As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Analisando a coesão e o acoplamento para decomposição do banco de dados
Esta seção ajuda você a analisar os padrões de acoplamento e coesão em seu banco de dados monolítico para orientar sua decomposição. Entender como os componentes do banco de dados interagem e dependem uns dos outros é crucial para identificar pontos de interrupção naturais, avaliar a complexidade e planejar uma abordagem de migração em fases. Essa análise revela dependências ocultas, destaca áreas que são adequadas para separação imediata e ajuda a priorizar os esforços de decomposição e, ao mesmo tempo, minimizar os riscos de transformação. Ao examinar o acoplamento e a coesão, você pode tomar decisões informadas sobre a sequência de separação dos componentes para manter a estabilidade do sistema durante todo o processo de transformação.
Esta seção contém os seguintes tópicos:
Sobre coesão e acoplamento
O acoplamento mede o grau de interdependência entre os componentes do banco de dados. Em um sistema bem projetado, você deseja obter um acoplamento frouxo, em que as alterações em um componente tenham um impacto mínimo sobre os outros. A coesão mede o quão bem os elementos dentro de um componente de banco de dados trabalham juntos para servir a um propósito único e bem definido. A alta coesão indica que os elementos de um componente estão fortemente relacionados e focados em uma função específica. Ao decompor um banco de dados monolítico, você deve analisar a coesão dentro dos componentes individuais e o acoplamento entre eles. Essa análise ajuda você a tomar decisões informadas sobre como detalhar o banco de dados e, ao mesmo tempo, manter a integridade e o desempenho do sistema.
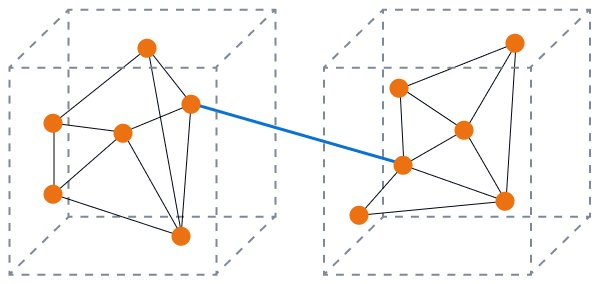
A imagem a seguir mostra um acoplamento solto com alta coesão. Os componentes do banco de dados trabalham juntos para executar uma função específica e você minimiza o impacto da alteração em um único componente. Esse é o estado ideal.
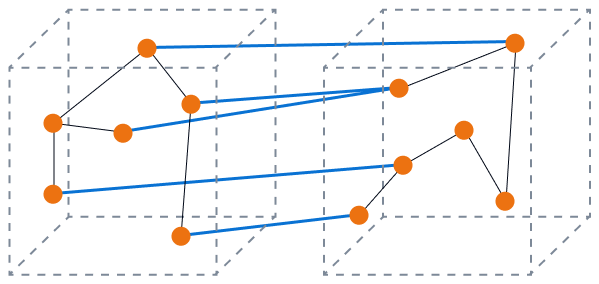
A imagem a seguir mostra alto acoplamento com baixa coesão. Os componentes do banco de dados estão desconectados e é altamente provável que as alterações afetem outros componentes.
Padrões de acoplamento comuns em bancos de dados monolíticos
Há vários padrões de acoplamento que são comumente encontrados ao decompor um banco de dados monolítico em bancos de dados específicos de microsserviços. Compreender esses padrões é crucial para iniciativas bem-sucedidas de modernização do banco de dados. Esta seção descreve cada padrão, seus desafios e as melhores práticas para reduzir o acoplamento.
Padrão de acoplamento de implementação
Definição: Os componentes estão fortemente interconectados no nível do código e do esquema. Por exemplo, modificar a estrutura de uma customer tabela orderinventory, impactos e billing serviços.
Impacto da modernização: cada microsserviço exige seu próprio esquema de banco de dados dedicado e camada de acesso a dados.
Desafios:
-
Alterações nas tabelas compartilhadas afetam vários serviços
-
Alto risco de efeitos colaterais não intencionais
-
Aumento da complexidade dos testes
-
Difícil modificar componentes individuais
Melhores práticas para reduzir o acoplamento:
-
Defina interfaces claras entre os componentes
-
Use camadas de abstração para ocultar detalhes de implementação
-
Implemente esquemas específicos de domínio
Padrão de acoplamento temporal
Definição: As operações devem ser executadas em uma sequência específica. Por exemplo, o processamento de pedidos não pode continuar até que as atualizações de estoque sejam concluídas.
Impacto da modernização: cada microsserviço precisa de controle autônomo de dados.
Desafios:
-
Quebrando dependências síncronas entre serviços
-
Gargalos de desempenho
-
Difícil de otimizar
-
Processamento paralelo limitado
Melhores práticas para reduzir o acoplamento:
-
Implemente o processamento assíncrono sempre que possível
-
Use arquiteturas orientadas por eventos
-
Projete para uma eventual consistência quando apropriado
Padrão de acoplamento de implantação
Definição: Os componentes do sistema devem ser implantados como uma única unidade. Por exemplo, uma pequena alteração na lógica de processamento de pagamentos exige a reimplantação de todo o banco de dados.
Impacto da modernização: implantações independentes de banco de dados por serviço
Desafios:
-
Implantações de alto risco
-
Frequência de implantação limitada
-
Procedimentos complexos de reversão
Melhores práticas para reduzir o acoplamento:
-
Divida em componentes que podem ser implantados de forma independente
-
Implemente estratégias de fragmentação de banco de dados
-
Use padrões de implantação azul-esverdeados
Padrão de acoplamento de domínio
Definição: Os domínios de negócios compartilham estruturas e lógica de banco de dados. Por exemplo, os inventory domínios customerorder, e compartilham tabelas e procedimentos armazenados.
Impacto da modernização: isolamento de dados específico do domínio
Desafios:
-
Limites de domínio complexos
-
Difícil escalar domínios individuais
-
Regras de negócios confusas
Melhores práticas para reduzir o acoplamento:
-
Identifique limites claros de domínio
-
Dados separados por contexto de domínio
-
Implemente serviços específicos de domínio
Padrões de coesão comuns em bancos de dados monolíticos
Há vários padrões de coesão que são comumente encontrados ao avaliar componentes do banco de dados para decomposição. Compreender esses padrões é crucial para identificar componentes de banco de dados bem estruturados. Esta seção descreve cada padrão, suas características e as melhores práticas para fortalecer a coesão.
Padrão de coesão funcional
Definição: Todos os elementos apoiam e contribuem diretamente para a execução de uma função única e bem definida. Por exemplo, todos os procedimentos e tabelas armazenados em um módulo de processamento de pagamentos tratam somente de operações relacionadas a pagamentos.
Impacto da modernização: padrão ideal para design de banco de dados de microsserviços
Desafios:
-
Identificação de limites funcionais claros
-
Separação de componentes de uso misto
-
Manter uma responsabilidade única
Melhores práticas para fortalecer a coesão:
-
Agrupe funções relacionadas
-
Remover funcionalidades não relacionadas
-
Defina limites claros dos componentes
Padrão de coesão sequencial
Definição: A saída de um elemento se torna entrada para outro. Por exemplo, os resultados da validação de um pedido são inseridos no processamento do pedido.
Impacto da modernização: requer análise cuidadosa do fluxo de trabalho e mapeamento do fluxo de dados
Desafios:
-
Gerenciando dependências entre etapas
-
Lidando com cenários de falha
-
Mantendo a ordem do processo
Melhores práticas para fortalecer a coesão:
-
Documente fluxos de dados claros
-
Implemente o tratamento adequado de erros
-
Crie interfaces claras entre as etapas
Padrão de coesão comunicacional
Definição: Os elementos operam com os mesmos dados. Por exemplo, todas as funções de gerenciamento do perfil do cliente funcionam com dados do cliente.
Impacto da modernização: ajuda a identificar limites de dados para separação de serviços a fim de diminuir o acoplamento entre os módulos
Desafios:
-
Determinando a propriedade dos dados
-
Gerenciando o acesso a dados compartilhados
-
Mantendo a consistência dos dados
Melhores práticas para fortalecer a coesão:
-
Defina uma propriedade clara dos dados
-
Implemente padrões adequados de acesso aos dados
-
Projete um particionamento de dados eficaz
Padrão de coesão processual
Definição: Os elementos são agrupados porque devem ser executados em uma ordem específica, mas podem não estar relacionados funcionalmente. Por exemplo, no processamento de pedidos, um procedimento armazenado que manipula a validação do pedido e a notificação do usuário é agrupado simplesmente porque eles acontecem em sequência, mesmo que tenham finalidades diferentes e possam ser tratados por serviços separados.
Impacto da modernização: exige uma separação cuidadosa dos procedimentos, mantendo o fluxo do processo
Desafios:
-
Manter o fluxo correto do processo após a decomposição
-
Identificação de limites funcionais reais em comparação com dependências processuais
Melhores práticas para fortalecer a coesão:
-
Procedimentos separados com base em sua finalidade funcional e não na ordem de execução
-
Use padrões de orquestração para gerenciar o fluxo do processo
-
Implemente sistemas de gerenciamento de fluxo de trabalho para sequências complexas
-
Projete arquiteturas orientadas a eventos para lidar com as etapas do processo de forma independente
Padrão de coesão temporal
Definição: Os elementos são relacionados por requisitos de tempo. Por exemplo, quando um pedido é feito, várias operações devem ser executadas em conjunto: verificação de estoque, processamento de pagamentos, confirmação do pedido e notificação de envio devem ocorrer dentro de uma janela de tempo específica para manter um estado consistente do pedido.
Impacto da modernização: pode exigir tratamento especial em sistemas distribuídos
Desafios:
-
Coordenando dependências de tempo em serviços distribuídos
-
Gerenciando transações distribuídas
-
Confirmando a conclusão do processo em vários componentes
Melhores práticas para fortalecer a coesão:
-
Implemente mecanismos de agendamento e tempos limite adequados
-
Use arquiteturas orientadas por eventos com tratamento claro de sequências
-
Design para uma eventual consistência com padrões de compensação
-
Implemente padrões de saga para transações distribuídas
Padrão de coesão lógico ou coincidente
Definição: Os elementos são categorizados logicamente para fazer as mesmas coisas, mesmo que tenham relacionamentos fracos ou nenhum relacionamento significativo. Um exemplo é armazenar dados de pedidos de clientes, contagens de estoque de armazéns e modelos de e-mail de marketing no mesmo esquema de banco de dados, pois todos estão relacionados às operações de vendas, apesar de terem padrões de acesso, gerenciamento do ciclo de vida e requisitos de escalabilidade diferentes. Outro exemplo é combinar o processamento do pagamento de pedidos e o gerenciamento do catálogo de produtos no mesmo componente do banco de dados, pois ambos fazem parte do sistema de comércio eletrônico, embora atendam a funções comerciais distintas com necessidades operacionais diferentes.
Impacto da modernização: deve ser refatorado ou reorganizado
Desafios:
-
Identificando melhores padrões organizacionais
-
Quebrando dependências desnecessárias
-
Componentes de reestruturação que foram agrupados arbitrariamente
Melhores práticas para fortalecer a coesão:
-
Reorganize com base em verdadeiros limites funcionais e domínios de negócios
-
Remova agrupamentos arbitrários com base em relacionamentos superficiais
-
Implemente a separação adequada dos elementos com base nos recursos de negócios
-
Alinhe os componentes do banco de dados com seus requisitos operacionais específicos
Implementando baixo acoplamento e alta coesão
Práticas recomendadas
As práticas recomendadas a seguir podem ajudá-lo a obter um baixo acoplamento:
-
Minimize as dependências entre os componentes do banco de dados
-
Use interfaces bem definidas para interação de componentes
-
Evite estruturas de dados globais e estaduais compartilhadas
As melhores práticas a seguir podem ajudar você a alcançar uma alta coesão:
-
Agrupe dados e operações relacionados
-
Certifique-se de que cada componente tenha uma responsabilidade única e clara
-
Mantenha limites claros entre diferentes domínios de negócios
Fase 1: Mapear dependências de dados
Mapeie relacionamentos de dados e identifique limites naturais. Você pode usar ferramentas, como SchemaSpy
Você também pode exportar seus esquemas de banco de dados em um banco de dados gráfico ou em um Jupiter notebook. Em seguida, você pode aplicar algoritmos de agrupamento ou componentes interconectados para identificar limites e dependências naturais. Outras AWS Partner ferramentas, como CAST Imaging
Fase 2: Analise os limites das transações e os padrões de acesso
Analise os padrões de transação para manter as propriedades de atomicidade, consistência, isolamento e durabilidade (ACID) e entender como os dados são acessados e modificados. Você pode usar ferramentas de análise e diagnóstico de banco de dados, como Oracle Automatic Workload Repository (AWR)
Ferramentas de IA, como vFunction
Fase 3: Identificar tabelas independentes
Procure tabelas que demonstrem duas características principais:
-
Alta coesão — Os conteúdos da tabela estão fortemente relacionados entre si
-
Baixo acoplamento — Eles têm dependências mínimas em outras tabelas.
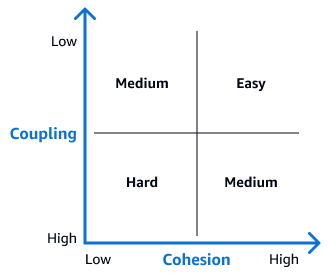
A seguinte matriz de acoplamento e coesão pode ajudá-lo a identificar a dificuldade de desacoplar cada tabela. As tabelas que aparecem no quadrante superior direito dessa matriz são candidatas ideais para os esforços iniciais de desacoplamento, pois são as mais fáceis de separar. Em um diagrama ER, essas tabelas têm poucos relacionamentos de chave estrangeira ou outras dependências. Depois de desacoplar essas tabelas, avance para tabelas com relacionamentos mais complexos.
nota
A estrutura do banco de dados geralmente reflete a arquitetura do aplicativo. Tabelas que são mais fáceis de desacoplar no nível do banco de dados normalmente correspondem a componentes que são mais fáceis de converter em microsserviços no nível do aplicativo.
