As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Migração local
A migração local elimina a necessidade de reescrever todos os seus arquivos de dados. Em vez disso, os arquivos de metadados do Iceberg são gerados e vinculados aos seus arquivos de dados existentes. Esse método geralmente é mais rápido e econômico, especialmente para grandes conjuntos de dados ou tabelas com formatos de arquivo compatíveis, como Parquet, Avro e ORC.
nota
A migração local não pode ser usada ao migrar para as tabelas do Amazon S3.
O Iceberg oferece duas opções principais para implementar a migração local:
-
Usando o procedimento de captura instantânea
para criar uma nova tabela Iceberg, mantendo a tabela de origem inalterada. Para obter mais informações, consulte Tabela de instantâneos na documentação do Iceberg. -
Usando o procedimento de migração
para criar uma nova tabela Iceberg em substituição à tabela de origem. Para obter mais informações, consulte Migrate Table na documentação do Iceberg. Embora esse procedimento funcione com o Hive Metastore (HMS), atualmente não é compatível com o. AWS Glue Data Catalog O procedimento de replicação da migração da tabela na AWS Glue Data Catalog seção posterior deste guia fornece uma solução alternativa para obter um resultado semelhante com o Catálogo de Dados.
Depois de realizar a migração local usando um snapshot oumigrate, alguns arquivos de dados podem permanecer sem migração. Isso geralmente acontece quando os gravadores continuam gravando na tabela de origem durante ou após a migração. Para incorporar esses arquivos restantes em sua tabela Iceberg, você pode usar o procedimento add_files
Digamos que você tenha uma products tabela baseada em Parquet que foi criada e preenchida no Athena da seguinte forma:
CREATE EXTERNAL TABLE mydb.products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; INSERT INTO mydb.products VALUES (1001, 'Smartphone', 'electronics'), (1002, 'Laptop', 'electronics'), (2001, 'T-Shirt', 'clothing'), (2002, 'Jeans', 'clothing');
As seções a seguir explicam como você pode usar os migrate procedimentos snapshot e com essa tabela.
Opção 1: procedimento de captura instantânea
O snapshot procedimento cria uma nova tabela Iceberg que tem um nome diferente, mas replica o esquema e o particionamento da tabela de origem. Essa operação deixa a tabela de origem completamente inalterada durante e após a ação. Ele cria efetivamente uma cópia leve da tabela, o que é particularmente útil para testar cenários ou explorar dados sem correr o risco de modificações na fonte de dados original. Essa abordagem permite um período de transição em que a tabela original e a tabela Iceberg permanecem disponíveis (consulte as notas no final desta seção). Quando o teste estiver concluído, você poderá mover sua nova tabela Iceberg para produção fazendo a transição de todos os escritores e leitores para a nova tabela.
Você pode executar o snapshot procedimento usando o Spark em qualquer modelo de implantação do Amazon EMR (por exemplo, Amazon EMR no EC2, Amazon EMR no EKS, EMR Serverless) e. AWS Glue
Para testar a migração local com o procedimento do snapshot Spark, siga estas etapas:
-
Inicie um aplicativo Spark e configure a sessão do Spark com as seguintes configurações:
-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Execute o
snapshotprocedimento para criar uma nova tabela Iceberg que aponte para os arquivos de dados da tabela original:spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False)O quadro de dados de saída contém o
imported_files_count(o número de arquivos que foram adicionados). -
Valide a nova tabela consultando-a:
spark.sql(f""" SELECT * FROM mydb.products_iceberg LIMIT 10 """ ).show(truncate=False)
Observações
-
Depois de executar o procedimento, qualquer modificação no arquivo de dados na tabela de origem dessincronizará a tabela gerada. Os novos arquivos que você adicionar não estarão visíveis na tabela Iceberg, e os arquivos que você removeu afetarão os recursos de consulta na tabela Iceberg. Para evitar os problemas de sincronização:
-
Se a nova tabela Iceberg for destinada ao uso em produção, interrompa todos os processos gravados na tabela original e redirecione-os para a nova tabela.
-
Se você precisar de um período de transição ou se a nova tabela do Iceberg for para fins de teste, consulte Mantendo as tabelas do Iceberg sincronizadas após a migração local, mais adiante nesta seção, para obter orientação sobre como manter a sincronização das tabelas.
-
-
Quando você usa o
snapshotprocedimento, agc.enabledpropriedade é definidafalsenas propriedades da tabela Iceberg criada. Essa configuração proíbe ações comoexpire_snapshotsremove_orphan_files, ouDROP TABLEcom aPURGEopção, que excluiriam fisicamente os arquivos de dados. As operações de exclusão ou mesclagem do Iceberg, que não afetam diretamente os arquivos de origem, ainda são permitidas. -
Para tornar sua nova tabela Iceberg totalmente funcional, sem limites nas ações que excluem fisicamente os arquivos de dados, você pode alterar a propriedade da
gc.enabledtabela paratrue. No entanto, essa configuração permitirá ações que afetem os arquivos de dados de origem, o que pode corromper o acesso à tabela original. Portanto, altere agc.enabledpropriedade somente se você não precisar mais manter a funcionalidade da tabela original. Por exemplo:spark.sql(f""" ALTER TABLE mydb.products_iceberg SET TBLPROPERTIES ('gc.enabled' = 'true'); """)
Opção 2: procedimento de migração
O migrate procedimento cria uma nova tabela Iceberg que tem o mesmo nome, esquema e particionamento da tabela de origem. Quando esse procedimento é executado, ele bloqueia a tabela de origem e a renomeia para <table_name>_BACKUP_ (ou um nome personalizado especificado pelo parâmetro do backup_table_name procedimento).
nota
Se você definir o parâmetro do drop_backup procedimento comotrue, a tabela original não será mantida como backup.
Consequentemente, o procedimento da migrate tabela exige que todas as modificações que afetam a tabela de origem sejam interrompidas antes que a ação seja executada. Antes de executar o migrate procedimento:
-
Pare todos os escritores que interagem com a tabela de origem.
-
Modifique leitores e escritores que não oferecem suporte nativo ao Iceberg para ativar o suporte ao Iceberg.
Por exemplo:
-
Athena continua trabalhando sem modificações.
-
O Spark requer:
-
Arquivos Iceberg Java Archive (JAR) a serem incluídos no classpath (consulte Trabalhando com o Iceberg no Amazon EMR e Trabalhando com o Iceberg nas seções anteriores deste guia). AWS Glue
-
As seguintes configurações do catálogo de sessões do Spark (usadas
SparkSessionCatalogpara adicionar suporte ao Iceberg e, ao mesmo tempo, manter as funcionalidades integradas do catálogo para tabelas que não são do Iceberg):-
"spark.sql.extensions":"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" -
"spark.sql.catalog.spark_catalog":"org.apache.iceberg.spark.SparkSessionCatalog" -
"spark.sql.catalog.spark_catalog.type":"glue" -
"spark.hadoop.hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
-
-
Depois de executar o procedimento, você pode reiniciar seus gravadores com a nova configuração do Iceberg.
Atualmente, o migrate procedimento não é compatível com o AWS Glue Data Catalog, porque o Catálogo de Dados não suporta a RENAME operação. Portanto, recomendamos que você use esse procedimento somente quando estiver trabalhando com o Hive Metastore. Se você estiver usando o Catálogo de Dados, consulte a próxima seção para obter uma abordagem alternativa.
Você pode executar o migrate procedimento em todos os modelos de implantação do Amazon EMR (Amazon EMR no EC2, Amazon EMR no EKS, EMR Serverless), mas isso requer uma conexão configurada com o Hive Metastore. AWS Glue O Amazon EMR no EC2 é a opção recomendada porque fornece uma configuração integrada do Hive Metastore, o que minimiza a complexidade da configuração.
Para testar a migração local com o procedimento migrate Spark de um cluster do Amazon EMR no EC2 configurado com o Hive Metastore, siga estas etapas:
-
Inicie um aplicativo Spark e configure a sessão do Spark para usar a implementação do catálogo Iceberg Hive. Por exemplo, se você estiver usando a
pysparkCLI:pyspark --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive -
Crie uma
productstabela no Hive Metastore. Essa é a tabela de origem, que já existe em uma migração típica.-
Crie a tabela
productsexterna do Hive no Hive Metastore para apontar para os dados existentes no Amazon S3:spark.sql(f""" CREATE EXTERNAL TABLE products ( product_id INT, product_name STRING ) PARTITIONED BY (category STRING) STORED AS PARQUET LOCATION 's3://amzn-s3-demo-bucket/products/'; """ ) -
Adicione as partições existentes usando o
MSCK REPAIR TABLEcomando:spark.sql(f""" MSCK REPAIR TABLE products """ ) -
Confirme se a tabela contém dados executando uma
SELECTconsulta:spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)Exemplo de saída:

-
-
Use o
migrateprocedimento Iceberg:df_res=spark.sql(f""" CALL system.migrate( table => 'default.products' ) """ ) df_res.show()O quadro de dados de saída contém
migrated_files_count(os números de arquivos que foram adicionados à tabela Iceberg):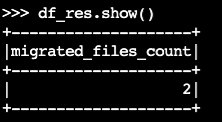
-
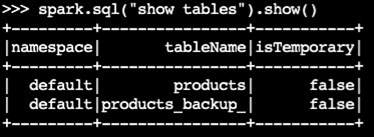
Confirme se a tabela de backup foi criada:
spark.sql("show tables").show()Exemplo de saída:
-
Valide a operação consultando a tabela Iceberg:
spark.sql(f""" SELECT * FROM products """ ).show(truncate=False)
Observações
-
Depois de executar o procedimento, todos os processos atuais que consultam ou gravam na tabela de origem serão afetados se não estiverem configurados corretamente com o suporte do Iceberg. Portanto, recomendamos que você siga estas etapas:
-
Pare todos os processos usando a tabela de origem antes da migração.
-
Execute a migração.
-
Reative os processos usando as configurações adequadas do Iceberg.
-
-
Se ocorrerem modificações no arquivo de dados durante o processo de migração (novos arquivos forem adicionados ou removidos), a tabela gerada ficará fora de sincronia. Para opções de sincronização, consulte Mantendo as tabelas do Iceberg sincronizadas após a migração local, mais adiante nesta seção.
Replicando o procedimento de migração de tabelas no AWS Glue Data Catalog
Você pode replicar o resultado do procedimento de migração em AWS Glue Data Catalog (fazendo backup da tabela original e substituindo-a por uma tabela Iceberg) seguindo estas etapas:
-
Use o procedimento de captura instantânea para criar uma nova tabela Iceberg que aponta para os arquivos de dados da tabela original.
-
Faça backup dos metadados da tabela original no Catálogo de Dados:
-
Use a GetTableAPI para recuperar a definição da tabela de origem.
-
Use a GetPartitionsAPI para recuperar a definição da partição da tabela de origem.
-
Use a CreateTableAPI para criar uma tabela de backup no catálogo de dados.
-
Use a BatchCreatePartitionAPI CreatePartitionor para registrar partições na tabela de backup no Catálogo de Dados.
-
-
Altere a propriedade da tabela
gc.enabledIcebergfalsepara ativar as operações completas da tabela. -
Descarte a tabela original.
-
Localize o arquivo JSON de metadados da tabela Iceberg na pasta de metadados da localização raiz da tabela.
-
Registre a nova tabela no Catálogo de Dados usando o procedimento register_table
com o nome da tabela original e a localização do metadata.jsonarquivo que foi criado pelo procedimento:snapshotspark.sql(f""" CALL system.register_table( table => 'mydb.products', metadata_file => '{iceberg_metadata_file}' ) """ ).show(truncate=False)
Mantendo as tabelas do Iceberg sincronizadas após a migração local
O add_files procedimento fornece uma maneira flexível de incorporar dados existentes às tabelas do Iceberg. Especificamente, ele registra arquivos de dados existentes (como arquivos Parquet) referenciando seus caminhos absolutos na camada de metadados do Iceberg. Por padrão, o procedimento adiciona arquivos de todas as partições da tabela a uma tabela Iceberg, mas você pode adicionar seletivamente arquivos de partições específicas. Essa abordagem seletiva é particularmente útil em vários cenários:
-
Quando novas partições são adicionadas à tabela de origem após a migração inicial.
-
Quando os arquivos de dados são adicionados ou removidos das partições existentes após a migração inicial. No entanto, adicionar novamente partições modificadas exige primeiro a exclusão da partição. Mais informações sobre isso são fornecidas posteriormente nesta seção.
Aqui estão algumas considerações sobre o uso do add_file procedimento após a realização da migração local (snapshotoumigrate), para manter a nova tabela Iceberg sincronizada com os arquivos de dados de origem:
-
Quando novos dados forem adicionados a novas partições na tabela de origem, use o
add_filesprocedimento com apartition_filteropção de incorporar seletivamente essas adições na tabela Iceberg:spark.sql(f""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False)ou:
spark.sql(f""" CALL system.add_files( source_table => '`parquet`.`s3://amzn-s3-demo-bucket/products/`', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ).show(truncate=False) -
O
add_filesprocedimento verifica arquivos em toda a tabela de origem ou em partições específicas quando você especifica apartition_filteropção e tenta adicionar todos os arquivos encontrados à tabela Iceberg. Por padrão, a propriedade docheck_duplicate_filesprocedimento é definida comotrue, o que impede a execução do procedimento se os arquivos já existirem na tabela Iceberg. Isso é importante porque não há uma opção integrada para ignorar arquivos adicionados anteriormente, e a desativaçãocheck_duplicate_filesfará com que os arquivos sejam adicionados duas vezes, criando duplicatas. Quando novos arquivos forem adicionados à tabela de origem, siga estas etapas:-
Para novas partições, use
add_filescom apartition_filterpara importar somente arquivos da nova partição. -
Para partições existentes, primeiro exclua a partição da tabela Iceberg e, em seguida, execute novamente
add_filesessa partição, especificando o.partition_filterPor exemplo:# We initially perform in-place migration with snapshot spark.sql(f""" CALL system.snapshot( source_table => 'mydb.products', table => 'mydb.products_iceberg', location => 's3://amzn-s3-demo-bucket/products_iceberg/' ) """ ).show(truncate=False) # Then on the source table, some new files were generated under the category='electronics' partition. Example: spark.sql(""" INSERT INTO mydb.products VALUES (1003, 'Tablet', 'electronics') """) # We delete the modified partition from the Iceberg table. Note this is a metadata operation only spark.sql(""" DELETE FROM mydb.products_iceberg WHERE category = 'electronics' """) # We add_files from the modified partition spark.sql(""" CALL system.add_files( source_table => 'mydb.products', table => 'mydb.products_iceberg', partition_filter => map('category', 'electronics') ) """).show(truncate=False)
-
nota
Cada add_files operação gera um novo instantâneo da tabela Iceberg com dados anexados.
Escolhendo a estratégia certa de migração local
Para escolher a melhor estratégia de migração local, considere as perguntas na tabela a seguir.
Pergunta |
Recomendação |
Explicação |
|---|---|---|
Você quer migrar rapidamente sem reescrever dados e, ao mesmo tempo, manter as tabelas Hive e Iceberg acessíveis para testes ou transições graduais? |
|
Use o |
Você está usando o Hive Metastore e deseja substituir sua tabela do Hive por uma tabela Iceberg imediatamente, sem reescrever os dados? |
|
Use o Observação: essa opção é compatível com o Hive Metastore, mas não com o. AWS Glue Data Catalog Use o |
Você está usando AWS Glue Data Catalog e deseja substituir sua tabela Hive por uma tabela Iceberg imediatamente, sem reescrever os dados? |
Adaptação do |
Replique o comportamento
Observação: essa opção exige o tratamento manual de chamadas de AWS Glue API para backup de metadados. Use o |
