As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Estudo de caso
Esta seção examina um cenário de negócios do mundo real e uma aplicação para quantificar a incerteza em sistemas de aprendizado profundo. Suponha que você queira que um modelo de machine learning que julgue automaticamente se uma frase é gramaticalmente inaceitável (caso negativo) ou aceitável (caso positivo). Considere o seguinte processo comercial: se o modelo sinalizar uma frase como gramaticalmente aceitável (positivo), você a processará automaticamente, sem análise humana. Se o modelo sinalizar a frase como inaceitável (negativo), você passará a frase para um humano, para análise e correção. O estudo de caso usa deep ensembles em conjunto com a escala de temperatura.
Esse cenário tem dois objetivos comerciais:
-
Alto recall para casos negativos. Queremos capturar todas as frases com erros gramaticais.
-
Redução de workload manual. Queremos processar automaticamente casos que não tenham erros gramaticais, na maior medida possível.
Resultados da linha de base
Quando se aplica um único modelo aos dados sem dropout no momento do teste, estes são os resultados:
-
Para amostra positiva: recall = 94%, precisão = 82%
-
Para amostra negativa: recall = 52%, precisão = 79%
O modelo tem uma performance muito menor para amostras negativas. No entanto, para aplicações comerciais, o recall de amostras negativas deve ser a métrica mais importante.
Aplicação de deep ensembles
Para quantificar a incerteza do modelo, usamos os desvios padrão das previsões individuais do modelo em deep ensembles. Nossa hipótese é que, para falsos positivos (false positives, FP) e falsos negativos (false negatives, FN), esperamos ver uma incerteza muito maior do que para verdadeiros positivos (true positives, TP) e verdadeiros negativos (true negatives, TN). Especificamente, o modelo deve ser de alta confiança quando está correto e de baixa confiança quando está errado, para que possamos usar a incerteza para saber quando confiar na saída do modelo.
A matriz de confusão a seguir mostra a distribuição da incerteza nos dados FN, FP, TN e TP. A probabilidade de desvio padrão negativo é o desvio padrão da probabilidade de negativos entre os modelos. A mediana, a média e os desvios padrão são agregados em todo o conjunto de dados.
| Probabilidade de desvio padrão negativo | |||
|---|---|---|---|
| Rótulo | Mediana | Média | Desvio padrão |
FN |
0.061 |
0.060 |
0.027 |
FP |
0.063 |
0.062 |
0.040 |
TN |
0.039 |
0.045 |
0.026 |
TP |
0.009 |
0.020 |
0.025 |
Como mostra a matriz, o modelo teve o melhor desempenho para TP, de modo que tem o nível de incerteza mais baixo. O modelo teve o pior desempenho para FP, de modo que tem o nível de incerteza mais alto e está de acordo com nossa hipótese.
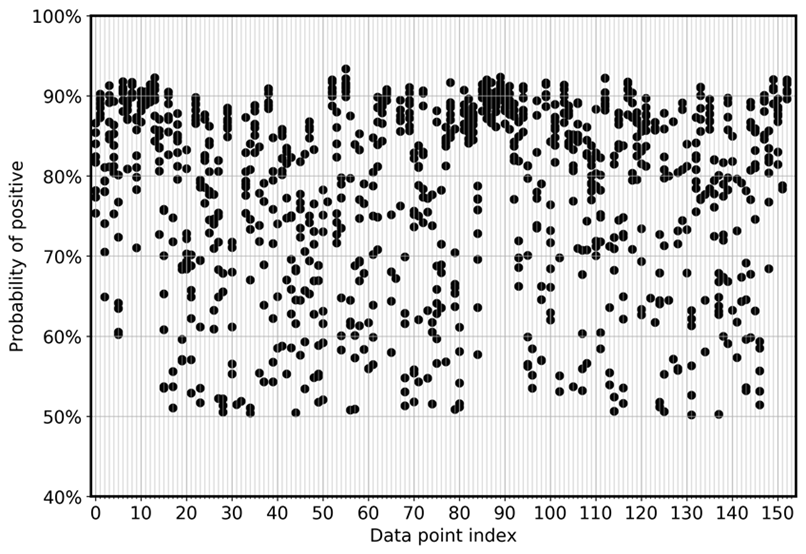
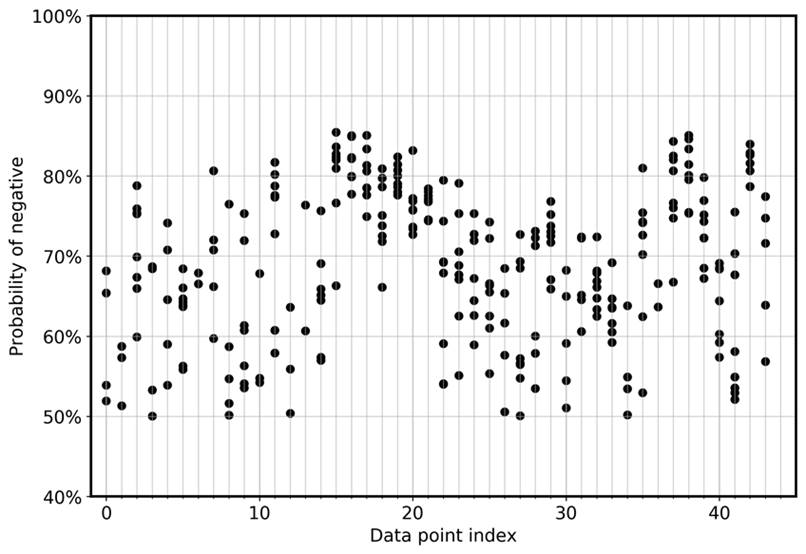
Para visualizar diretamente o desvio do modelo entre os ensembles, o gráfico a seguir traça a probabilidade em uma visualização com dispersão para FN e FP para os dados CoLA. Cada linha vertical é para uma amostra de entrada específica. O gráfico mostra oito visualizações de modelos de ensemble. Ou seja, cada linha vertical tem oito pontos de dados. Esses pontos se sobrepõem perfeitamente ou são distribuídos em um intervalo.
O primeiro gráfico mostra que, para os FPs, a probabilidade de ser positivo se distribui entre 0,5 e 0,925 em todos os oito modelos de ensemble.
Da mesma forma, o gráfico a seguir mostra que, para os FNs, a probabilidade de ser negativo se distribui entre 0,5 e 0,85 entre os oito modelos de ensemble.
Definir uma regra de decisão
Para maximizar o benefício dos resultados, usamos a seguinte regra de ensemble: para cada entrada, usamos o modelo que tem a mais baixa probabilidade de ser positivo (aceitável) para tomar decisões que serão sinalizadas. Se a probabilidade selecionada for maior ou igual ao valor limite, sinalizaremos o caso como aceitável e o processaremos automaticamente. Caso contrário, enviaremos o caso para análise humana. Essa é uma regra de decisão conservadora, apropriada para ambientes altamente regulamentados.
Avaliar os resultados
O gráfico a seguir mostra a precisão, o recall e a taxa automática (automação) para os casos negativos (casos com erros gramaticais). A taxa de automação se refere à porcentagem de casos que serão processados automaticamente porque o modelo sinaliza a frase como aceitável. Um modelo perfeito com 100% de recall e precisão alcançaria uma taxa de automação de 69% (casos positivos/total de casos), porque somente casos positivos serão processados automaticamente.
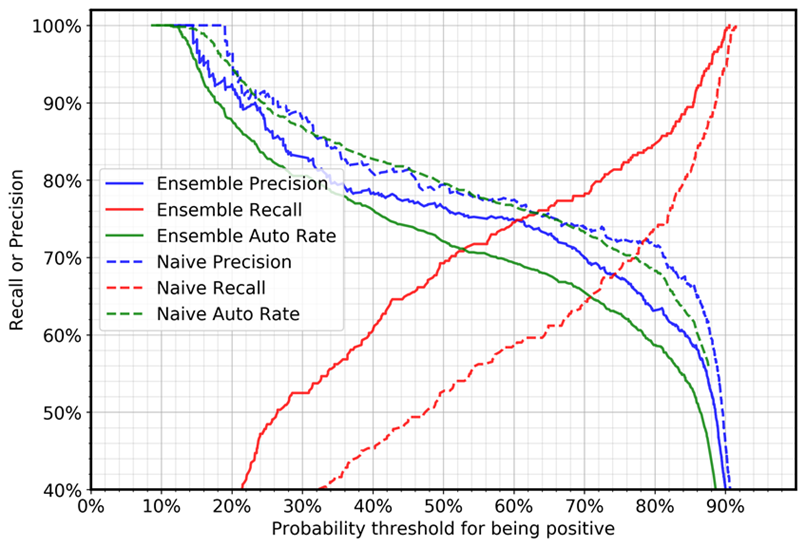
A comparação entre o deep ensemble e os casos simples mostra que, para a mesma configuração de limite, o recall aumenta drasticamente e a precisão diminui ligeiramente. (A taxa de automação depende da proporção de amostras positivas e negativas no conjunto de dados de teste.) Por exemplo:
-
Usando um valor limite de 0,5:
-
Com um modelo único, o recall para casos negativos será de 52%.
-
Com a abordagem de deep ensemble, o valor do recall será de 69%.
-
-
Usando um valor limite de 0,88:
-
Com um modelo único, o recall para casos negativos será de 87%.
-
Com a abordagem de deep ensemble, o valor do recall será de 94%.
-
Você pode ver que o deep ensemble pode impulsionar certas métricas (no nosso caso, o recall de casos negativos) para aplicações empresariais, sem a exigência de aumentar o tamanho dos dados de treinamento, sua qualidade ou de fazer uma alteração no método do modelo.
