usa memória excessiva. Especificamente, ele usa várias operações de leitura e gravação de banco de dados em loops, atualizações individuais em vez de processamento em lote e criação desnecessária de objetos para cada iteração.
O código otimizado a seguir (lado direito) usa uma única operação de atualização do Direct SQL. Especificamente, ele usa uma única chamada de banco de dados em vez de várias chamadas e não exige loops porque todas as atualizações são tratadas em uma única instrução. Essa otimização proporciona melhor performance e utilização de recursos, além de reduzir a complexidade. Ele evita a injeção de SQL, fornece melhor armazenamento em cache do plano de consulta e ajuda a melhorar a segurança.

nota
Sempre use consultas parametrizadas para evitar a injeção de SQL e garantir o gerenciamento adequado das transações.
Reduzir as chamadas redundantes do banco de dados. Chamadas redundantes de banco de dados podem afetar significativamente a performance da aplicação, principalmente quando ocorrem dentro de loops. Uma técnica de otimização simples, mas eficaz, é evitar repetir a mesma consulta ao banco de dados várias vezes. A comparação de código a seguir demonstra como mover a chamada
retrieve()do banco de dados para fora do loop evita a execução redundante de consultas idênticas, o que melhora a eficiência.
Reduzir as chamadas do banco de dados usando a cláusula
JOINem SQL. Implemente o SQLExecution Builder para minimizar as chamadas para o banco de dados. SQLExecutionO Builder fornece mais controle sobre a geração de SQL e é particularmente útil para consultas complexas que DAOManager não podem ser processadas com eficiência. Por exemplo, o código a seguir usa várias DAOManager chamadas:List<Employee> employees = daoManager.readAll(); for(Employee emp : employees) { Department dept = deptManager.readById(emp.getDeptId()); // Additional call for each employee Project proj = projManager.readById(emp.getProjId()); // Another call for each employee processEmployeeData(emp, dept, proj); }O código otimizado usa uma única chamada de banco de dados no SQLExecution Builder:
SQLExecutionBuilder builder = new SQLExecutionBuilder(); builder.append("SELECT e.*, d.name as dept_name, p.name as proj_name"); builder.append("FROM employee e"); builder.append("JOIN department d ON e.dept_id = d.id"); builder.append("JOIN project p ON e.proj_id = p.id"); builder.append("WHERE e.status = ?", "ACTIVE"); List<Map<String, Object>> results = builder.execute(); // Single database call for(Map<String, Object> result : results) { processComplexData(result); }
Usar estratégias de otimização em conjunto
Essas três estratégias funcionam sinergicamente: APIs fornecem as ferramentas para acesso eficiente aos dados, o armazenamento em cache reduz a necessidade de recuperação repetida de dados e a otimização da lógica de negócios garante que elas APIs sejam usadas da maneira mais eficaz possível. O monitoramento e o ajuste regulares dessas otimizações garantem melhorias contínuas na performance, mantendo a confiabilidade e a funcionalidade da aplicação modernizada. A chave para o sucesso está em entender quando e como aplicar cada estratégia com base nas características e nas metas de performance da sua aplicação.
Ferramentas
JProfiler
é uma ferramenta de criação de perfil Java projetada para desenvolvedores e engenheiros de desempenho. Ele analisa aplicativos Java e ajuda a identificar gargalos de desempenho, vazamentos de memória e problemas de segmentação. JProfiler oferece perfis de CPU, memória e thread, bem como monitoramento de banco de dados e máquina virtual Java (JVM) para fornecer informações sobre o comportamento do aplicativo. nota
Como alternativa JProfiler, você pode usar o Java VisualVM
. Essa é uma ferramenta gratuita de criação de perfil e monitoramento de performance de código aberto para aplicações Java que oferece monitoramento em tempo real do uso da CPU, consumo de memória, gerenciamento de threads e estatísticas de coleta de resíduos. Como o Java VisualVM é uma ferramenta JDK integrada, ele é mais econômico do que para as necessidades básicas de criação de perfil. JProfiler O pgAdmin
é uma ferramenta de gerenciamento e desenvolvimento de código aberto para o PostgreSQL. Ele fornece uma interface gráfica que ajuda você a criar, manter e usar objetos de banco de dados. Você pode usar o pgAdmin para realizar uma ampla variedade de tarefas, desde escrever consultas SQL simples até desenvolver bancos de dados complexos. Seus recursos incluem uma sintaxe destacando o editor SQL, um editor de código do lado do servidor, um agente de agendamento para tarefas SQL, shell e em lote e suporte para todos os recursos do PostgreSQL para usuários novatos e experientes do PostgreSQL.
Práticas recomendadas
Identificação de hotspots de performance:
Documente as métricas básicas de performance antes de iniciar as otimizações.
Estabeleça metas claras de melhoria de performance com base nos requisitos de negócios.
Ao fazer o benchmarking, desative o registro em log detalhado, pois isso pode afetar a performance.
Configure uma suíte de testes de performance e execute-a periodicamente.
Use a versão mais recente do pgAdmin. (As versões mais antigas não oferecem suporte ao plano de consulta
EXPLAIN.)Para fins de benchmarking, desconecte JProfiler após a conclusão das otimizações, pois isso aumenta a latência.
Para fins de benchmarking, certifique-se de executar o servidor no modo de inicialização em vez do modo de depuração, pois o modo de depuração aumenta a latência.
Estratégias de otimização:
Configure SetMaxResultsvalores no
application.yamlarquivo para especificar lotes do tamanho certo de acordo com as especificações do sistema.Configure SetMaxResultsvalores com base no volume de dados e nas restrições de memória.
SetOnGreatorOrEqualMude para SetOnEqualsomente quando ocorrerem chamadas subsequentes
.readNextEqual().Nas operações de gravação ou atualização em lote, processe o último lote separadamente, pois ele pode ser menor que o tamanho do lote configurado e pode ser perdido pela operação de gravação ou atualização.
Armazenamento em cache:
Os campos que são introduzidos para armazenamento em cache em
processImpl, que mudam a cada execução, devem sempre ser definidos no contexto deprocessImpl. Os campos também devem ser limpos usando o métododoReset()oucleanUp().Ao implementar o armazenamento em cache em memória, dimensione o cache corretamente. Caches muito grandes armazenados na memória podem consumir todos os recursos, o que pode afetar a performance geral da sua aplicação.
SQLExecutionConstrutor:
Para consultas que você planeja usar no SQLExecution Builder, use nomes de chave como
PROGRAMNAME_STATEMENTNUMBER.Ao usar o SQLExecution Builder, sempre verifique o
Sqlcodcampo. Esse campo contém um valor que especifica se a consulta foi executada corretamente ou se encontrou algum erro.Use consultas parametrizadas para evitar a injeção de SQL.
Otimização da lógica de negócios:
Mantenha a equivalência funcional ao reestruturar o código e execute testes de regressão e comparação de bancos de dados para o subconjunto relevante de programas.
Mantenha snapshots de criação de perfil para comparação.
Épicos
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Instale e configure JProfiler. |
| Desenvolvedor de aplicativos |
Instale e configure o pGadmin. | Nesta etapa, você instala e configura um cliente de banco de dados para consultar seu banco de dados. Este padrão usa um banco de dados PostgreSQL e o pgAdmin como cliente de banco de dados. Se você estiver usando outro mecanismo de banco de dados, siga a documentação do cliente de banco de dados correspondente.
| Desenvolvedor de aplicativos |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Ative o registro de consultas SQL em seu aplicativo AWS Blu Age. | Ative os registradores para o registro de consultas SQL no | Desenvolvedor de aplicativos |
Gere e analise planos de consulta | Para obter detalhes, consulte a seção Arquitetura. | Desenvolvedor de aplicativos |
Crie um JProfiler instantâneo para analisar um caso de teste de baixo desempenho. |
| Desenvolvedor de aplicativos |
Analise o JProfiler instantâneo para identificar gargalos de desempenho. | Siga estas etapas para analisar o JProfiler instantâneo.
Para obter mais informações sobre o uso JProfiler, consulte a seção Arquitetura e a JProfiler documentação | Desenvolvedor de aplicativos |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Estabeleça uma linha de base de performance antes de implementar as otimizações. |
| Desenvolvedor de aplicativos |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Otimize as chamadas de leitura. | Otimize a recuperação de dados usando o DAOManager SetMaxResultsmétodo. Para obter mais informações sobre essa abordagem, consulte a seção Arquitetura. | Desenvolvedor de aplicativos, DAOManager |
Refatore a lógica de negócios para evitar várias chamadas para o banco de dados. | Reduza as chamadas ao banco de dados usando uma cláusula | Desenvolvedor de aplicativos, SQLExecution Construtor |
Refatore o código para usar o armazenamento em cache para reduzir a latência das chamadas de leitura. | Para obter informações sobre essa técnica, consulte Armazenamento em cache na seção Arquitetura. | Desenvolvedor de aplicativos |
Reescreva um código ineficiente que usa várias DAOManager operações para operações simples de atualização. | Para obter mais informações sobre a atualização de dados diretamente no banco de dados, consulte Otimização da lógica de negócios na seção Arquitetura. | Desenvolvedor de aplicativos |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Valide cada alteração de otimização de forma iterativa, mantendo a equivalência funcional. |
notaO uso de métricas básicas como referência garante uma medição precisa do impacto de cada otimização, mantendo a confiabilidade do sistema. | Desenvolvedor de aplicativos |
Solução de problemas
| Problema | Solução |
|---|---|
Ao executar a aplicação moderna, você vê uma exceção com o erro | Para resolver esse problema:
|
Você adicionou índices, mas nenhuma melhoria na performance. | Siga estas etapas para garantir que o mecanismo de consulta esteja usando o índice:
|
Você encontra uma out-of-memory exceção. | Verifique se o código libera a memória mantida pela estrutura de dados. |
As operações de gravação em lote resultam na falta de registros na tabela | Revise o código para garantir que uma operação de gravação adicional seja executada quando a contagem de lotes não for zero. |
O log do SQL não aparece nos logs da aplicação. |
|
Recursos relacionados
Refatorando aplicativos automaticamente com o AWS Blu Age (Guia do usuário)AWS Mainframe Modernization
