As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Lagos de dados modernos
Casos de uso avançados em lagos de dados modernos
A evolução do armazenamento de dados progrediu de bancos de dados para armazéns de dados e lagos de dados, onde cada tecnologia atende aos requisitos exclusivos de negócios e dados. Os bancos de dados tradicionais se destacaram no tratamento de dados estruturados e cargas de trabalho transacionais, mas enfrentaram desafios de desempenho à medida que os volumes de dados aumentavam. Os data warehouses surgiram para resolver problemas de desempenho e escalabilidade, mas, assim como os bancos de dados, eles dependiam de formatos proprietários em sistemas integrados verticalmente.
Os data lakes oferecem uma das melhores opções para armazenar dados em termos de custo, escalabilidade e flexibilidade. Você pode usar um data lake para reter grandes volumes de dados estruturados e não estruturados a um custo baixo e usar esses dados para diferentes tipos de cargas de trabalho de análise, desde relatórios de business intelligence até processamento de big data, análises em tempo real, aprendizado de máquina e inteligência artificial generativa (IA), para ajudar a orientar melhores decisões.
Apesar desses benefícios, os data lakes não foram projetados inicialmente com recursos semelhantes aos de bancos de dados. Um data lake não fornece suporte para semântica de processamento de atomicidade, consistência, isolamento e durabilidade (ACID), que você pode precisar para otimizar e gerenciar seus dados de forma eficaz em escala para centenas ou milhares de usuários usando muitas tecnologias diferentes. Os data lakes não fornecem suporte nativo para as seguintes funcionalidades:
-
Realizar atualizações e exclusões eficientes em nível de registro à medida que os dados mudam em sua empresa
-
Gerenciando o desempenho das consultas à medida que as tabelas crescem para milhões de arquivos e centenas de milhares de partições
-
Garantindo a consistência dos dados entre vários escritores e leitores simultâneos
-
Prevenir a corrupção de dados quando as operações de gravação falham no meio da operação
-
Esquemas de tabela em evolução ao longo do tempo sem reescrever (parcialmente) conjuntos de dados
Esses desafios se tornaram particularmente predominantes em casos de uso, como lidar com captura de dados alterados (CDC) ou casos de uso relacionados à privacidade, exclusão de dados e ingestão de dados por streaming, o que pode resultar em tabelas abaixo do ideal.
Os data lakes que usam as tabelas tradicionais no formato Hive oferecem suporte a operações de gravação somente para arquivos inteiros. Isso torna as atualizações e exclusões difíceis de implementar, demoradas e caras. Além disso, controles e garantias de concorrência oferecidos em sistemas compatíveis com ACID são necessários para garantir a integridade e a consistência dos dados.
Esses desafios deixam os usuários com um dilema: escolher entre uma plataforma totalmente integrada, mas proprietária, ou optar por um data lake autoconstruído, independente do fornecedor, mas com uso intensivo de recursos, que requer manutenção e migração constantes para obter seu valor potencial.
Introdução ao Apache Iceberg
O Apache Iceberg é um formato de tabela de código aberto que fornece recursos em tabelas de data lake que, historicamente, estavam disponíveis apenas em bancos de dados ou data warehouses. Ele foi projetado para oferecer escala e desempenho e é adequado para gerenciar tabelas com mais de centenas de gigabytes. Algumas das principais características das mesas Iceberg são:
-
Excluir, atualizar e mesclar.O Iceberg suporta comandos SQL padrão para armazenamento de dados para uso com tabelas de data lake.
-
Planejamento rápido de escaneamento e filtragem avançada. O Iceberg armazena metadados, como estatísticas em nível de partição e coluna, que podem ser usados pelos mecanismos para acelerar o planejamento e a execução de consultas.
-
Evolução completa do esquema. O Iceberg suporta adicionar, descartar, atualizar ou renomear colunas sem efeitos colaterais.
-
Evolução da partição. Você pode atualizar o layout da partição de uma tabela à medida que o volume de dados ou os padrões de consulta mudam. O Iceberg suporta a alteração das colunas nas quais uma tabela é particionada, a adição ou remoção de colunas de partições compostas.
-
Particionamento oculto.Esse recurso impede a leitura automática de partições desnecessárias. Isso elimina a necessidade de os usuários entenderem os detalhes de particionamento da tabela ou adicionarem filtros extras às consultas.
-
Reversão da versão. Os usuários podem corrigir problemas rapidamente voltando ao estado anterior à transação.
-
Viagem no tempo. Os usuários podem consultar uma versão anterior específica de uma tabela.
-
Isolamento serializável. As alterações na tabela são atômicas, então os leitores nunca veem alterações parciais ou não confirmadas.
-
Escritores simultâneos. O Iceberg usa simultaneidade otimista para permitir que várias transações sejam bem-sucedidas. Em caso de conflito, um dos redatores precisa repetir a transação.
-
Formatos de arquivo abertos. O Iceberg suporta vários formatos de arquivo de código aberto, incluindo Apache Parquet
, Apache Avro e Apache ORC .
Em resumo, os data lakes que usam o formato Iceberg se beneficiam da consistência transacional, da velocidade, da escala e da evolução do esquema. Para obter mais informações sobre esses e outros recursos do Iceberg, consulte a documentação do Apache Iceberg
AWS suporte para Apache Iceberg
O Apache Iceberg é suportado por Serviços da AWS empresas como Amazon EMR, Amazon
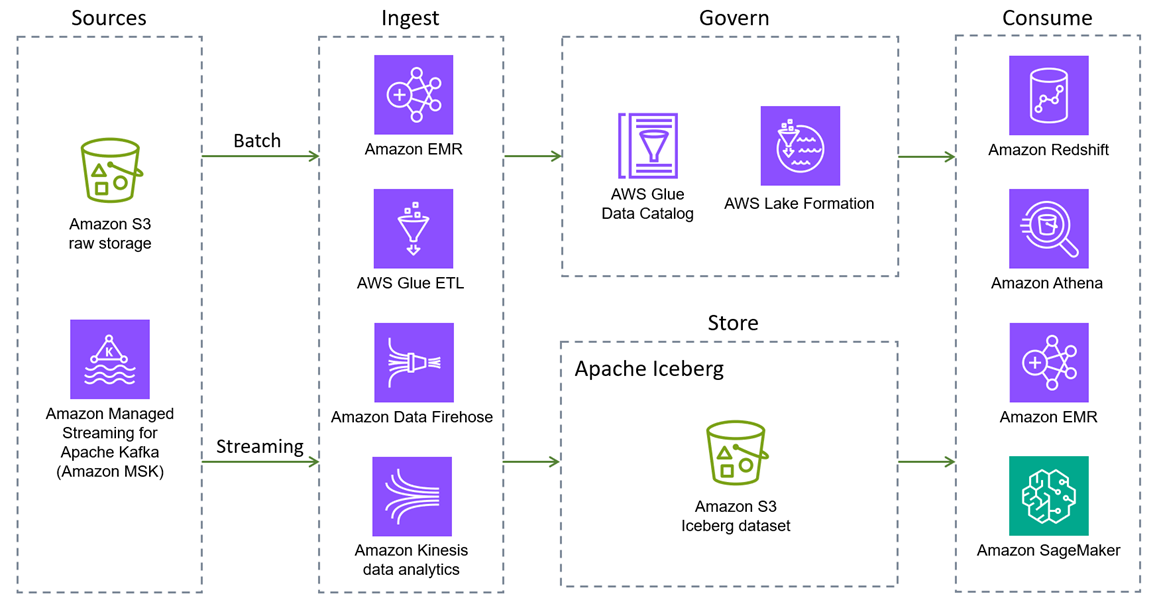
O seguinte Serviços da AWS fornece integrações nativas do Iceberg. Existem outros Serviços da AWS que podem interagir com o Iceberg, indiretamente ou empacotando as bibliotecas do Iceberg.
-
O Amazon S3 é o melhor lugar para criar lagos de dados devido à sua durabilidade, disponibilidade, escalabilidade, segurança, conformidade e recursos de auditoria. O Iceberg foi projetado e construído para interagir perfeitamente com o Amazon S3 e fornece suporte para muitos recursos do Amazon S3, conforme listado na documentação do Iceberg.
Além disso, as tabelas do Amazon S3 oferecem o primeiro armazenamento de objetos em nuvem com suporte integrado ao Iceberg e simplificam o armazenamento de dados tabulares em grande escala. Com o suporte do S3 Tables para o Iceberg, você pode consultar facilmente seus dados tabulares usando mecanismos de consulta populares AWS e de terceiros. -
A próxima geração do SageMaker
é baseada em uma arquitetura de lakehouse aberta que unifica o acesso aos dados em lagos de dados do Amazon S3, armazéns de dados do Amazon Redshift e fontes de dados federadas e terceirizadas. Esses recursos ajudam você a criar análises e AI/ML aplicativos poderosos em uma única cópia dos dados. O lakehouse é totalmente compatível com o Iceberg, então você tem a flexibilidade de acessar e consultar dados no local usando a API REST do Iceberg. -
O Amazon EMR é uma solução de big data para processamento de dados em escala de petabytes, análise interativa e aprendizado de máquina usando estruturas de código aberto, como Apache Spark, Flink, Trino e Hive. O Amazon EMR pode ser executado em clusters personalizados do Amazon Elastic Compute Cloud (Amazon EC2), no Amazon Elastic Kubernetes Service (Amazon EKS) AWS Outposts ou no Amazon EMR Serverless.
-
O Amazon Athena é um serviço de análise interativo e sem servidor baseado em estruturas de código aberto. Ele suporta formatos de tabela aberta e de arquivo e fornece uma maneira simplificada e flexível de analisar petabytes de dados onde eles estão. O Athena fornece suporte nativo para consultas de leitura, viagem no tempo, gravação e DDL para o Iceberg e usa o AWS Glue Data Catalog metastore for Iceberg.
-
O Amazon Redshift é um data warehouse em nuvem na escala de petabytes que oferece suporte a opções de implantação baseadas em cluster e sem servidor. O Amazon Redshift Spectrum pode consultar tabelas externas registradas e armazenadas no Amazon S3. AWS Glue Data Catalog O Redshift Spectrum também fornece suporte para o formato de armazenamento Iceberg.
-
AWS Glueé um serviço de integração de dados sem servidor que facilita a descoberta, a preparação, a movimentação e a integração de dados de várias fontes para análise, aprendizado de máquina (ML) e desenvolvimento de aplicativos. É totalmente integrado ao Iceberg. Especificamente, você pode realizar operações de leitura e gravação em tabelas do Iceberg usando AWS Glue trabalhos, gerenciar tabelas por meio do AWS Glue Data Catalog(compatível com a metástore do Hive), descobrir e registrar tabelas automaticamente usando AWS Glue rastreadores e avaliar a qualidade dos dados nas tabelas do Iceberg por meio do recurso Qualidade de dados. AWS Glue O AWS Glue Data Catalog também suporta a coleta de estatísticas de colunas, o cálculo e a atualização do número de valores distintos (NDVs) para cada coluna nas tabelas do Iceberg e otimizações automáticas de tabelas (compactação, retenção de instantâneos, exclusão de arquivos órfãos). AWS Glue também oferece suporte a integrações sem ETL de uma lista de aplicativos Serviços da AWS e de terceiros em tabelas Iceberg.
-
O Amazon Data Firehose é um serviço totalmente gerenciado para fornecer dados de streaming em tempo real para destinos como Amazon S3, Amazon Redshift, Amazon OpenSearch Service, OpenSearch Amazon Serverless, Splunk, Apache Iceberg e quaisquer endpoints HTTP ou HTTP personalizados de propriedade de provedores de serviços terceirizados compatíveis, incluindo Datadog, Dynatrace, MongoDB, New Relic, Coralogix, e elástico. LogicMonitor Com o Firehose, você não precisa criar aplicativos nem gerenciar recursos. Configure os produtores de dados para enviar dados ao Firehose e ele entregará automaticamente os dados ao destino especificado. Você também pode configurar o Firehose para transformar os dados antes de entregá-los.
-
O Amazon Managed Service para Apache Flink é um serviço totalmente gerenciado da Amazon que permite usar um aplicativo Apache Flink para processar dados de streaming. Ele suporta leitura e gravação em tabelas Iceberg e permite processamento e análise de dados em tempo real.
-
O Amazon SageMaker AI suporta o armazenamento de conjuntos de recursos na Amazon SageMaker AI Feature Store usando o formato Iceberg.
-
AWS Lake Formationfornece permissões de controle de acesso gerais e refinadas para acessar dados, incluindo tabelas Iceberg consumidas pelo Athena ou pelo Amazon Redshift. Para saber mais sobre o suporte de permissões para tabelas Iceberg, consulte a documentação do Lake Formation.
AWS tem uma ampla variedade de serviços que oferecem suporte ao Iceberg, mas cobrir todos esses serviços está além do escopo deste guia. As seções a seguir abordam o Spark (streaming estruturado e em lote) no Amazon EMR AWS Glue e também no Athena SQL. A seção a seguir fornece uma visão rápida do suporte do Iceberg no Athena SQL.
