As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Crie um modelo de previsão de inicialização a frio usando o DeepAR para séries temporais no SageMaker Amazon AI Studio Lab
Ivan Cui e Eyal Shacham, Amazon Web Services
Resumo
Seja para alocar recursos de forma mais eficiente para o tráfego da web, prever a demanda de pacientes para o planejamento de pessoal ou antecipar as vendas dos produtos de uma empresa, a previsão é uma ferramenta essencial. A previsão de inicialização a frio gera previsões para séries temporais com poucos dados históricos, como um novo produto que acaba de ser lançado no mercado varejista. Esse padrão usa o algoritmo de previsão Amazon SageMaker AI DeepAR para treinar um modelo de previsão de inicialização a frio e demonstra como realizar previsões em itens de inicialização a frio.
O DeepAR é um algoritmo de aprendizado supervisionado para previsão de séries temporais escalares (unidimensionais) com o uso de redes neurais recorrentes (RNN). O DeepAR adota a abordagem de treinar um único modelo de forma conjunta sobre todas as séries temporais dos produtos relacionados.
Os métodos tradicionais de previsão de séries temporais, como o autoregressive integrated moving average (ARIMA) ou exponential smoothing (ETS), dependem muito das séries temporais históricas de cada produto individual. Portanto, esses métodos não são eficazes para a previsão de inicialização a frio. Quando seu conjunto de dados contém centenas de séries temporais relacionadas, o DeepAR supera os métodos padrão ARIMA e ETS. Você também pode usar o modelo treinado para gerar previsões para novas séries temporais que sejam semelhantes às séries temporais nas quais ele foi treinado.
Pré-requisitos e limitações
Pré-requisitos
Um ativo Conta da AWS.
Um aplicativo do Amazon SageMaker AI Studio Lab ou do Jupiter Lab.
Um bucket do Amazon Simple Storage Service (Amazon S3) com permissões de leitura e gravação.
Conhecimento de programação com o Python.
Conhecimento do uso de um caderno Jupyter.
Limitações
Invocar o modelo de previsão sem nenhum ponto de dados históricos retornará um erro. Invocar o modelo com poucos pontos de dados históricos retornará previsões imprecisas com alta confiança. Este padrão propõe uma abordagem para resolver essas limitações conhecidas da previsão de inicialização a frio.
Alguns Serviços da AWS não estão disponíveis em todos Regiões da AWS. Para conferir a disponibilidade de uma região, consulte AWS Services by Region
. Para endpoints específicos, consulte Service endpoints and quotas e clique no link correspondente ao serviço desejado.
Versões do produto
Python versão 3.10 ou posterior.
O notebook do padrão foi testado no Amazon SageMaker AI Studio em uma instância ml.t3.medium com o kernel Python 3 (Data Science).
Arquitetura
O diagrama a seguir mostra o fluxo de trabalho e os componentes da arquitetura desse padrão.
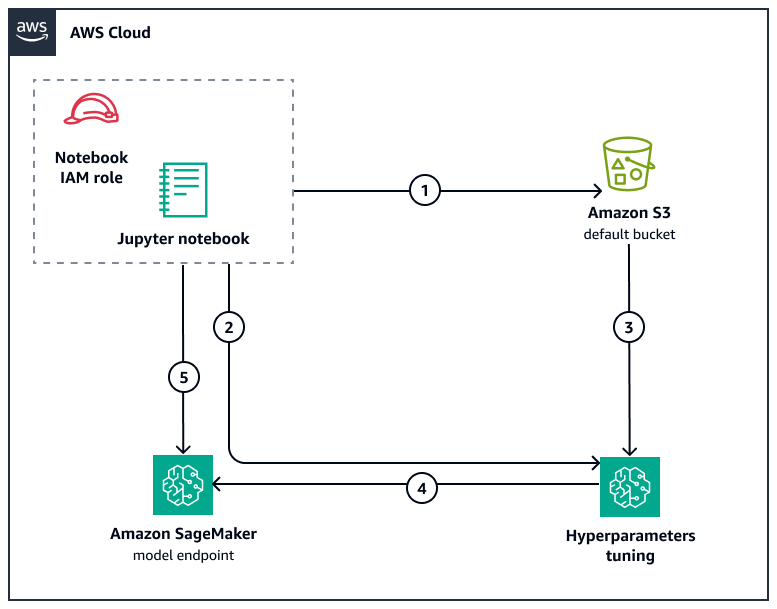
O fluxo de trabalho executa as seguintes tarefas:
Os arquivos de entrada com os dados de treinamento e de teste são sintetizados e, em seguida, carregados em um bucket do Amazon S3. Esses dados incluem várias séries temporais com características categóricas e dinâmicas, além dos valores de destino (a serem previstos). O caderno Jupyter visualiza os dados para uma melhor compreensão dos requisitos dos dados de treinamento e dos valores previstos que são esperados.
Um trabalho de ajuste de hiperparâmetros é criado para treinar o modelo e encontrar o melhor modelo com base nas métricas previamente definidas.
Os arquivos de entrada são baixados do bucket do Amazon S3 para cada instância dos trabalhos de ajuste de hiperparâmetros.
Depois que o trabalho do sintonizador seleciona o melhor modelo com base no limite predefinido do sintonizador, o modelo é implantado como um endpoint de IA. SageMaker
Depois disso, o modelo implantado está pronto para ser invocado e suas previsões são validadas em relação aos dados de teste.
O caderno demonstra como o modelo faz boas previsões dos valores de destino quando há um número adequado de pontos de dados históricos disponíveis. No entanto, quando invocamos o modelo com um número reduzido de pontos de dados históricos, que representam um produto a frio, as predições de modelo não correspondem aos dados de teste originais, nem mesmo dentro dos níveis de confiança do modelo. No padrão, um novo modelo é desenvolvido para produtos a frio, no qual o comprimento inicial de contexto (ou os pontos previstos) é definido pela quantidade de pontos históricos disponíveis, e um novo modelo é treinado iterativamente à medida que novos pontos de dados são obtidos. O caderno demonstra que o modelo fará previsões precisas, desde que o número de pontos de dados históricos seja próximo ao respectivo comprimento de contexto.
Ferramentas
Serviços da AWS
AWS Identity and Access Management (IAM) ajuda você a gerenciar com segurança o acesso aos seus AWS recursos controlando quem está autenticado e autorizado a usá-los.
O Amazon SageMaker AI é um serviço gerenciado de aprendizado de máquina (ML) que ajuda você a criar e treinar modelos de ML e depois implantá-los em um ambiente hospedado pronto para produção.
O Amazon SageMaker AI Studio é um ambiente de desenvolvimento integrado (IDE) baseado na web para ML que permite criar, treinar, depurar, implantar e monitorar seus modelos de ML.
O Amazon Simple Storage Service (Amazon S3) é um serviço de armazenamento de objetos baseado na nuvem que ajuda você a armazenar, proteger e recuperar qualquer quantidade de dados.
Outras ferramentas
Python
é uma linguagem de programação de computador de uso geral.
Repositório de código
O código desse padrão está disponível no repositório GitHub DeepAR- ColdProduct -Pattern
Práticas recomendadas
Treine o modelo em um ambiente virtual e use sempre o controle de versão para obter a maior reprodutibilidade possível.
Inclua tantas características categóricas de alta qualidade quanto possível para obter o modelo preditivo com melhor performance.
Certifique-se de que os metadados contenham itens categóricos semelhantes para que o modelo possa inferir adequadamente as previsões de produtos de inicialização a frio.
Execute um trabalho de ajuste de hiperparâmetros para obter o modelo preditivo de melhor performance.
Neste padrão, o modelo que você desenvolve tem um comprimento de contexto de 24 horas, o que significa que ele fará previsões para as próximas 24 horas. Se você tentar prever as próximas 24 horas com menos de 24 horas de dados históricos, a precisão das predições de modelo diminui de forma linear conforme a quantidade de pontos de dados históricos disponíveis. Para mitigar esse problema, basta criar um novo modelo para cada conjunto de pontos de dados históricos até que o número alcance o comprimento de previsão (contexto) desejado. Por exemplo, comece com um modelo de comprimento de contexto de 2 horas e, em seguida, aumente-o progressivamente para 4 horas, 8 horas, 16 horas e 24 horas.
Épicos
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Inicie o ambiente de caderno. |
Para obter mais informações, consulte Launch Amazon SageMaker AI Studio na documentação de SageMaker IA. | Cientista de dados |
| Tarefa | Description | Habilidades necessárias |
|---|---|---|
Configure o ambiente virtual para o treinamento de modelo. | Para configurar seu ambiente virtual para o treinamento de modelo, siga as seguintes etapas:
Para obter mais informações, consulte Carregar arquivos para o SageMaker AI Studio Classic na documentação do SageMaker AI. | Cientista de dados |
Crie e valide um modelo de previsão. |
| Cientista de dados |
Recursos relacionados
