As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Projetando arquiteturas de IA sem servidor
Traduzir os princípios da IA sem servidor em sistemas do mundo real requer uma arquitetura cuidadosa. O objetivo é integrar tubulações fracamente acopladas Serviços da AWS em tubulações modulares e inteligentes que escalam elasticamente e respondem em tempo real.
Esta seção fornece orientação prescritiva sobre como montar sistemas de IA nativos da nuvem usando serviços AWS sem servidor, incluindo orquestração generativa de IA, inferência em tempo real e computação de ponta. Cada padrão arquitetônico corresponde a um caso de uso corporativo comum, garantindo relevância e aplicabilidade.
Nesta seção
Padrões básicos de arquitetura
Em uma arquitetura tradicional de aplicativos orientada a eventos, o sistema é estruturado em quatro camadas lógicas que separam as preocupações e, ao mesmo tempo, permitem escalabilidade e capacidade de resposta. Na parte superior, a camada do aplicativo manipula as interações do usuário e os eventos da interface do usuário, geralmente acionando eventos específicos do domínio no sistema. APIs Abaixo dela, a camada de orquestração gerencia fluxos de trabalho, regras de negócios e sequenciamento de eventos usando ferramentas como máquinas de estado ou fluxos de trabalho sem servidor. A camada de serviço contém funções ou microsserviços modulares e reutilizáveis que respondem a eventos e executam a lógica central. Na base, a camada de dados é responsável pela persistência, streaming e fornecimento de eventos. A camada de dados utiliza serviços como bancos de dados, armazenamentos de objetos ou registros de eventos para emitir e consumir eventos de alteração. Juntas, essas camadas oferecem suporte a uma arquitetura fracamente acoplada, escalável e de fácil manutenção, na qual os eventos direcionam o fluxo em toda a pilha.
Os sistemas de IA sem servidor também são compostos por serviços pouco acoplados e orientados por eventos que podem ser escalados, evoluídos e recuperados de forma independente. Para projetar esses sistemas com consistência e escalabilidade, é essencial ver a arquitetura como cinco camadas distintas. Cada camada tem uma função específica e é mapeada diretamente para uma finalidade Serviços da AWS específica. O diagrama a seguir mostra cada camada.
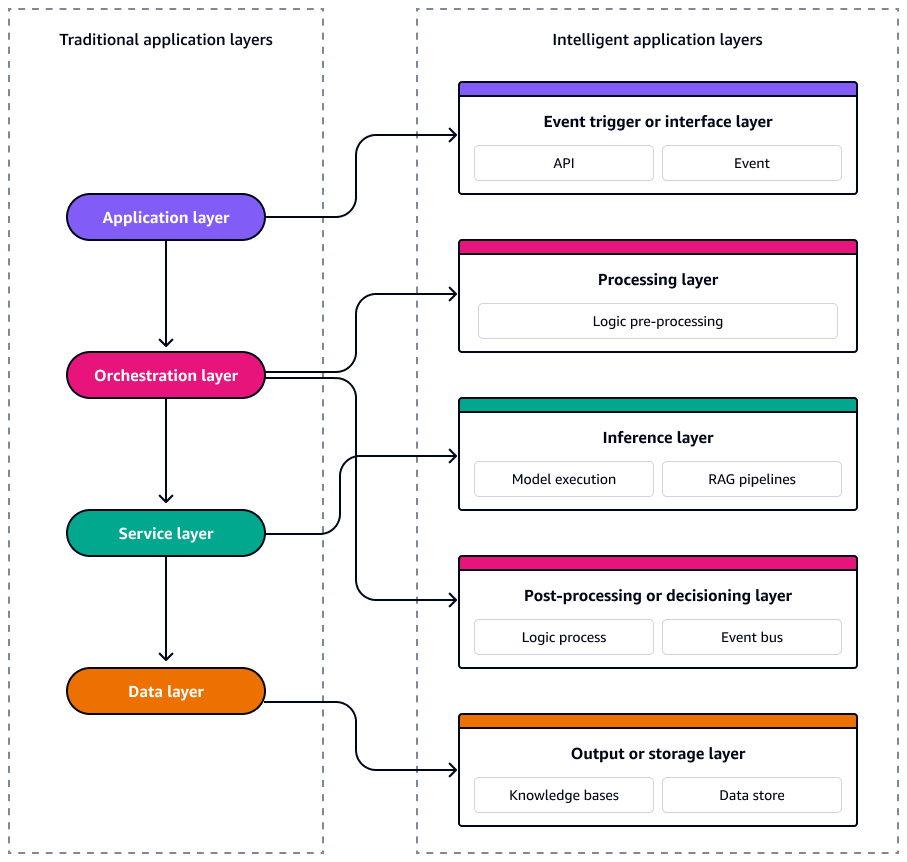
Essas cinco camadas formam o modelo para a criação de aplicativos inteligentes e orientados a eventos que sejam resilientes, observáveis e otimizados em termos de custo e desempenho.
Acionador de eventos ou camada de interface
O gatilho do evento ou a camada de interface é o ponto de entrada para seu sistema de IA sem servidor. Ele captura interações do usuário, eventos do sistema ou alterações de dados e os emite como eventos estruturados na arquitetura. Ele permite a orquestração assíncrona e separa as entradas upstream da lógica de processamento downstream.
As responsabilidades da camada de gatilho de eventos incluem o seguinte:
-
Capture ações do usuário, como cliques, mensagens e uploads
-
Emitir eventos de domínio ou notificações de alteração
-
Normalize os dados recebidos para consumo posterior
Serviços da AWS que são comumente usados com essa camada incluem o seguinte:
-
O Amazon API Gateway aceita a entrada do usuário por meio de REST ou WebSocket APIs.
-
A Amazon EventBridge roteia eventos internos ou externos usando um registro de esquema.
-
O Amazon Simple Storage Service (Amazon S3) é acionado na criação de objetos, como uploads de documentos e arquivos de mídia.
-
O Amazon Kinesis e o Amazon Managed Streaming for Apache Kafka (Amazon MSK) ingerem eventos de streaming em grande escala.
Exemplo: uma solicitação de suporte ao cliente enviada por meio de um formulário da web aciona uma EventBridge regra, iniciando o fluxo de trabalho de um agente Amazon Bedrock a jusante.
Camada de processamento
A camada de processamento transforma ou enriquece os dados antes de passá-los para o modelo de IA. Ele lida com tarefas de pré-processamento, como validação de entrada, formatação, marcação de metadados, detecção de idioma e enriquecimento de dados usando tabelas de pesquisa ou externas. APIs
As responsabilidades da camada de processamento incluem o seguinte:
-
Valide e normalize a entrada bruta.
-
Extraia ou injete metadados, como idioma e ID do cliente.
-
Lógica de rota ou ramificação com base em atributos de dados.
Serviços da AWS que são comumente usados com essa camada incluem o seguinte:
-
AWS Lambdaé uma computação sem estado e orientada por eventos para lógica de transformação.
-
AWS Step Functionsorquestre tarefas de pré-processamento em várias etapas.
-
O Amazon Comprehend fornece detecção de linguagem, reconhecimento de entidades ou análise de sentimentos como parte do pré-processamento.
Exemplo: os pedidos de seguro enviados são digitalizados em busca de informações de identificação pessoal (PII) e do tipo de documento usando o Lambda e o Amazon Comprehend antes do resumo da IA.
Camada de inferência
Como núcleo do sistema de IA, a camada de inferência executa a inferência de aprendizado de máquina (ML) ou modelo básico (FM). Ela pode incluir um ou mais modelos — generativos, preditivos ou de classificação — dependendo do caso de uso.
As responsabilidades da camada de inferência incluem o seguinte:
-
Execute a inferência do modelo ML ou FM.
-
Gere previsões, classificações ou conteúdo gerado.
-
Integre o contexto de Geração Aumentada de Recuperação (RAG) quando aplicável.
Serviços da AWS que são comumente usados com essa camada incluem o seguinte:
-
O Amazon Bedrock fornece inferência de modelos básicos (texto, imagem, multimodal) de fornecedores como Anthropic, Amazon (para Amazon Nova) e. Meta Mistral
-
O Amazon SageMaker Serverless Inference executa modelos de ML personalizados em grande escala.
-
O Amazon Bedrock Agents fornece raciocínio baseado em modelo de linguagem grande (LLM) e orquestração baseada em metas.
Exemplo: um agente do Amazon Bedrock usa o Amazon Nova Pro para gerar uma resposta a uma consulta de suporte complexa, com base no conhecimento corporativo usando o RAG.
Camada de pós-processamento ou tomada de decisão
A camada de pós-processamento ou tomada de decisão refina ou atua sobre os resultados da inferência. Ele pode formatar a resposta, registrar a saída, invocar ações posteriores ou tomar decisões com base na confiança do modelo, nas classificações ou nas regras de negócios externas.
As responsabilidades da camada de pós-processamento ou tomada de decisão incluem o seguinte:
-
Formate a saída AI para sistemas ou monitores posteriores.
-
Acione a lógica condicional ou a chamada APIs.
-
Encaminhe dados enriquecidos para armazenamento ou análise.
Serviços da AWS que são comumente usados com essa camada incluem o seguinte:
-
O Lambda pode formatar resultados, aplicar transformações ou fazer chamadas. APIs
-
O Amazon Simple Notification Service (Amazon SNS) EventBridge emite outros eventos com base na saída do modelo.
-
O Step Functions aplica a lógica de cadeia, por exemplo, escale o caso de suporte se o sentimento for igual a “irritado”.
Exemplo: uma recomendação de produto de um LLM é validada de forma cruzada em relação ao inventário em tempo real usando uma função Lambda antes que a recomendação seja enviada ao usuário.
Camada de saída ou armazenamento
Finalmente, a camada de saída ou armazenamento lida com a entrega de resultados aos usuários ou sistemas e persiste nas saídas estruturadas para auditoria, análise ou ciclos de feedback.
As responsabilidades da camada de saída ou armazenamento incluem o seguinte:
-
Retorne os resultados da IA aos usuários finais por meio de APIs ou UIs.
-
Mantenha as saídas e os registros estruturados.
-
Alimente lagos de dados ou pipelines de reciclagem.
Serviços da AWS que são comumente usados com essa camada incluem o seguinte:
-
O Amazon S3 armazena registros de inferência, resumos ou conteúdo gerado.
-
O Amazon DynamoDB fornece armazenamento de valores-chave de baixa latência para saída de IA específica da sessão.
-
O Amazon OpenSearch Service fornece resultados estruturados de índice para pesquisa e análise.
-
API Gateway e WebSocket APIs fornece respostas de retorno para clientes front-end ou móveis.
Exemplo: um resumo de um documento legal, gerado pelo Amazon Bedrock, é armazenado no Amazon S3 e indexado OpenSearch no Service para permitir a pesquisa semântica corporativa.
Considerações de design em todas as camadas
As seguintes considerações e padrões principais de design se aplicam a todas as camadas arquitetônicas:
-
Resiliência — Cada camada deve falhar e tentar novamente de forma independente (por exemplo, filas de letras mortas () no Lambda)DLQs.
-
Observabilidade — emita registros, rastreamentos e métricas estruturados de cada estágio para a Amazon CloudWatch para detectar desvios comportamentais.
-
Segurança — Use a separação de funções AWS Identity and Access Management(IAM) e AWS Key Management Service(AWS KMS) para criptografia de dados em todas as camadas.
-
Otimização de custos — Use a execução assíncrona sempre que possível e escolha modelos do tamanho certo.
-
Extensibilidade — O design modular permite que os serviços sejam substituídos ou atualizados de forma independente.
Essas cinco camadas formam uma arquitetura de referência modular, escalável e sem servidor para cargas de trabalho baseadas em IA. AWS Cada camada pode ser desenvolvida, implantada e otimizada de forma independente, permitindo iteração rápida, excelência operacional e separação clara de preocupações em todos os domínios de negócios.
Ao usar esse padrão em camadas como estrutura de design, as empresas podem padronizar sua abordagem à IA sem servidor e acelerar o caminho do protótipo à produção com confiança.
Considerações sobre design de arquitetura
A arquitetura de IA sem servidor ativada AWS permite que você crie aplicativos inteligentes que são modulares, escaláveis e de nível de produção. Quer você implante modelos na borda, orquestre pipelines de inferência de várias etapas ou crie assistentes de IA generativos, você Serviços da AWS pode impulsionar a próxima geração de aplicativos nativos de IA.
Ao projetar uma arquitetura de IA sem servidor, tenha em mente os seguintes focos principais de design e as melhores práticas:
-
Segurança — use funções refinadas do IAM, criptografe solicitações e saídas e restrinja o acesso à API.
-
Observabilidade — registros integrados CloudWatch AWS X-Ray e personalizados para cada estágio do pipeline.
-
Escalabilidade — Use somente componentes sem servidor, como Lambda, Amazon Bedrock e Serverless Inference. SageMaker
-
Latência — Aproveite o Lambda @Edge, a simultaneidade provisionada ou a inferência assíncrona.
-
Modularidade — Projete pipelines usando acionadores de eventos e funções isoladas para cada tarefa.
-
Reutilização — Parametrize prompts, use camadas compartilhadas do Lambda e desacople a lógica usando Step Functions.
