As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Padrões de saga de encadeamento imediato
Ao reimaginar o encadeamento imediato do LLM como uma saga orientada por eventos, desbloqueamos um novo modelo operacional: os fluxos de trabalho se tornam distribuídos, recuperáveis e coordenados semanticamente entre agentes autônomos. Cada etapa de resposta rápida é reformulada como uma tarefa atômica, emitida como um evento, consumida por um agente dedicado e enriquecida com metadados contextuais.
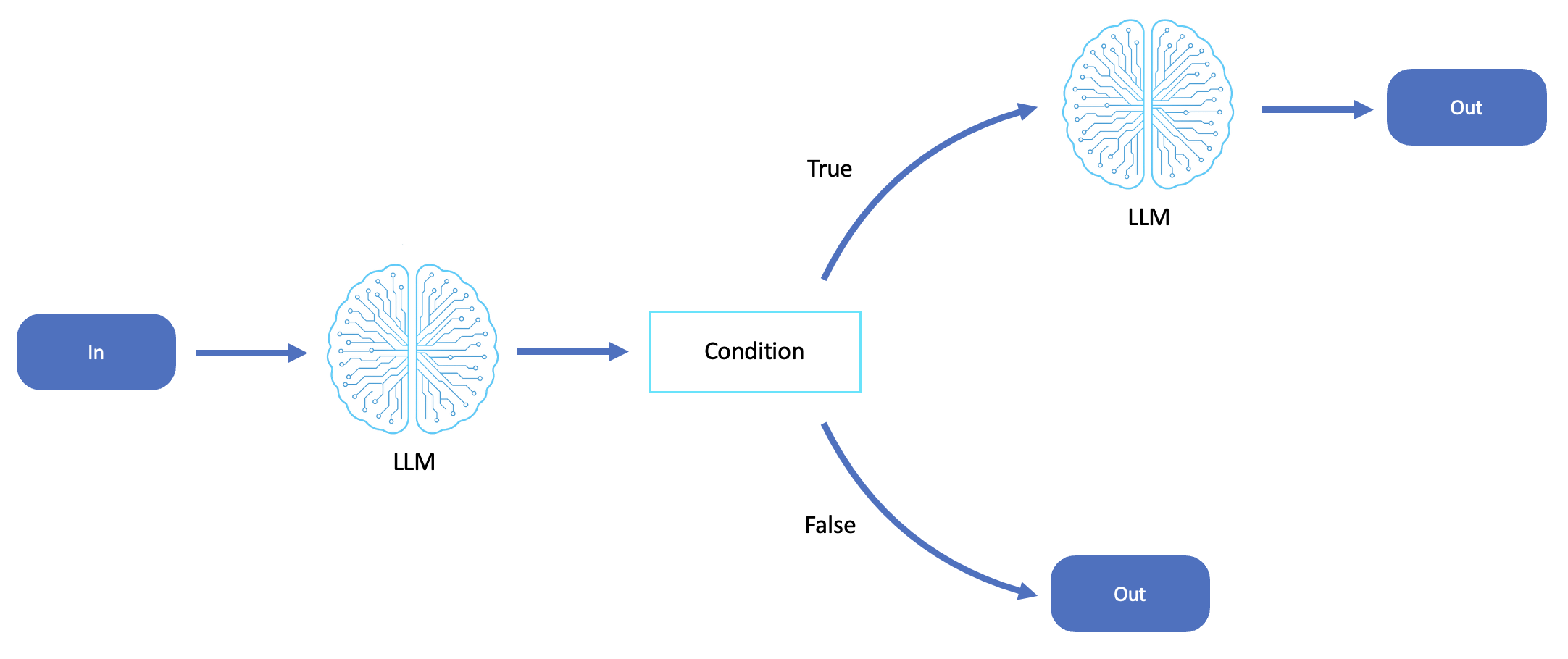
O diagrama a seguir é um exemplo do encadeamento de prompts do LLM:
Coreografia saga
O padrão coreográfico da saga é uma abordagem de implementação em sistemas distribuídos que não tem um coordenador central. Em vez disso, cada serviço ou componente publica eventos que acionam a próxima ação do fluxo de trabalho. Esse padrão é amplamente usado em sistemas distribuídos para gerenciar transações em vários serviços. Em uma saga, o sistema executa uma série de transações locais coordenadas. Se um falhar, o sistema aciona ações compensatórias para manter a consistência.
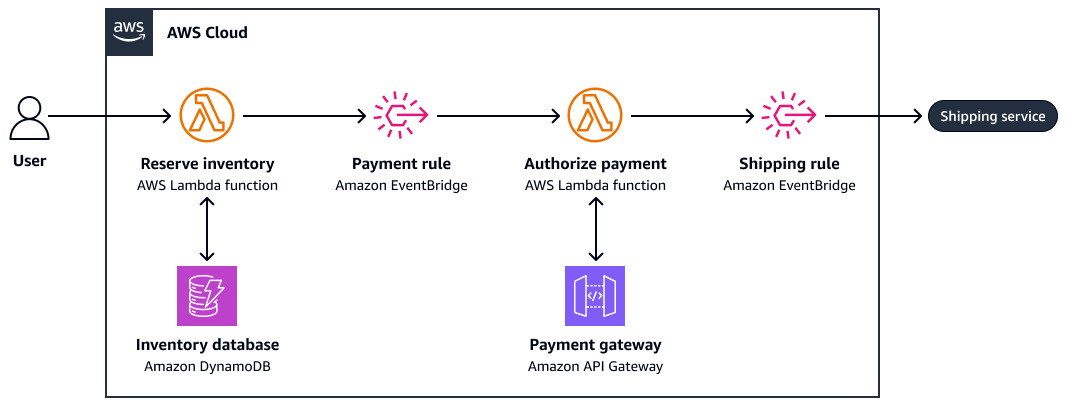
O diagrama a seguir é um exemplo de coreografia de saga:
-
Reservar inventário
-
Autorizar pagamento
-
Criar pedido de envio
Se a etapa 3 falhar, o sistema invoca ações compensatórias (por exemplo, cancelar um pagamento ou liberar o inventário).
Esse padrão é especialmente valioso em arquiteturas orientadas a eventos, nas quais os serviços são fracamente acoplados e os estados devem ser resolvidos de forma consistente ao longo do tempo, mesmo na presença de falhas parciais.
Padrão de encadeamento imediato
O encadeamento imediato se assemelha ao padrão da saga, tanto na estrutura quanto no propósito. Ele executa uma série de etapas de raciocínio que são construídas sequencialmente, preservando o contexto e permitindo reversões e revisões.
Coreografia do agente
-
O LLM interpreta uma consulta complexa do usuário e gera uma hipótese
-
LLM elabora um plano para resolver a tarefa
-
O LLM executa uma subtarefa (por exemplo, usando uma chamada de ferramenta ou recuperando conhecimento)
-
O LLM refina a saída ou revisita uma etapa anterior se considerar um resultado insatisfatório
Se um resultado intermediário apresentar falhas, o sistema poderá fazer o seguinte:
-
Repita as etapas usando uma abordagem diferente
-
Reverta para uma solicitação anterior e replaneje
-
Use um loop de avaliação (por exemplo, do padrão avaliador-otimizador) para detectar e corrigir falhas
Assim como o padrão da saga, o encadeamento imediato permite mecanismos parciais de progresso e reversão. Isso acontece por meio de refinamento iterativo e correção direcionada ao LLM, em vez de compensar as transações do banco de dados.
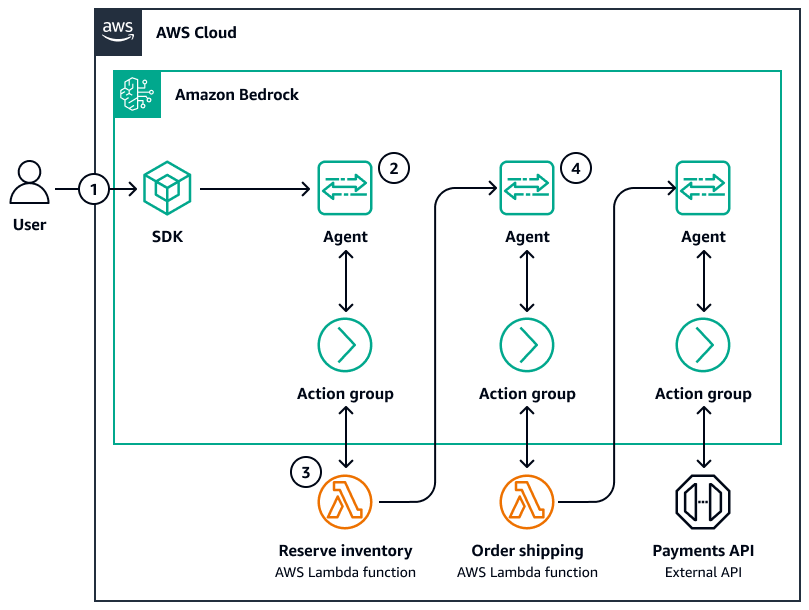
O diagrama a seguir é um exemplo de coreografia de agentes:
-
Um usuário envia uma consulta por meio de um SDK.
-
Um agente do Amazon Bedrock orquestra o raciocínio por meio do seguinte:
-
Interpretação (LLM)
-
Planejamento (LLM)
-
Execução por meio de uma ferramenta ou base de conhecimento
-
Construção da resposta
-
-
Se uma ferramenta falhar ou retornar dados insuficientes, o agente poderá replanejar ou reformular dinamicamente a tarefa.
-
A memória (por exemplo, um armazenamento vetorial de curto prazo) pode preservar seu estado em todas as etapas
Takeaways
Enquanto o padrão da saga gerencia chamadas de serviço distribuídas com lógica de compensação, o encadeamento imediato gerencia as tarefas de raciocínio com sequenciamento reflexivo e replanejamento adaptativo. Ambos os sistemas permitem progresso incremental, pontos de decisão descentralizados e recuperação de falhas, e tudo isso por meio de raciocínio informado, em vez de reversão rígida.
O encadeamento imediato introduz o raciocínio transacional, que é o equivalente cognitivo das sagas. Ou seja, cada “pensamento” é reavaliado, revisado ou abandonado como parte de um diálogo mais amplo direcionado a um objetivo.
