As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Monitoramento do sistema operacional
Uma instância de banco de dados no Amazon RDS para MySQL ou MariaDB é executada no sistema operacional Linux, que usa recursos subjacentes do sistema: CPU, memória, rede e armazenamento.
MySQL [(none)]> SHOW variables LIKE 'version%'; +-------------------------+---------------------+ | Variable_name | Value | +-------------------------+---------------------+ | version | 8.0.28 | | version_comment | Source distribution | | version_compile_machine | aarch64 | | version_compile_os | Linux | | version_compile_zlib | 1.2.11 | +-------------------------+---------------------+ 5 rows in set (0.00 sec)
A performance geral do banco de dados e do sistema operacional subjacente depende muito da utilização dos recursos do sistema. Por exemplo, a CPU é o componente chave para a performance do sistema, pois executa as instruções do software do banco de dados e gerencia outros recursos do sistema. Se a CPU for superutilizada (ou seja, se a carga exigir mais potência de CPU do que a provisionada para sua instância de banco de dados), esse problema afetará a performance e a estabilidade do seu banco de dados e, consequentemente, da sua aplicação.
O mecanismo de banco de dados aloca e libera memória dinamicamente. Quando não há memória suficiente na RAM para fazer o trabalho atual, o sistema grava páginas de memória na memória swap, que reside no disco. Como o disco é muito mais lento que a memória, mesmo que seja baseado na tecnologia SSD NVMe, a alocação excessiva de memória leva à degradação da performance. A alta utilização da memória causa maior latência das respostas do banco de dados, porque o tamanho de um arquivo de paginação aumenta para suportar memória adicional. Se a alocação de memória for tão alta que esgote tanto a RAM quanto os espaços de memória swap, o serviço de banco de dados poderá ficar indisponível e os usuários poderão observar erros como [ERROR] mysqld: Out of memory (Needed xyz
bytes).
Os sistemas de gerenciamento de banco de dados MySQL e MariaDB utilizam o subsistema de armazenamento, que consiste em discos que armazenam estruturas em discoOS error code 28: No space left on
device podem causar indisponibilidade e corrupção do banco de dados.
O Amazon RDS fornece métricas em tempo real para o sistema operacional em que sua instância de banco de dados é executada. O Amazon RDS publica automaticamente um conjunto de métricas do sistema operacional no CloudWatch. Essas métricas estão disponíveis para exibição e análise no console do Amazon RDS e nos painéis do CloudWatch, e você pode definir alarmes nas métricas selecionadas no CloudWatch. Os exemplos incluem:
-
CPUUtilization: o percentual de utilização da CPU. -
BinLogDiskUsage: o volume do espaço em disco ocupado por logs binários. -
FreeableMemory: a quantidade de memória de acesso aleatório disponível. Isso representa o valor do campoMemAvailablede/proc/meminfo. -
ReadIOPS: o número médio de operações E/S de leitura de disco por segundo. -
WriteThroughput: o número médio de bytes gravados no disco por segundo para o armazenamento local. -
NetworkTransmitThroughput: o tráfego de rede de saída no nó do banco de dados, que combina o tráfego de banco de dados e o tráfego do Amazon RDS usado para monitoramento e replicação.
Para obter uma referência completa de todas as métricas publicadas pelo Amazon RDS no CloudWatch, consulte as métricas do Amazon CloudWatch para o Amazon RDS na documentação do Amazon RDS.
O gráfico a seguir mostra exemplos de métricas do CloudWatch para o Amazon RDS que são exibidas no console do Amazon RDS.
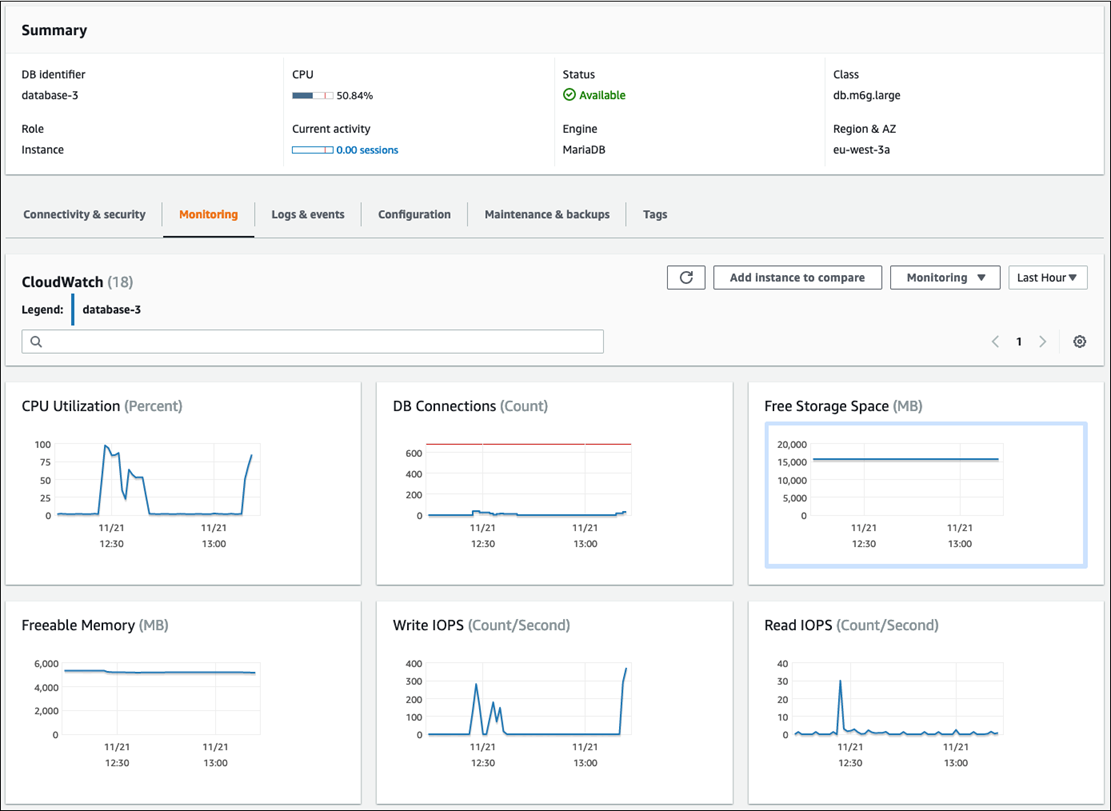
O gráfico a seguir mostra métricas semelhantes exibidas no painel do CloudWatch.
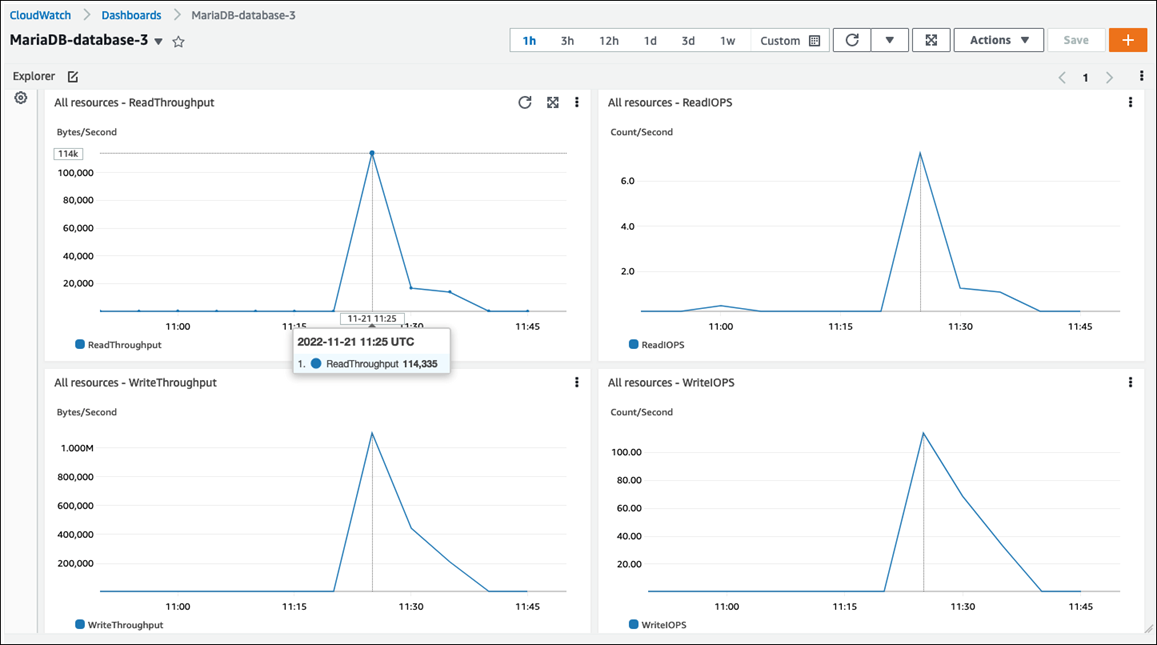
O outro conjunto de métricas do sistema operacional é coletado pelo Monitoramento Aprimorado para Amazon RDS. Essa ferramenta oferece uma visibilidade mais profunda da integridade de suas instâncias de banco de dados do Amazon RDS para MariaDB e Amazon RDS para MySQL, fornecendo métricas do sistema em tempo real e informações sobre o processo do sistema operacional. Quando você habilita o Monitoramento Aprimorado em sua instância de banco de dados e define a granularidade desejada, a ferramenta coleta as métricas do sistema operacional e as informações do processo, que você pode exibir e analisar no console do Amazon RDS, conforme mostrado na tela a seguir.
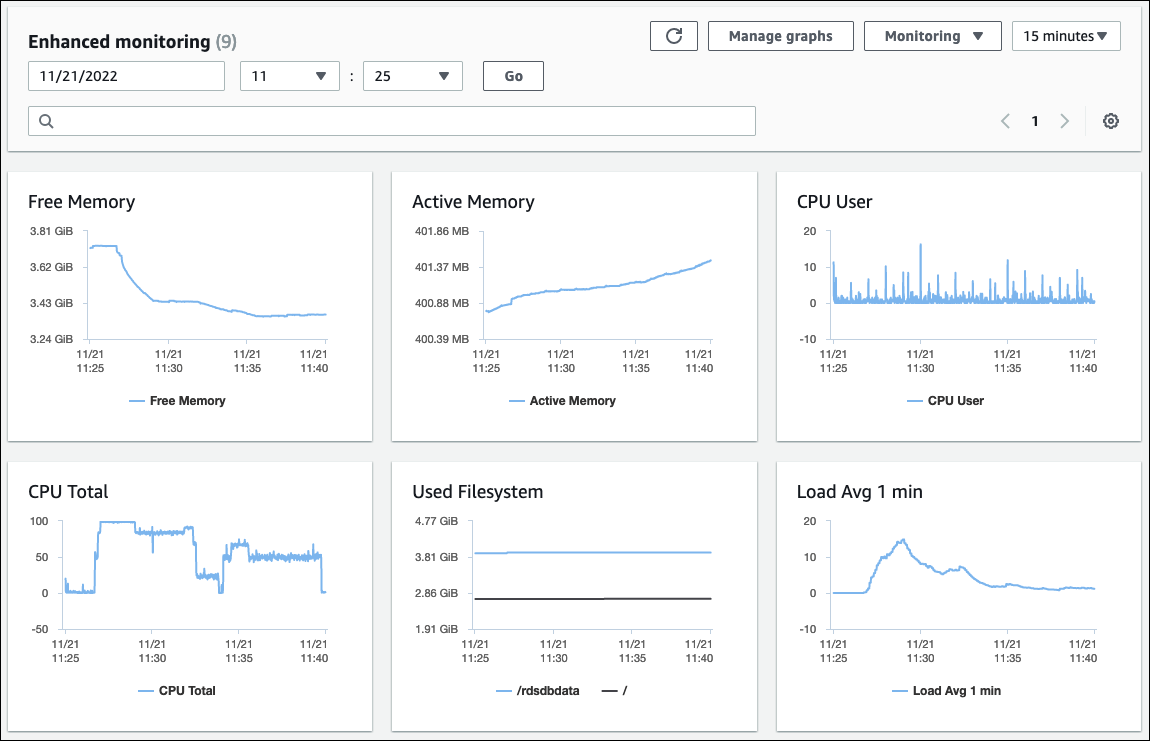
Algumas das principais métricas fornecidas pelo Monitoramento Aprimorado são:
-
cpuUtilization.total: a porcentagem total da CPU em uso. -
cpuUtilization.user: a porcentagem de CPU em uso por programas do usuário. -
memory.active: a quantidade de memória atribuída, em kilobytes. -
memory.cached: a quantidade de memória utilizada para o armazenamento em cache da E/S baseada no sistema de arquivos. -
loadAverageMinute.one: o número de processos que solicitaram tempo de CPU no último minuto.
Para obter uma lista completa de métricas, consulte as Métricas do sistema operacional no Monitoramento Aprimorado na documentação do Amazon RDS.
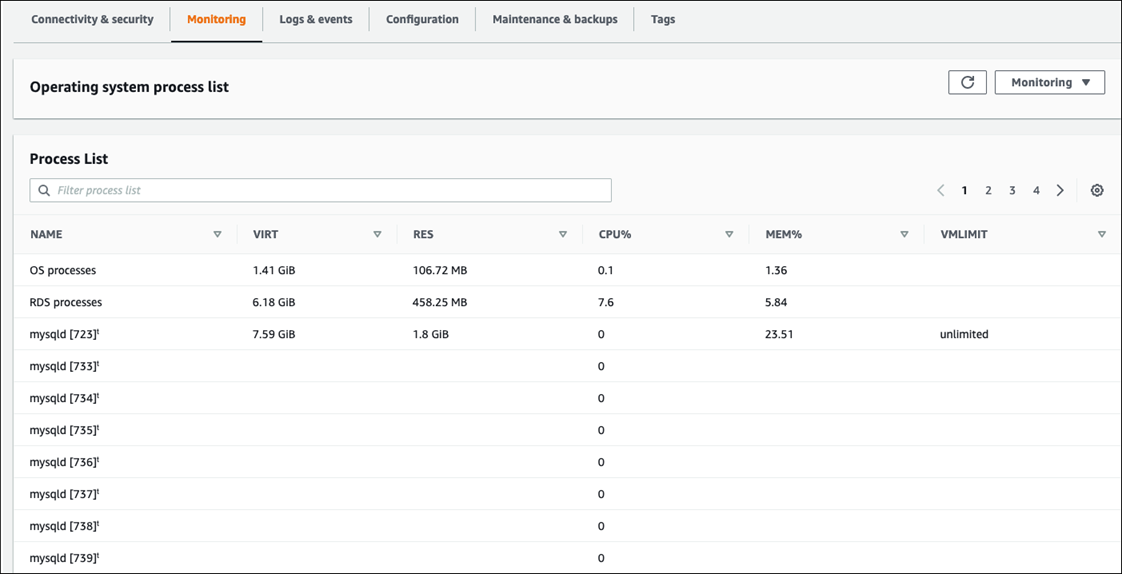
No console do Amazon RDS, a lista de processos do sistema operacional fornece detalhes de cada processo que está sendo executado na sua instância de banco de dados. A lista está organizada em três seções:
-
Processos do sistema operacional: esta seção representa um resumo agregado de todos os processos do kernel e do sistema. Esses processos geralmente têm impacto mínimo na performance do banco de dados.
-
Processos do RDS: esta seção representa um resumo dos processos necessários da AWS para oferecer suporte a uma instância de banco de dados do Amazon RDS. Por exemplo, inclui o agente de gerenciamento do Amazon RDS, processos de monitoramento e diagnóstico e processos similares.
-
Processos secundários do RDS: esta seção representa um resumo dos processos do Amazon RDS que oferecem suporte à instância de banco de dados, nesse caso, o processo
mysqlde seus threads. Os threads domysqldaparecem aninhados abaixo do processo principal domysqld.
A ilustração de tela a seguir mostra a lista de processos do sistema operacional no console do Amazon RDS.
O Amazon RDS entrega as métricas do Monitoramento Aprimorado à sua conta do Amazon CloudWatch Logs. Os dados de monitoramento que são mostrados no console do Amazon RDS são recuperados do CloudWatch Logs. Você também pode recuperar as métricas para uma instância de banco de dados como um fluxo de logs do CloudWatch Logs. Essas métricas são armazenadas no formato JSON. É possível consumir o resultado do JSON de monitoramento avançado do CloudWatch Logs em um sistema de monitoramento de sua escolha.
Para exibir grafos no painel do CloudWatch e criar alarmes que iniciarão uma ação se uma métrica ultrapassar o limite definido, você deve criar filtros de métricas no CloudWatch do CloudWatch Logs. Para obter instruções detalhadas, consulte o artigo do AWS re:Post
O exemplo a seguir ilustra a métrica personalizada CPU.User no namespace Custom/RDS. Essa métrica personalizada é criada filtrando a métrica cpuUtilization.user do Monitoramento Aprimorado do CloudWatch Logs.
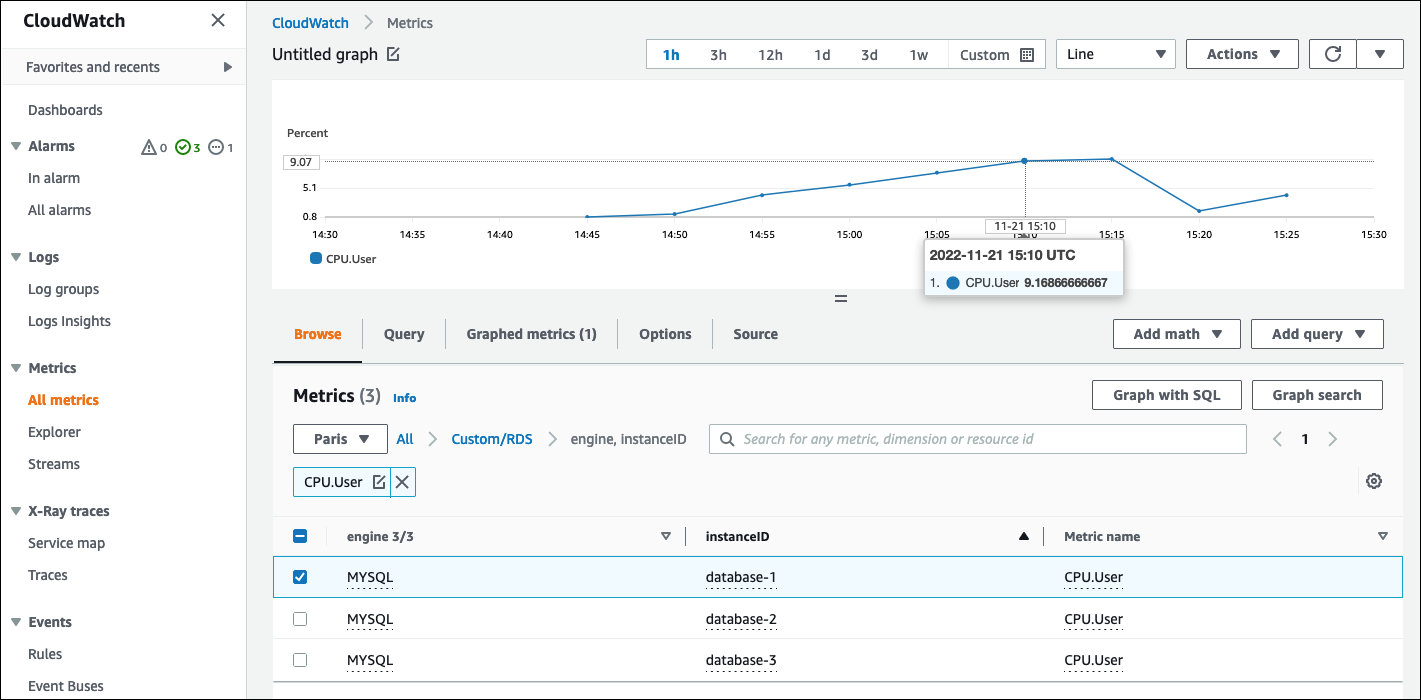
Quando a métrica está disponível no repositório do CloudWatch, você pode exibi-la e analisá-la nos painéis do CloudWatch, aplicar mais operações matemáticas e de consulta e definir um alarme para monitorar essa métrica específica e gerar alertas se os valores observados não estiverem de acordo com as condições de alarme definidas.
