As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
# MyDumper
[MyDumper](https://github.com/mydumper/mydumper#what-is-mydumper)(GitHub) é uma ferramenta de migração lógica de código aberto que consiste em dois utilitários:
+ MyDumper exporta um backup consistente dos bancos de dados MySQL. Ele é compatível com o backup do banco de dados usando vários threads paralelos, até um thread por núcleo de CPU disponível.
+ myloader lê os arquivos de backup criados por MyDumper, se conecta à instância do banco de dados de destino e, em seguida, restaura o banco de dados.
O diagrama a seguir mostra as etapas de alto nível envolvidas na migração de um banco de dados usando um arquivo de MyDumper backup. Esse diagrama de arquitetura inclui três opções para migrar o arquivo de backup do data center on-premises para uma instância do EC2 na Nuvem AWS.
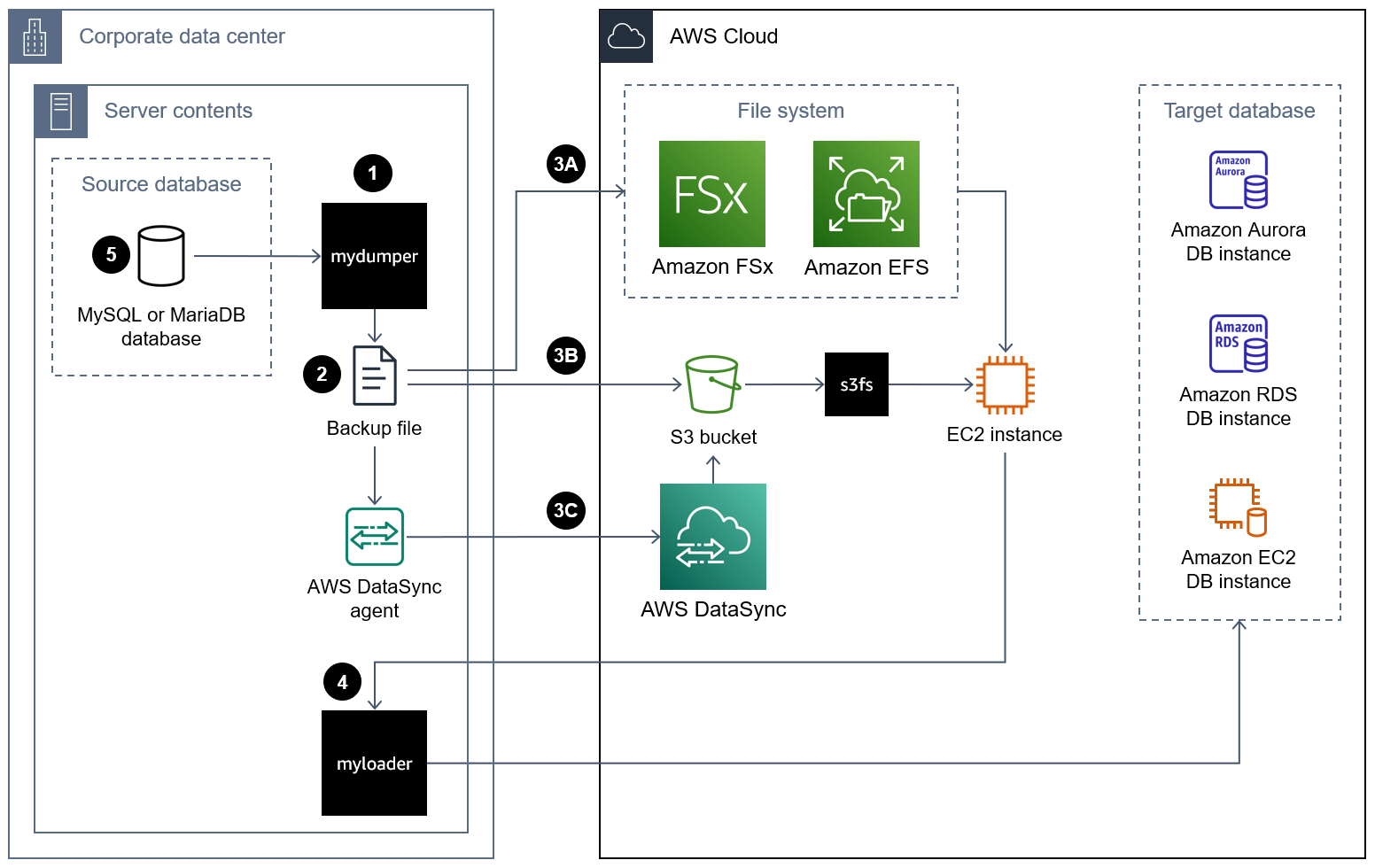
A seguir estão as etapas a serem usadas MyDumper para migrar um banco de dados para o Nuvem AWS:
1. Instale MyDumper e meu carregador. Para obter instruções, consulte [Como instalar mydumper/myloader](https://github.com/mydumper/mydumper#how-to-install-mydumpermyloader) (). GitHub
1. Use MyDumper para criar um backup do banco de dados MySQL ou MariaDB de origem. Para obter instruções, consulte [Como usar MyDumper](https://github.com/mydumper/mydumper#how-to-use-mydumper).
1. Mova o arquivo de backup para uma instância do EC2 no Nuvem AWS usando uma das seguintes abordagens:
**Abordagem 3A** — Monte um sistema de arquivos [Amazon FSx](https://docs.aws.amazon.com/fsx/latest/WindowsGuide/using-file-shares.html) [ou Amazon Elastic File System (Amazon EFS)](https://docs.aws.amazon.com/efs/latest/ug/efs-onpremises.html) no servidor local que executa sua instância de banco de dados. Você pode usar AWS Direct Connect ou Site-to-Site VPN para estabelecer a conexão. Você pode fazer backup diretamente do banco de dados no compartilhamento de arquivos montado, ou pode realizar o backup em duas etapas, fazendo backup do banco de dados em um sistema de arquivos local e, em seguida, carregando-o no volume do FSx ou EFS montado. Em seguida, monte o sistema de arquivos Amazon FSx ou Amazon EFS, que também é montado no servidor on-premises, em uma instância do EC2.
**Abordagem 3B** — Use o AWS CLI AWS SDK ou a API REST do Amazon S3 para mover diretamente o arquivo de backup do servidor local para um bucket do S3. Se o bucket do S3 de destino estiver em um Região da AWS local distante do data center, você poderá usar o [Amazon S3 Transfer Acceleration para transferir](https://docs.aws.amazon.com/AmazonS3/latest/userguide/transfer-acceleration.html) o arquivo mais rapidamente. Use o sistema de arquivos [s3fs-fuse](https://github.com/s3fs-fuse/s3fs-fuse) para montar o bucket do S3 na instância do EC2.
**Abordagem 3C**: instale o agente do AWS DataSync no data center on-premises e use o [AWS DataSync](https://docs.aws.amazon.com/datasync/latest/userguide/what-is-datasync.html) para mover o arquivo de backup para um bucket do Amazon S3. Use o sistema de arquivos [s3fs-fuse](https://github.com/s3fs-fuse/s3fs-fuse) para montar o bucket do S3 na instância do EC2.
**nota**
Você também pode usar o Gateway de Arquivos do Amazon S3 para transferir os grandes arquivos de backup do banco de dados para um bucket do S3 na Nuvem AWS. Para obter mais informações, consulte [Uso do Gateway de Arquivos do Amazon S3 para transferir arquivos de backup](amazon-s3-file-gateway.md) neste guia.
1. Use o myloader para restaurar o backup na instância do banco de dados de destino. Para obter instruções, consulte [myloader usage](https://github.com/mydumper/mydumper_docs/blob/0e5cd71a5549c8a5de0105adf4d5f95953eadb67/myloader_usage.rst) ()GitHub.
1. (Opcional) Você pode configurar a replicação entre o banco de dados de origem e a instância do banco de dados de destino. Você pode usar a replicação de log binário (binlog) para reduzir o tempo de inatividade. Para saber mais, consulte:
+ [Setting the replication source configuration](https://dev.mysql.com/doc/refman/5.7/en/replication-howto-masterbaseconfig.html) na documentação do MySQL
+ Para o Amazon Aurora, consulte o seguinte:
+ [Synchronizing the Amazon Aurora MySQL DB cluster with the MySQL database using replication](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Migrating.ExtMySQL.html#AuroraMySQL.Migrating.ExtMySQL.S3.RepSync) na documentação do Aurora
+ [Using binlog replication in Amazon Aurora](https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Replication.MySQL.html) na documentação do Aurora
+ Para o Amazon RDS, consulte o seguinte:
+ [Trabalhar com a replicação do MySQL](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_MySQL.Replication.html) na documentação do Amazon RDS
+ [Trabalhar com a replicação do MariaDB](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_MariaDB.Replication.html) na documentação do Amazon RDS
+ Para o Amazon EC2, consulte o seguinte:
+ [Setting Up Binary Log File Position Based Replication](https://dev.mysql.com/doc/mysql-replication-excerpt/8.0/en/replication-howto.html) na documentação do MySQL
+ [Setting Up Replicas](https://dev.mysql.com/doc/refman/8.0/en/replication-setup-replicas.html) na documentação do MySQL
+ [Setting Up Replication](https://mariadb.com/kb/en/setting-up-replication/) na documentação do MariaDB
## Vantagens
+ MyDumper suporta paralelismo usando multiencadeamento, o que melhora a velocidade das operações de backup e restauração.
+ MyDumper evita rotinas caras de conversão de conjuntos de caracteres, o que ajuda a garantir que o código seja altamente eficiente.
+ MyDumper simplifica a visualização e a análise de dados usando o despejo de arquivos separados para tabelas e metadados.
+ MyDumper mantém instantâneos em todos os segmentos e fornece posições precisas dos registros primários e secundários.
+ Você pode usar expressões regulares compatíveis com Perl (PCRE) para especificar se deseja incluir ou excluir tabelas ou bancos de dados.
## Limitações
+ Você poderá escolher outra ferramenta se seus processos de transformação de dados exigirem arquivos de despejo intermediários em formato simples, em vez do formato SQL.
+ O myloader não importa contas de usuário do banco de dados automaticamente. Se você estiver restaurando o backup no Amazon RDS ou no Aurora, recrie os usuários com as permissões necessárias. Para obter mais informações, consulte [Privilégios da conta de usuário mestre](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/UsingWithRDS.MasterAccounts.html) na documentação do Amazon RDS. Se você estiver restaurando o backup em uma instância de banco de dados do Amazon EC2, poderá exportar manualmente as contas de usuário do banco de dados de origem e importá-las para a instância do EC2.
## Práticas recomendadas
+ Configure MyDumper para dividir cada tabela em segmentos, como 10.000 linhas em cada segmento, e gravar cada segmento em um arquivo separado. Isso possibilita a importação de dados em paralelo posteriormente.
+ Se você estiver usando o mecanismo InnoDB, use a opção `--trx-consistency-only` para minimizar o bloqueio.
+ O uso MyDumper para exportar o banco de dados pode exigir muita leitura, e o processo pode afetar o desempenho geral do banco de dados de produção. Se você tiver uma instância de banco de dados de réplica, execute o processo de exportação da réplica. Antes de executar a exportação da réplica, interrompa o thread SQL de replicação. Isso ajuda o processo de exportação a ser executado mais rapidamente.
+ Não exporte o banco de dados durante o horário comercial de pico. Evitar os horários de pico pode estabilizar a performance do seu banco de dados primário de produção durante a exportação do banco de dados.
+ O Amazon RDS para MySQL não é compatível com o plug-in `keyring_aws`. Para obter mais informações, consulte [Problemas conhecidos e limitações](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/MySQL.KnownIssuesAndLimitations.html#MySQL.Concepts.Limits.KeyRing). Para migrar as tabelas criptografadas on-premises para a instância do Amazon RDS, nos scripts de backup, você precisa remover `ENCRYPTION` ou `DEFAULT ENCRYPTION` da sintaxe `CREATE TABLE`. Para criptografia em repouso, você pode usar uma chave do AWS Key Management Service (AWS KMS). Para ter mais informações, consulte [Criptografar recursos do Amazon RDS](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/Overview.Encryption.html).