As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Ciclo de vida dos dados
Para criar um pipeline de dados, você deve primeiro ingerir dados na AWS de uma fonte de dados externa ou interna, como um servidor de arquivos, banco de dados, bucket de armazenamento ou de uma chamada de API. Os dados ingeridos podem ou não passar por transformações, como anonimização, eliminação de colunas ou limpeza de dados.
Esta seção oferece uma visão geral das etapas do processo do ciclo de vida dos dados, conforme mostrado no diagrama a seguir.
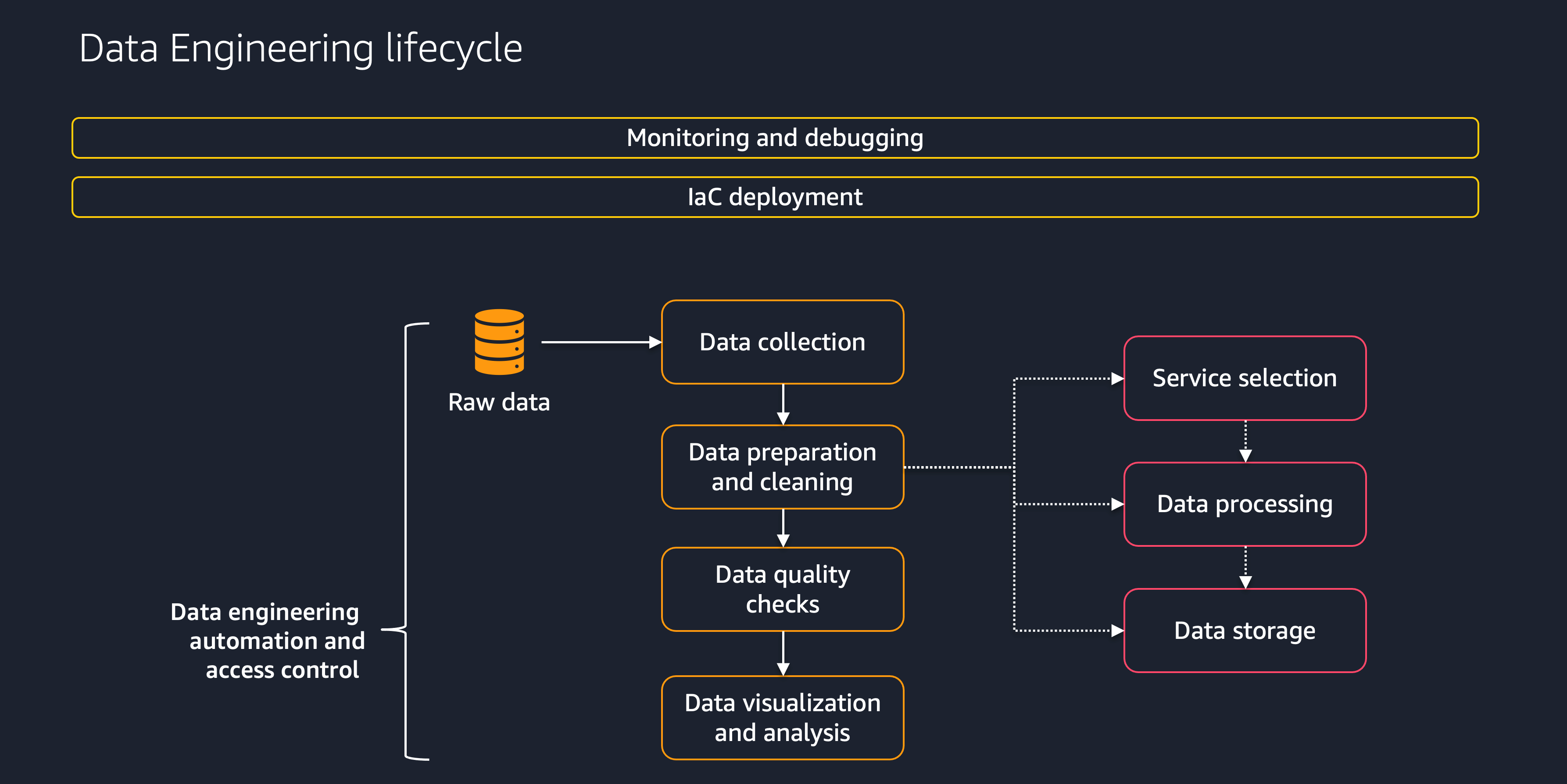
Essas etapas incluem o seguinte:
-
Coleta de dados
-
Preparação e limpeza de dados
-
Verificações de qualidade de dados
-
Visualização e análise de dados
-
Monitoramento e depuração
-
Implantação de IaC
-
Automação e controle de acesso
