As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
# Emule matrizes PL/SQL associativas Oracle no Amazon Aurora PostgreSQL e no Amazon RDS for PostgreSQL
*Rajkumar Raghuwanshi, Bhanu Ganesh Gudivada e Sachin Khanna, Amazon Web Services*
## Resumo
[Esse padrão descreve como emular matrizes PL/SQL associativas Oracle com posições de índice vazias nos ambientes Amazon [Aurora PostgreSQL e Amazon RDS for PostgreSQL](https://aws.amazon.com/rds/aurora/).](https://aws.amazon.com/rds/postgresql/) Ele também descreve algumas das diferenças entre matrizes PL/SQL associativas Oracle e matrizes PostgreSQL com relação à forma como cada uma lida com posições de índice vazias durante as migrações.
Fornecemos uma alternativa em PostgreSQL para o uso das funções `aws_oracle_ext` no tratamento de posições de índice vazias durante a migração de um banco de dados da Oracle. Este padrão faz uso de uma coluna adicional para armazenar as posições de índice e preserva o tratamento da Oracle para matrizes esparsas, ao mesmo tempo em que incorpora as funcionalidades nativas do PostgreSQL.
*Oracle*
Na Oracle, as coleções podem ser inicializadas como vazias e preenchidas utilizando o método `EXTEND` da coleção, que adiciona elementos `NULL` à matriz. Ao trabalhar com matrizes PL/SQL associativas indexadas por`PLS_INTEGER`, o `EXTEND` método adiciona `NULL` elementos sequencialmente, mas os elementos também podem ser inicializados em posições de índice não sequenciais. Qualquer posição de índice que não seja explicitamente inicializada permanece vazia.
Essa flexibilidade possibilita estruturas de matrizes esparsas nas quais os elementos podem ser preenchidos em posições arbitrárias. Ao realizar iteração pelas coleções usando um `FOR LOOP` com limites `FIRST` e `LAST`, apenas os elementos inicializados (sejam `NULL` ou com um valor definido) são processados, enquanto as posições vazias são ignoradas.
*PostgreSQL (Amazon Aurora e Amazon RDS)*
O PostgreSQL trata valores vazios de maneira diferente de valores `NULL`. Ele armazena valores vazios como entidades distintas que ocupam um byte de armazenamento. Quando uma matriz contém valores vazios, o PostgreSQL atribui posições de índice sequenciais da mesma forma que para valores não vazios. Porém, a indexação sequencial requer processamento adicional, pois o sistema precisa iterar por todas as posições indexadas, incluindo as vazias. Isso torna a criação tradicional de matrizes ineficiente para conjuntos de dados esparsos.
*AWS Schema Conversion Tool*
O [AWS Schema Conversion Tool (AWS SCT)](https://docs.aws.amazon.com/SchemaConversionTool/) normalmente lida com Oracle-to-PostgreSQL migrações usando `aws_oracle_ext` funções. Neste padrão, propomos uma abordagem alternativa que emprega as funcionalidades nativas do PostgreSQL, combinando tipos de matrizes do PostgreSQL com uma coluna adicional para armazenar as posições de índice. Dessa forma, o sistema pode realizar iteração pelas matrizes usando apenas a coluna de índice.
## Pré-requisitos e limitações
**Pré-requisitos **
+ Um ativo Conta da AWS
+ Permissões de administrador no AWS Identity and Access Management (IAM)
+ Uma instância compatível com Amazon RDS ou Aurora PostgreSQL
+ Habilidades de arquiteto ou desenvolvedor de banco de dados com Oracle e PostgreSQL
**Limitações**
+ Alguns Serviços da AWS não estão disponíveis em todos Regiões da AWS. Para conferir a disponibilidade de uma região, consulte [Serviços da AWS by Region](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/). Para endpoints específicos, consulte a página [Cotas e endpoints de serviços](https://docs.aws.amazon.com/general/latest/gr/aws-service-information.html) e clique no link correspondente ao serviço desejado.
**Versões do produto**
Este padrão foi testado com as seguintes versões:
+ Amazon Aurora PostgreSQL 13.3
+ Amazon RDS para PostgreSQL 13.3
+ AWS SCT 1.0.674
+ Oracle 19c EE
## Arquitetura
**Pilha de tecnologia de origem**
+ On-premises Banco de dados Oracle
**Pilha de tecnologias de destino**
+ Amazon Aurora PostgreSQL
+ Amazon RDS para PostgreSQL
**Arquitetura de destino**
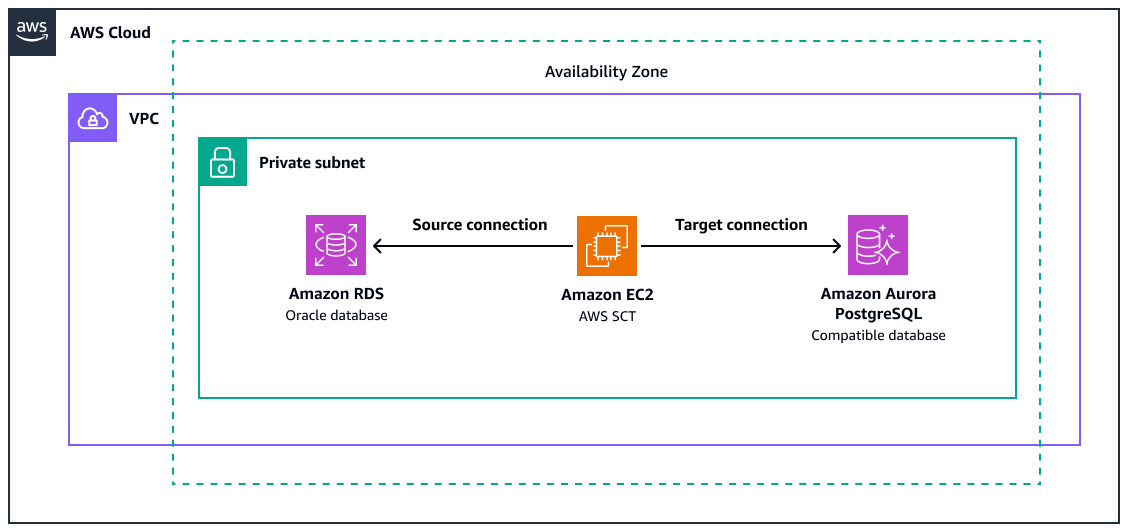
O diagrama mostra o seguinte:
+ Uma instância de banco de dados de origem no Amazon RDS para Oracle
+ Uma instância do Amazon EC2 AWS SCT para converter funções Oracle para o equivalente do PostgreSQL
+ Um banco de dados de destino que seja compatível com o Amazon Aurora PostgreSQL
## Ferramentas
**Serviços da AWS**
+ O [Amazon Aurora](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html) é um mecanismo de banco de dados relacional totalmente gerenciado criado para a nuvem e compatível com o MySQL e o PostgreSQL.
+ [O Amazon Aurora PostgreSQL-Compatible Edition](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.AuroraPostgreSQL.html) é um mecanismo de banco de dados ACID-compliant relacional totalmente gerenciado que ajuda você a configurar, operar e escalar implantações do PostgreSQL.
+ O [Amazon Elastic Compute Cloud (Amazon EC2)](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/concepts.html) oferece capacidade de computação escalável na Nuvem AWS. Você poderá iniciar quantos servidores virtuais precisar e escalá-los na vertical rapidamente.
+ O [Amazon Relational Database Service (Amazon RDS)](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Welcome.html) ajuda você a configurar, operar e escalar um banco de dados relacional na Nuvem AWS.
+ O [Amazon Relational Database Service (Amazon RDS)](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Oracle.html) para Oracle ajuda você a configurar, operar e escalar um banco de dados relacional da Oracle na Nuvem AWS.
+ O [Amazon Relational Database Service (Amazon RDS) para PostgreSQL](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_PostgreSQL.html) ajuda você a configurar, operar e escalar um banco de dados relacional do PostgreSQL na Nuvem AWS.
+ [AWS Schema Conversion Tool (AWS SCT)](https://docs.aws.amazon.com/SchemaConversionTool/latest/userguide/CHAP_Welcome.html) oferece suporte a migrações heterogêneas de banco de dados convertendo automaticamente o esquema do banco de dados de origem e a maior parte do código personalizado em um formato compatível com o banco de dados de destino.
**Outras ferramentas**
+ O [Oracle SQL Developer](https://www.oracle.com/database/technologies/appdev/sqldeveloper-landing.html) é um ambiente de desenvolvimento integrado que simplifica o desenvolvimento e o gerenciamento de bancos de dados Oracle em implantações tradicionais e baseadas em nuvem.
+ O [pgAdmin](https://www.pgadmin.org/) é uma ferramenta de gerenciamento de código aberto para PostgreSQL. Ele fornece uma interface gráfica que ajuda você a criar, manter e usar objetos de banco de dados. Neste padrão, o pgAdmin se conecta à instância de banco de dados RDS para PostgreSQL e realiza consultas nos dados. Como alternativa, você pode usar o cliente de linha de comandos psql.
## Práticas recomendadas
+ Teste os limites do conjunto de dados e os cenários de borda.
+ Considere implementar o tratamento de erros para condições de índice fora dos limites.
+ Otimize as consultas para evitar a verificação de conjuntos de dados esparsos.
## Épicos
### Comportamento de matrizes associativas da Oracle (origem)
| Tarefa | Description | Habilidades necessárias |
| --- | --- | --- |
| Crie um PL/SQL bloco de origem no Oracle. | Crie um PL/SQL bloco de origem no Oracle que use a seguinte matriz associativa:DECLARE
TYPE country_codes IS TABLE OF VARCHAR2(100) INDEX BY pls_integer;
cc country_codes;
cc_idx NUMBER := NULL;
BEGIN
cc(7) := 'India';
cc(3) := 'UK';
cc(5) := 'USA';
cc(0) := 'China';
cc(-2) := 'Invalid';
dbms_output.put_line('cc_length:' || cc.COUNT);
IF (cc.COUNT > 0) THEN
cc_idx := cc.FIRST;
FOR i IN 1..cc.COUNT LOOP
dbms_output.put_line('cc_idx:' || cc_idx || ' country:' || cc(cc_idx));
cc_idx := cc.next(cc_idx);
END LOOP;
END IF;
END;
| DBA |
| Execute o PL/SQL quarteirão. | Execute o PL/SQL bloco de origem no Oracle. Se houver lacunas entre os valores dos índices de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop da Oracle itere apenas pelas posições de índice. | DBA |
| Revise a saída. | Cinco elementos foram inseridos na matriz (`cc`) em intervalos não consecutivos. A contagem da matriz é mostrada na saída a seguir:cc_length:5
cc_idx:-2 country:Invalid
cc_idx:0 country:China
cc_idx:3 country:UK
cc_idx:5 country:USA
cc_idx:7 country:India
| DBA |
### Comportamento de matrizes associativas do PostgreSQL (destino)
| Tarefa | Description | Habilidades necessárias |
| --- | --- | --- |
| Crie um PL/pgSQL bloco de destino no PostgreSQL. | Crie um PL/pgSQL bloco de destino no PostgreSQL que use a seguinte matriz associativa:DO $$
DECLARE
cc character varying(100)[];
cc_idx integer := NULL;
BEGIN
cc[7] := 'India';
cc[3] := 'UK';
cc[5] := 'USA';
cc[0] := 'China';
cc[-2] := 'Invalid';
RAISE NOTICE 'cc_length: %', ARRAY_LENGTH(cc, 1);
IF (ARRAY_LENGTH(cc, 1) > 0) THEN
FOR i IN ARRAY_LOWER(cc, 1)..ARRAY_UPPER(cc, 1)
LOOP
RAISE NOTICE 'cc_idx:% country:%', i, cc[i];
END LOOP;
END IF;
END;
$$;
| DBA |
| Execute o PL/pgSQL quarteirão. | Execute o PL/pgSQL bloco de destino no PostgreSQL. Se houver lacunas entre os valores dos índices de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop do PostgreSQL itere somente pelas posições do índice. | DBA |
| Revise a saída. | O comprimento da matriz é maior que cinco porque o valor `NULL` é armazenado nas lacunas entre as posições de índice. Como mostrado na saída a seguir, o loop realiza dez iterações para recuperar cinco valores na matriz.cc_length:10
cc_idx:-2 country:Invalid
cc_idx:-1 country:
cc_idx:0 country:China
cc_idx:1 country:
cc_idx:2 country:
cc_idx:3 country:UK
cc_idx:4 country:
cc_idx:5 country:USA
cc_idx:6 country:
cc_idx:7 country:India
| DBA |
### Simulação do comportamento de matrizes associativas da Oracle
| Tarefa | Description | Habilidades necessárias |
| --- | --- | --- |
| Crie um PL/pgSQL bloco de destino com uma matriz e um tipo definido pelo usuário. | Para otimizar a performance e corresponder à funcionalidade da Oracle, podemos criar um tipo definido pelo usuário que armazena tanto as posições de índice quanto os dados correspondentes. Essa abordagem reduz iterações desnecessárias ao manter associações diretas entre os índices e os valores.DO $$
DECLARE
cc country_codes[];
cc_append country_codes := NULL;
i record;
BEGIN
cc_append.idx = 7;
cc_append.val = 'India';
cc := array_append(cc, cc_append);
cc_append.idx = 3;
cc_append.val = 'UK';
cc := array_append(cc, cc_append);
cc_append.idx = 5;
cc_append.val = 'USA';
cc := array_append(cc, cc_append);
cc_append.idx = 0;
cc_append.val = 'China';
cc := array_append(cc, cc_append);
cc_append.idx = - 2;
cc_append.val = 'Invalid';
cc := array_append(cc, cc_append);
RAISE NOTICE 'cc_length: %', ARRAY_LENGTH(cc, 1);
IF (ARRAY_LENGTH(cc, 1) > 0) THEN
FOR i IN (
SELECT
*
FROM
unnest(cc)
ORDER BY
idx)
LOOP
RAISE NOTICE 'cc_idx:% country:%', i.idx, i.val;
END LOOP;
END IF;
END;
$$;
| DBA |
| Execute o PL/pgSQL quarteirão. | Execute o PL/pgSQL bloco alvo. Se houver lacunas entre os valores dos índices de uma matriz associativa, nenhum dado será armazenado nessas lacunas. Isso permite que o loop do PostgreSQL itere somente pelas posições do índice. | DBA |
| Revise a saída. | Como mostrado na saída a seguir, o tipo definido pelo usuário armazena apenas elementos de dados preenchidos, o que significa que o comprimento da matriz corresponde ao número de valores. Como resultado, as iterações do `LOOP` são otimizadas para processar apenas dados existentes, eliminando a necessidade de monitorar posições vazias.cc_length:5
cc_idx:-2 country:Invalid
cc_idx:0 country:China
cc_idx:3 country:UK
cc_idx:5 country:USA
cc_idx:7 country:India
| DBA |
## Solução de problemas
| Problema | Solução |
| --- | --- |
| **Erro de índice fora dos limites**[See the AWS documentation website for more details](http://docs.aws.amazon.com/pt_br/prescriptive-guidance/latest/patterns/emulate-oracle-plsql-associative-arrays-in-aurora-and-rds-postgresql.html) | Você pode validar a existência do índice antes do acesso usando um filtro de `WHERE` cláusula na `idx` coluna ao desaninhar a matriz ou pode implementar verificações de limites em seu código. PL/pgSQL |
| **Manipulação de valores NULL**[See the AWS documentation website for more details](http://docs.aws.amazon.com/pt_br/prescriptive-guidance/latest/patterns/emulate-oracle-plsql-associative-arrays-in-aurora-and-rds-postgresql.html) | Certifique-se de que ambos os campos do tipo definido pelo usuário estejam preenchidos antes de usar. `array_append()` Adicione verificações NULL explícitas da seguinte forma: `IF cc_append.val IS NOT NULL THEN cc := array_append(cc, cc_append); END IF;` |
## Recursos relacionados
**AWS documentação**
+ [AWS blog de banco de dados](https://aws.amazon.com/blogs/database/)
+ [Manual de migração da Oracle para o Aurora PostgreSQL](https://docs.aws.amazon.com/dms/latest/oracle-to-aurora-postgresql-migration-playbook/chap-oracle-aurora-pg.html)
**Outras documentações**
+ [Oracle associative arrays](https://docs.oracle.com/en/database/oracle/oracle-database/23/lnpls/associative-arrays.html#GUID-8060F01F-B53B-48D4-9239-7EA8461C2170)
+ [PostgreSQL array functions and operators](https://www.postgresql.org/docs/current/functions-array.html)
+ [PostgreSQL user-defined types](https://www.postgresql.org/docs/current/sql-createtype.html)
## Mais informações
*Considerações sobre a performance*
+ Essa abordagem reduz a sobrecarga de iteração em 50% ou mais para matrizes esparsas em comparação com matrizes PostgreSQL nativas com espaços reservados NULL.
+ A eficiência do armazenamento melhora porque somente os dados reais são armazenados, não as posições vazias do índice.
*Notas de compatibilidade*
+ Esse padrão mantém a semântica de matriz esparsa da Oracle enquanto usa os recursos de matriz nativa do PostgreSQL.
+ A solução é compatível com todas as versões do PostgreSQL que oferecem suporte a tipos compostos definidos pelo usuário.