As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Gere insights de z/OS dados do Db2 usando AWS Mainframe Modernization e Amazon Q em Quick Sight
Shubham Roy, Roshna Razack e Santosh Kumar Singh, Amazon Web Services
Resumo
Observação: o AWS Mainframe Modernization serviço (experiência do Managed Runtime Environment) não está mais aberto a novos clientes. Para recursos semelhantes ao AWS Mainframe Modernization Service (experiência Managed Runtime Environment), explore AWS Mainframe Modernization Service (Self-Managed Experience). Os clientes atuais podem continuar usando o serviço normalmente. Para obter mais informações, consulte Mudança de disponibilidade do AWS Mainframe Modernization.
Se sua organização está hospedando dados essenciais para os negócios em um ambiente de mainframe IBM Db2, obter insights desses dados é crucial para impulsionar o crescimento e a inovação. Ao desbloquear dados do mainframe, você pode criar inteligência de negócios de maneira mais rápida, segura e escalável para acelerar a tomada de decisões, o crescimento e a inovação orientados por dados na nuvem da Amazon Web Services (AWS).
Esse padrão apresenta uma solução para gerar insights de negócios e criar narrativas compartilháveis a partir de dados de mainframe no IBM Db2 for tables. z/OS As alterações nos dados do mainframe são transmitidas para o tópico do Amazon Managed Streaming for Apache Kafka (Amazon MSK) usando a replicação de dados do AWS Mainframe Modernization com o Precisely. Usando a ingestão de streaming do Amazon Redshift, os dados de tópicos do Amazon MSK são armazenados em data warehouses do Amazon Redshift sem servidor para analytics no Amazon QuickSight.
Depois que os dados estiverem disponíveis no QuickSight, você poderá usar prompts em linguagem natural com o Amazon Q no QuickSight para criar resumos dos dados, fazer perguntas e gerar narrativas analíticas. Você não precisa escrever consultas SQL ou aprender uma ferramenta de business intelligence (BI).
Contexto de negócios
Este padrão apresenta uma solução para casos de uso de data analytics de mainframe e insights de dados. Usando o padrão, você cria um painel de elementos visuais para os dados da sua empresa. Para demonstrar a solução, este padrão usa uma empresa da área da saúde que fornece planos médicos, odontológicos e oftalmológicos para seus membros nos EUA. Neste exemplo, as informações demográficas e do plano dos membros são armazenadas no IBM Db2 para tabelas de z/OS dados. O painel visual mostra o seguinte:
Distribuição de membros por região
Distribuição de membros por gênero
Distribuição de membros por idade
Distribuição de membros por tipo de plano
Membros que não concluíram a imunização preventiva
Para exemplos de distribuição de membros por região e membros que não concluíram a imunização preventiva, consulte a seção Informações adicionais.
Depois de criar o painel, você gera uma narrativa analítica que explica os insights da análise anterior. A narrativa analítica fornece recomendações para aumentar o número de membros que concluíram as imunizações preventivas.
Pré-requisitos e limitações
Pré-requisitos
Um ativo Conta da AWS. Essa solução foi criada e testada no Amazon Linux 2 no Amazon Elastic Compute Cloud (Amazon EC2).
Uma nuvem privada virtual (VPC) com uma sub-rede que pode ser acessada pelo sistema de mainframe.
Um banco de dados de mainframe com dados de negócios. Para ver os dados de exemplo usados para criar e testar essa solução, consulte a seção Anexos.
Captura de dados de alteração (CDC) ativada nas tabelas do Db2 z/OS . Para habilitar o CDC no Db2 z/OS, consulte a documentação da IBM
. Conecte o CDC com precisão para z/OS instalação no z/OS sistema que hospeda os bancos de dados de origem. O CDC Preciously Connect para z/OS imagem é fornecido como um arquivo zip dentro do AWS Mainframe Modernization - Data Replication for IBM z/OS Amazon
Machine Image (AMI). Para instalar o Preciously Connect CDC z/OS no mainframe, consulte a documentação de instalação do Precisely Connect.
Limitações
Os dados do seu mainframe Db2 devem estar em um tipo de dados compatível com o Precisely Connect CDC. Para obter uma lista dos tipos de dados compatíveis, consulte a documentação do Precisely Connect CDC
. Seus dados no Amazon MSK devem estar em um tipo de dados compatível com o Amazon Redshift. Para obter uma lista dos tipos de dados compatíveis, consulte a documentação do Amazon Redshift.
O Amazon Redshift tem comportamentos e limites de tamanho diferentes para diferentes tipos de dados. Para obter mais informações, consulte a documentação do Amazon Redshift.
Os dados quase em tempo real no QuickSight dependem do intervalo de atualização definido para o banco de dados do Amazon Redshift.
Alguns Serviços da AWS não estão disponíveis em todos Regiões da AWS. Para conferir a disponibilidade de uma região, consulte Serviços da AWS by Region
. No momento, o Amazon Q no QuickSight não está disponível em todas as regiões que oferecem suporte ao QuickSight. Para endpoints específicos, consulte a página Cotas e endpoints de serviços e clique no link correspondente ao serviço desejado.
Versões do produto
AWS Mainframe Modernization Replicação de dados com a versão 4.1.44 do Precision
Python versão 3.6 ou posterior
Apache Kafka versão 3.5.1
Arquitetura
Arquitetura de destino
O diagrama a seguir mostra uma arquitetura para gerar insights de negócios com base em dados de mainframe usando o AWS Mainframe Modernization replicação de dados com o Precisely
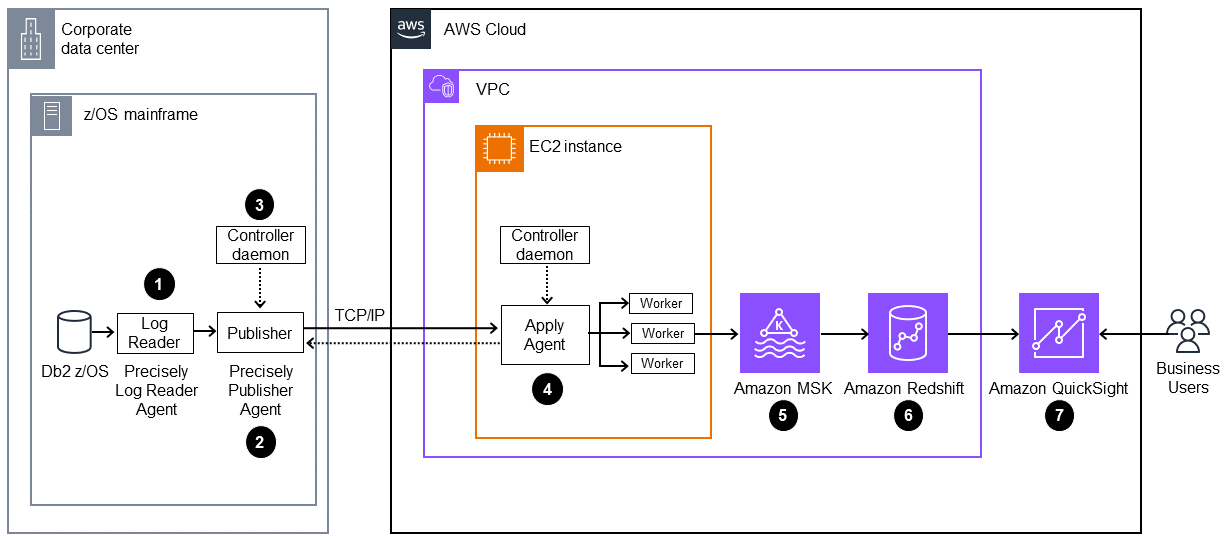
O diagrama mostra o seguinte fluxo de trabalho:
O Precisely Log Reader Agent lê dados dos registros do Db2 e grava os dados em um armazenamento temporário em um sistema de arquivos OMVS no mainframe.
O Publisher Agent lê os logs brutos do Db2 do armazenamento temporário.
O daemon do controlador on-premises autentica, autoriza, monitora e gerencia as operações.
O Apply Agent é implantado no Amazon EC2 usando a AMI pré-configurada. Ele se conecta ao Publisher Agent por meio do daemon do controlador usando. TCP/IP O Apply Agent envia dados para o Amazon MSK usando vários trabalhadores para obter alto throughput.
Os trabalhadores gravam os dados no tópico do Amazon MSK no formato JSON. Como destino intermediário para as mensagens replicadas, o Amazon MSK fornece recursos de failover automatizados e altamente disponíveis.
O recurso de ingestão de streaming do Amazon Redshift fornece ingestão de dados com baixa latência e alta velocidade do Amazon MSK para um banco de dados do Amazon Redshift sem servidor. Um procedimento armazenado no Amazon Redshift executa a reconciliação (insert/update/exclusões) dos dados de alteração do mainframe nas tabelas do Amazon Redshift. Essas tabelas do Amazon Redshift servem como fonte de data analytics para o QuickSight.
Os usuários acessam os dados no QuickSight para obter analytics e insights. Você pode usar o Amazon Q no QuickSight para interagir com os dados usando prompts em linguagem natural.
Ferramentas
Serviços da AWS
O Amazon Elastic Compute Cloud (Amazon EC2) oferece capacidade de computação escalável na Nuvem AWS. Você poderá iniciar quantos servidores virtuais precisar e escalá-los na vertical ou na horizontal.
AWS Key Management Service (AWS KMS) ajuda você a criar e controlar chaves criptográficas para ajudar a proteger seus dados.
O Amazon Managed Streaming for Apache Kafka (Amazon MSK) é um serviço totalmente gerenciado que ajuda você a criar e executar aplicações que usam o Apache Kafka para processar dados em streaming.
O Amazon QuickSight é um serviço de business intelligence (BI) em escala de nuvem que ajuda você a visualizar, analisar e relatar dados em um único painel. Este padrão usa os recursos generativos de BI do Amazon Q no QuickSight.
O Amazon Redshift sem servidor
é uma opção com tecnologia sem servidor do Amazon Redshift que torna mais eficiente executar e escalar analytics em segundos, sem a necessidade de configurar e gerenciar a infraestrutura de data warehouse. O AWS Secrets Manager ajuda a substituir credenciais codificadas, incluindo senhas, por uma chamada de API ao Secrets Manager para recuperar o segredo por programação.
Outras ferramentas
O Precisely Connect CDC
coleta e integra dados de sistemas legados em plataformas de dados e na nuvem.
Repositório de código
O código desse padrão está disponível no GitHub Mainframe_DataInsights_change_data_reconciliation
Práticas recomendadas
Siga as práticas recomendadas ao configurar seu cluster do Amazon MSK.
Siga as práticas recomendadas de análise de dados do Amazon Redshift para melhorar a performance.
Ao criar as funções AWS Identity and Access Management (IAM) para a configuração do Preciously, siga o princípio do privilégio mínimo e conceda as permissões mínimas necessárias para realizar uma tarefa. Para obter mais informações, consulte Concessão de privilégio mínimo e Práticas recomendadas de segurança na documentação do IAM.
Épicos
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure um grupo de segurança. | Para se conectar ao daemon do controlador e ao cluster do Amazon MSK, crie um grupo de segurança para a instância do EC2. Adicione as seguintes regras de entrada e saída:
Anote o nome do grupo de segurança. Você precisará referenciar o nome ao iniciar a instância do EC2 e configurar o cluster do Amazon MSK. | DevOps engenheiro, AWS DevOps |
Crie uma política do IAM e um perfil do IAM. |
| DevOps engenheiro, administrador de sistemas da AWS |
Provisione uma instância do EC2. | Para provisionar uma instância do EC2 a fim de executar o Precisely CDC e conectar-se ao Amazon MSK, faça o seguinte:
| Administrador e DevOps engenheiro da AWS |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Crie o cluster do Amazon MSK. | Para criar um cluster do Amazon MSK, faça o seguinte:
Um cluster provisionado típico pode demorar até 15 minutos para ser criado. Depois que o cluster for criado, seu status mudará de Criando para Ativo. | AWS DevOps, administrador de nuvem |
Configure a SASL/SCRAM autenticação. | Para configurar a SASL/SCRAM autenticação para um cluster Amazon MSK, faça o seguinte:
| Arquiteto de nuvem |
Crie o tópico do Amazon MSK. | Para criar o tópico do Amazon MSK, faça o seguinte:
| Administrador de nuvem |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure os scripts do Precisely para replicar as alterações nos dados. | Para configurar os scripts do Precisely Connect CDC para replicar dados alterados do mainframe para o tópico do Amazon MSK, faça o seguinte:
Para obter exemplos de arquivos .ddl, consulte a seção Informações adicionais. | Desenvolvedor de aplicativos, arquiteto de nuvem |
Gere a chave de ACL da rede. | Para gerar a chave da lista de controle de acesso à rede (ACL da rede), faça o seguinte:
| Arquiteto de nuvem, AWS DevOps |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure os padrões na tela do ISPF. | Para definir as configurações padrão no Interactive System Productivity Facility (ISPF), siga as instruções na documentação do Precisely | Administrador de sistema de mainframe |
Configure o daemon do controlador. | Para configurar o daemon do controlador, faça o seguinte:
| Administrador de sistema de mainframe |
Configure o publicador. | Para configurar o publicador, faça o seguinte:
| Administrador de sistema de mainframe |
Atualize o arquivo de configuração do daemon. | Para atualizar os detalhes do publicador no arquivo de configuração do daemon do controlador, faça o seguinte:
| Administrador de sistema de mainframe |
Crie o trabalho para iniciar o daemon do controlador. | Para criar o trabalho, faça o seguinte:
| Administrador de sistema de mainframe |
Gere o arquivo JCL do publicador de captura. | Para gerar o arquivo JCL do publicador de captura, faça o seguinte:
| Administrador de sistema de mainframe |
Verifique e atualize o CDC. |
| Administrador de sistema de mainframe |
Envie os arquivos JCL. | Envie os seguintes arquivos JCL que você configurou nas etapas anteriores:
Depois de enviar os arquivos JCL, você pode iniciar o Apply Engine no Precisely na instância do EC2. | Administrador de sistema de mainframe |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Inicie o Apply Engine e valide o CDC. | Para iniciar o Apply Engine na instância do EC2 e validar o CDC, faça o seguinte:
| Arquiteto de nuvem, desenvolvedor de aplicativos |
Valide os registros no tópico do Amazon MSK. | Para ler a mensagem do tópico do Kafka, faça o seguinte:
| Desenvolvedor de aplicativos, arquiteto de nuvem |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure o Amazon Redshift sem servidor. | Para criar um data warehouse do Amazon Redshift sem servidor, siga as instruções na documentação da AWS. No painel do Amazon Redshift sem servidor, verifique se o namespace e o grupo de trabalho foram criados e estão disponíveis. Para esse exemplo de padrão, o processo pode levar de dois a cinco minutos. | Engenheiro de dados |
Configure o perfil do IAM e a política de confiança necessárias para a ingestão de streaming. | Para configurar a ingestão de streaming Amazon Redshift sem servidor pelo Amazon MSK, faça o seguinte:
| Engenheiro de dados |
Conecte o Amazon Redshift sem servidor ao Amazon MSK. | Para conectar ao tópico do Amazon MSK, crie um esquema externo no Amazon Redshift sem servidor. No Editor de Consultas V2 do Amazon Redshift, execute o seguinte comando SQL, substituindo
| Engenheiro de migração |
Crie uma visão materializada. | Para consumir os dados do tópico do Amazon MSK no Amazon Redshift sem servidor, crie uma visão materializada. No Editor de Consultas V2 do Amazon Redshift, execute os comandos SQL a seguir, substituindo
| Engenheiro de migração |
Crie tabelas de destino no Amazon Redshift. | As tabelas do Amazon Redshift fornecem a entrada para o QuickSight. Este padrão usa as tabelas Para criar as duas tabelas no Amazon Redshift, execute os seguintes comandos SQL no Editor de Consultas V2 do Amazon Redshift:
| Engenheiro de migração |
Crie um procedimento armazenado no Amazon Redshift. | Este padrão usa um procedimento armazenado para sincronizar dados de alteração ( Para criar o procedimento armazenado no Amazon Redshift, use o editor de consultas v2 para executar o código do procedimento armazenado que está no repositório. GitHub | Engenheiro de migração |
Leia por meio da visão materializada de streaming e carregue nas tabelas de destino. | O procedimento armazenado lê as alterações de dados da visão materializada de streaming e carrega as alterações de dados nas tabelas de destino. Para executar o procedimento armazenado, use o seguinte comando:
Você pode usar EventBridge a Amazon Outra opção é usar o Editor de Consultas V2 do Amazon Redshift para programar a atualização. Para obter mais informações, consulte Consultas programadas com o Editor de Consultas v2. | Engenheiro de migração |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure o QuickSight. | Para configurar o QuickSight, siga as instruções na documentação da AWS. | Engenheiro de migração |
Configure uma conexão segura entre o QuickSight e o Amazon Redshift. | Para configurar uma conexão segura entre o QuickSight e o Amazon Redshift, faça o seguinte
| Engenheiro de migração |
Crie um conjunto de dados para o QuickSight. | Para criar um conjunto de dados para o QuickSight do Amazon Redshift, faça o seguinte:
| Engenheiro de migração |
Junte os conjuntos de dados. | Para criar analytics no QuickSight, junte as duas tabelas seguindo as instruções na documentação da AWS. No painel Configuração de junção, escolha Esquerda para Tipo de junção. Em Juntar cláusulas, use | Engenheiro de migração |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure o Amazon Q no QuickSight. | Para configurar o recurso de BI generativo do Amazon Q no QuickSight, siga as instruções na documentação da AWS. | Engenheiro de migração |
Analise os dados do mainframe e crie um painel visual. | Para analisar e visualizar seus dados no QuickSight, faça o seguinte:
Quando terminar, você poderá publicar seu painel para compartilhar com outras pessoas em sua organização. Para ver exemplos, consulte Painel visual do mainframe na seção Informações adicionais. | Engenheiro de migração |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Crie uma narrativa analítica. | Crie uma narrativa analítica para explicar os insights da análise anterior e gere uma recomendação para aumentar a imunização preventiva dos membros:
| Engenheiro de migração |
Veja a narrativa analítica gerada. | Para ver a narrativa analítica gerada, escolha essa narrativa na página Narrativas analíticas. | Engenheiro de migração |
Edite uma narrativa analítica gerada. | Para alterar a formatação, o layout ou os elementos visuais em uma narrativa analítica, siga as instruções na documentação da AWS. | Engenheiro de migração |
Compartilhe uma narrativa analítica. | Para compartilhar uma narrativa analítica, siga as instruções na documentação da AWS. | Engenheiro de migração |
Solução de problemas
| Problema | Solução |
|---|---|
Para a criação do conjunto de dados do QuickSight para o Amazon Redshift, |
|
A tentativa de iniciar o Apply Engine na instância do EC2 retorna o seguinte erro:
| Exporte o caminho de instalação
|
A tentativa de iniciar o Apply Engine retorna um dos seguintes erros de conexão:
| Verifique o spool do mainframe para garantir que os trabalhos do daemon do controlador estejam em execução. |
Recursos relacionados
Gere insights usando o AWS Mainframe Modernization Amazon Q no Quick Sight (padrão)
Gere insights de dados usando o AWS Mainframe Modernization Amazon Q no Quick Sight
(demonstração) AWS Mainframe Modernization - Replicação de dados para IBM z/OS
Ingestão de streaming do Amazon Redshift para uma visão materializada
Mais informações
Exemplos de arquivos .ddl
members_details.ddl
CREATE TABLE MEMBER_DTLS ( memberid INTEGER NOT NULL, member_name VARCHAR(50), member_type VARCHAR(20), age INTEGER, gender CHAR(1), email VARCHAR(100), region VARCHAR(20) );
member_plans.ddl
CREATE TABLE MEMBER_PLANS ( memberid INTEGER NOT NULL, medical_plan CHAR(1), dental_plan CHAR(1), vision_plan CHAR(1), preventive_immunization VARCHAR(20) );
Exemplo de arquivo .sqd
Substitua <kafka topic name> pelo nome do tópico do Amazon MSK.
script.sqd
-- Name: DB2ZTOMSK: DB2z To MSK JOBNAME DB2ZTOMSK;REPORT EVERY 1;OPTIONS CDCOP('I','U','D');-- Source Descriptions JOBNAME DB2ZTOMSK; REPORT EVERY 1; OPTIONS CDCOP('I','U','D'); -- Source Descriptions BEGIN GROUP DB2_SOURCE; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_details.ddl AS MEMBER_DTLS; DESCRIPTION DB2SQL /var/precisely/di/sqdata/apply/DB2ZTOMSK/ddl/mem_plans.ddl AS MEMBER_PLANS; END GROUP; -- Source Datastore DATASTORE cdc://<zos_host_name>/DB2ZTOMSK/DB2ZTOMSK OF UTSCDC AS CDCIN DESCRIBED BY GROUP DB2_SOURCE ; -- Target Datastore(s) DATASTORE 'kafka:///<kafka topic name>/key' OF JSON AS TARGET DESCRIBED BY GROUP DB2_SOURCE; PROCESS INTO TARGET SELECT { REPLICATE(TARGET) } FROM CDCIN;
Painel visual do mainframe
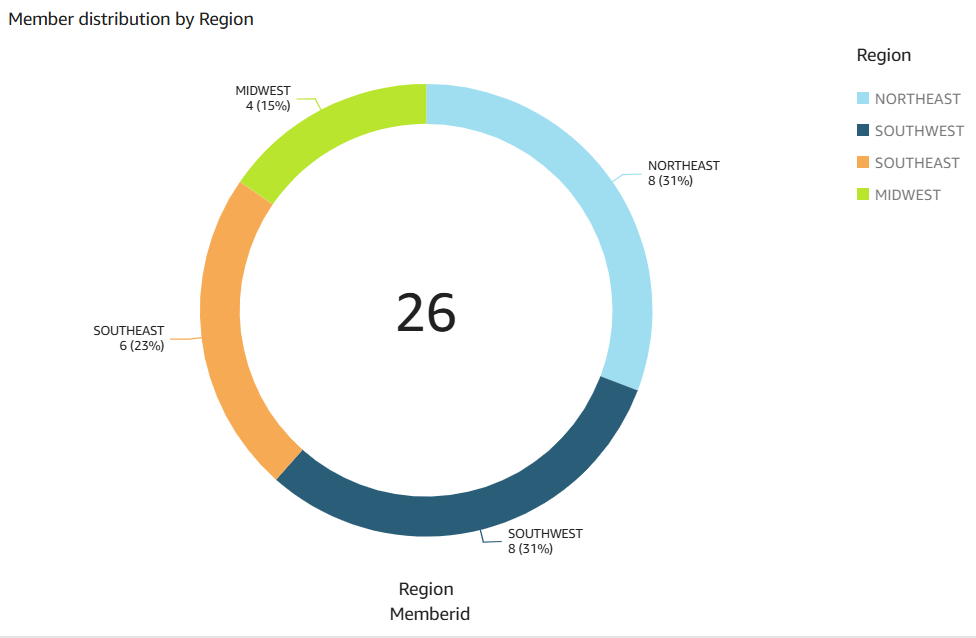
O elemento visual de dados a seguir foi criado pelo Amazon Q no QuickSight para a pergunta de análise show member distribution by region.
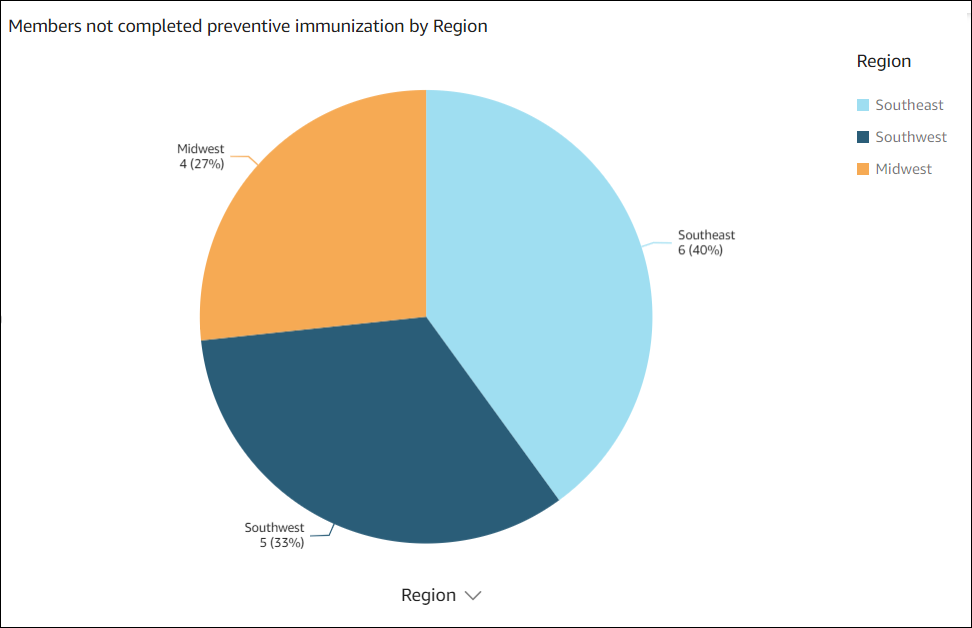
O elemento visual de dados a seguir foi criado pelo Amazon Q no QuickSight para a pergunta show member distribution by Region who have not completed preventive immunization, in pie chart.
Saída de narrativas analíticas
As capturas de tela a seguir mostram seções da narrativa analítica criada pelo Amazon Q no QuickSight para o prompt Build a data story about Region with most numbers of members. Also show the member distribution by age, member distribution by gender. Recommend how to motivate members to complete immunization. Include 4 points of supporting data for this pattern.
Na introdução, a narrativa analítica recomenda escolher a região com mais membros para obter o maior impacto dos esforços de imunização.

A narrativa analítica fornece uma análise do número de membros das quatro regiões. As regiões nordeste, sudoeste e sudeste têm o maior número de membros.

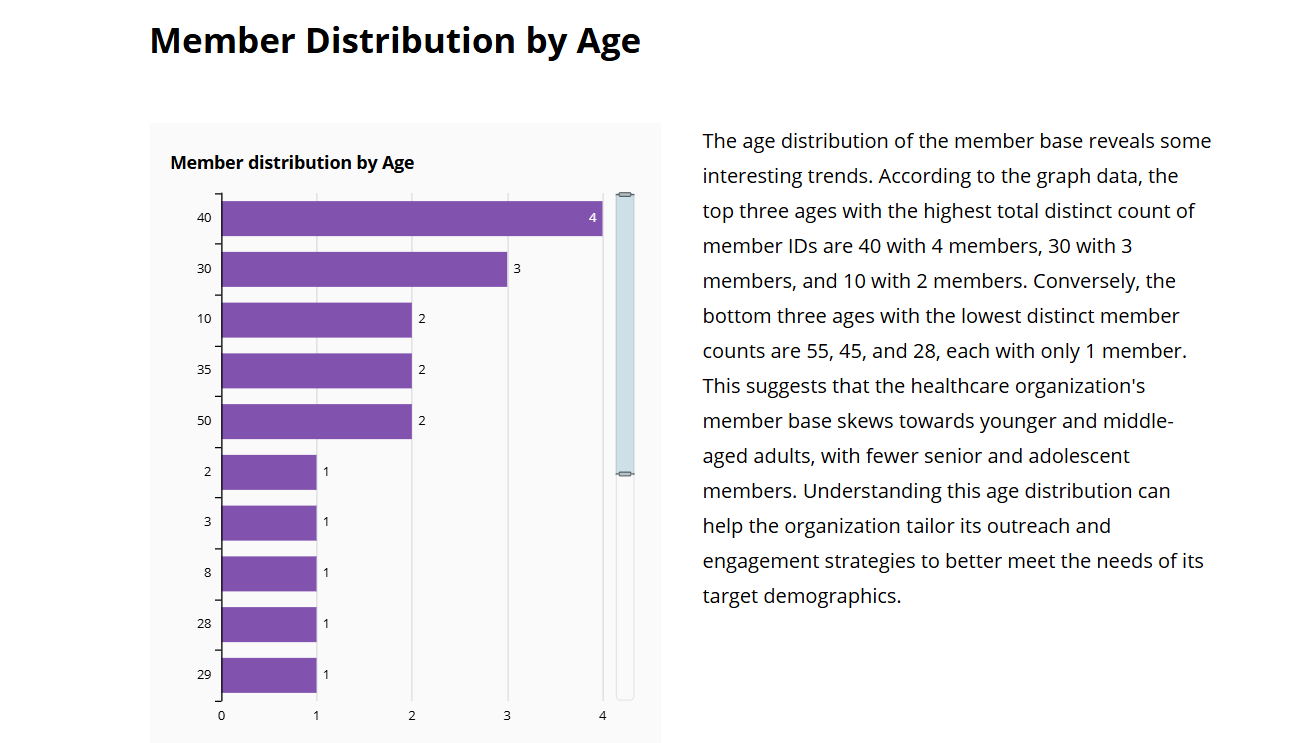
A narrativa analítica apresenta uma análise dos membros por idade.
A narrativa analítica se concentra nos esforços de imunização no centro-oeste.


Anexos
