As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Desacoplando relacionamentos de tabelas durante a decomposição do banco de dados
Esta seção fornece orientação sobre como detalhar relacionamentos complexos de tabelas e operações JOIN durante a decomposição monolítica do banco de dados. Uma junção de tabela combina linhas de duas ou mais tabelas com base em uma coluna relacionada entre elas. O objetivo de separar esses relacionamentos é reduzir o alto acoplamento entre tabelas e, ao mesmo tempo, manter a integridade dos dados nos microsserviços.
Esta seção contém os seguintes tópicos:
Estratégia de desnormalização
A desnormalização é uma estratégia de design de banco de dados que envolve a introdução intencional de redundância combinando ou duplicando dados em tabelas. Ao dividir um banco de dados grande em bancos de dados pequenos, pode fazer sentido duplicar alguns dados entre os serviços. Por exemplo, armazenar detalhes básicos do cliente, como nome e endereço de e-mail, tanto em um serviço de marketing quanto em um serviço de pedidos elimina a necessidade de pesquisas constantes entre serviços. O serviço de marketing pode precisar das preferências do cliente e das informações de contato para direcionar campanhas, enquanto o serviço de pedidos exige os mesmos dados para processamento de pedidos e notificações. Embora isso crie alguma redundância de dados, pode melhorar significativamente o desempenho e a independência do serviço, permitindo que a equipe de marketing opere suas campanhas sem depender de consultas de atendimento ao cliente em tempo real.
Ao implementar a desnormalização, concentre-se nos campos acessados com frequência que você identifica por meio de uma análise cuidadosa dos padrões de acesso aos dados. Você pode usar ferramentas, como Oracle AWR relatórios oupg_stat_statements, para entender quais dados geralmente são recuperados juntos. Os especialistas do domínio também podem fornecer informações valiosas sobre agrupamentos de dados naturais. Lembre-se de que a desnormalização não é uma all-or-nothing abordagem — apenas dados duplicados que comprovadamente melhoram o desempenho do sistema ou reduzem dependências complexas.
Reference-by-key estratégia
Uma reference-by-key estratégia é um padrão de design de banco de dados em que os relacionamentos entre entidades são mantidos por meio de chaves exclusivas, em vez de armazenar os dados reais relacionados. Em vez dos relacionamentos tradicionais de chave estrangeira, os microsserviços modernos geralmente armazenam apenas os identificadores exclusivos dos dados relacionados. Por exemplo, em vez de manter todos os detalhes do cliente na tabela de pedidos, o serviço de pedidos armazena apenas a ID do cliente e recupera informações adicionais do cliente por meio de uma chamada de API quando necessário. Essa abordagem mantém a independência do serviço e, ao mesmo tempo, garante o acesso aos dados relacionados.
Padrão CQRS
O padrão Command Query Responsibility Segregation (CQRS) separa as operações de leitura e gravação de um armazenamento de dados. Esse padrão é particularmente útil em sistemas complexos com requisitos de alto desempenho, especialmente aqueles com cargas assimétricas read/write . Se seu aplicativo frequentemente precisa de dados combinados de várias fontes, você pode criar um modelo CQRS dedicado em vez de junções complexas. Por exemplo, em vez de unir Product Inventory tabelas e em cada solicitação, mantenha uma Product Catalog tabela consolidada que contenha os dados necessários. Pricing Os benefícios dessa abordagem podem superar os custos da tabela adicional.
Considere um cenário em queProduct,Price, e Inventory os serviços frequentemente precisam de informações sobre o produto. Em vez de configurar esses serviços para acessar diretamente as tabelas compartilhadas, crie um Product Catalog serviço dedicado. Esse serviço mantém seu próprio banco de dados que contém as informações consolidadas do produto. Ele atua como uma única fonte confiável para consultas relacionadas a produtos. Quando os detalhes do produto, os preços ou os níveis de estoque mudam, os respectivos serviços podem publicar eventos para atualizar o Product Catalog serviço. Isso fornece consistência de dados e, ao mesmo tempo, mantém a independência do serviço. A imagem a seguir mostra essa configuração, na qual a Amazon EventBridge
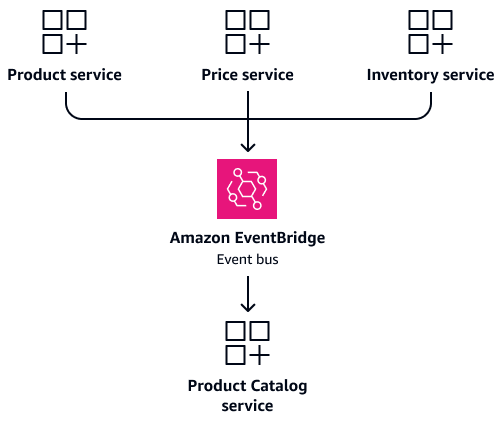
Conforme discutido na próxima seçãoSincronização de dados baseada em eventos, mantenha o modelo CQRS atualizado por meio de eventos. Quando os detalhes do produto, os preços ou os níveis de estoque mudam, os respectivos serviços publicam eventos. O Product Catalog serviço se inscreve nesses eventos e atualiza sua visão consolidada. Isso fornece leituras rápidas sem junções complexas e mantém a independência do serviço.
Sincronização de dados baseada em eventos
A sincronização de dados baseada em eventos é um padrão em que as alterações nos dados são capturadas e propagadas como eventos, o que permite que diferentes sistemas ou componentes mantenham estados de dados sincronizados. Quando os dados mudarem, em vez de atualizar todos os bancos de dados relacionados imediatamente, publique um evento para notificar os serviços assinados. Por exemplo, quando um cliente altera seu endereço de entrega no Customer serviço, um CustomerUpdated evento inicia atualizações no Order serviço e no Delivery serviço de acordo com a programação de cada serviço. Essa abordagem substitui as uniões rígidas de tabelas por atualizações flexíveis e escaláveis orientadas por eventos. Alguns serviços podem ter dados desatualizados por um breve período, mas a desvantagem é melhorar a escalabilidade do sistema e a independência do serviço.
Implementando alternativas às junções de tabelas
Comece a decomposição do banco de dados com operações de leitura, pois elas geralmente são mais simples de migrar e validar. Depois que os caminhos de leitura estiverem estáveis, realize as operações de gravação mais complexas. Para requisitos críticos de alto desempenho, considere implementar o padrão CQRS. Use um banco de dados separado e otimizado para leituras e mantenha outro para gravações.
Crie sistemas resilientes adicionando lógica de repetição para chamadas entre serviços e implementando camadas de cache apropriadas. Monitore de perto as interações de serviço e configure alertas para problemas de consistência de dados. O objetivo final não é a consistência perfeita em todos os lugares — é criar serviços independentes que tenham um bom desempenho e, ao mesmo tempo, mantenham uma precisão de dados aceitável para suas necessidades comerciais.
A natureza desacoplada dos microsserviços introduz as seguintes novas complexidades no gerenciamento de dados:
-
Os dados são distribuídos. Os dados agora residem em bancos de dados separados, que são gerenciados por serviços independentes.
-
A sincronização em tempo real entre serviços geralmente é impraticável, exigindo um modelo de consistência eventual.
-
As operações que antes ocorriam em uma única transação de banco de dados agora abrangem vários serviços.
Para enfrentar esses desafios, faça o seguinte:
-
Implemente uma arquitetura orientada por eventos — use filas de mensagens e publicação de eventos para propagar as alterações de dados entre os serviços. Para obter mais informações, consulte Criação de arquiteturas orientadas a eventos em terrenos
sem servidor. -
Adote o padrão de orquestração da saga — Esse padrão ajuda você a gerenciar transações distribuídas e manter a integridade dos dados em todos os serviços. Para obter mais informações, consulte Criação de um aplicativo distribuído sem servidor usando um padrão de orquestração de saga
em blogs. AWS -
Projete para falhas — incorpore mecanismos de repetição, disjuntores e transações de compensação para lidar com problemas de rede ou falhas de serviço.
-
Use o carimbo de versão — Acompanhe as versões de dados para gerenciar conflitos e garantir que as atualizações mais recentes sejam aplicadas.
-
Reconciliação regular — implemente processos periódicos de sincronização de dados para capturar e corrigir quaisquer inconsistências.
Exemplo baseado em cenários
O exemplo de esquema a seguir tem duas tabelas, uma Customer tabela e uma Order tabela:
-- Customer table CREATE TABLE customer ( customer_id INT PRIMARY KEY, first_name VARCHAR(100), last_name VARCHAR(100), email VARCHAR(255), phone VARCHAR(20), address TEXT, created_at TIMESTAMP ); -- Order table CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50), FOREIGN KEY (customer_id) REFERENCES customers(id) );
Veja a seguir um exemplo de como você pode usar uma abordagem desnormalizada:
CREATE TABLE order ( order_id INT PRIMARY KEY, customer_id INT, -- Reference only customer_first_name VARCHAR(100), -- Denormalized customer_last_name VARCHAR(100), -- Denormalized customer_email VARCHAR(255), -- Denormalized order_date TIMESTAMP, total_amount DECIMAL(10,2), status VARCHAR(50) );
A nova Order tabela tem o nome do cliente e os endereços de e-mail que estão desnormalizados. O customer_id é referenciado e não há nenhuma restrição de chave estrangeira com a Customer tabela. A seguir estão os benefícios dessa abordagem desnormalizada:
-
O
Orderserviço pode exibir o histórico de pedidos com detalhes do cliente e não exige chamadas de API para oCustomermicrosserviço. -
Se o
Customerserviço estiver inativo, eleOrderpermanecerá totalmente funcional. -
As consultas para processamento e geração de relatórios de pedidos são executadas mais rapidamente.
O diagrama a seguir mostra um aplicativo monolítico que recupera dados de pedidos usandogetOrder(customer_id), getOrder(order_id)getCustomerOders(customer_id), e chamadas de createOrder(Order
order) API para o microsserviço. Order
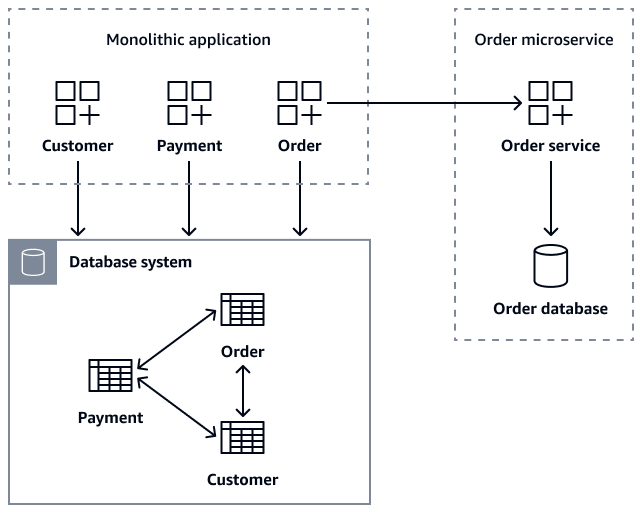
Durante a migração de microsserviços, você pode manter a Order tabela no banco de dados monolítico como uma medida de segurança transitória, garantindo que o aplicativo legado permaneça funcional. No entanto, é fundamental que todas as novas operações relacionadas a pedidos sejam roteadas por meio da API de Order microsserviços, que mantém seu próprio banco de dados e, ao mesmo tempo, grava no banco de dados legado como backup. Esse padrão de gravação dupla fornece uma rede de segurança. Ele permite a migração gradual enquanto mantém a estabilidade do sistema. Depois que todos os clientes tiverem migrado com sucesso para o novo microsserviço, você poderá descontinuar a Order tabela legada no banco de dados monolítico. Depois de decompor o aplicativo monolítico e seu banco de dados em Order microsserviços separadosCustomer, manter a consistência dos dados se torna o principal desafio.
